






 本文介绍了Hive中分区表的概念及应用,详细说明了如何通过分区提高查询效率,并提供了具体的实例操作步骤,包括创建、查询、增加和删除分区等。
本文介绍了Hive中分区表的概念及应用,详细说明了如何通过分区提高查询效率,并提供了具体的实例操作步骤,包括创建、查询、增加和删除分区等。
一、分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
分区表的应用:日志是每天放在一个文件夹中partition(分区),每个分区再划分为簇组,方便查询。
二、实例
1.根据日期对日志进行管理





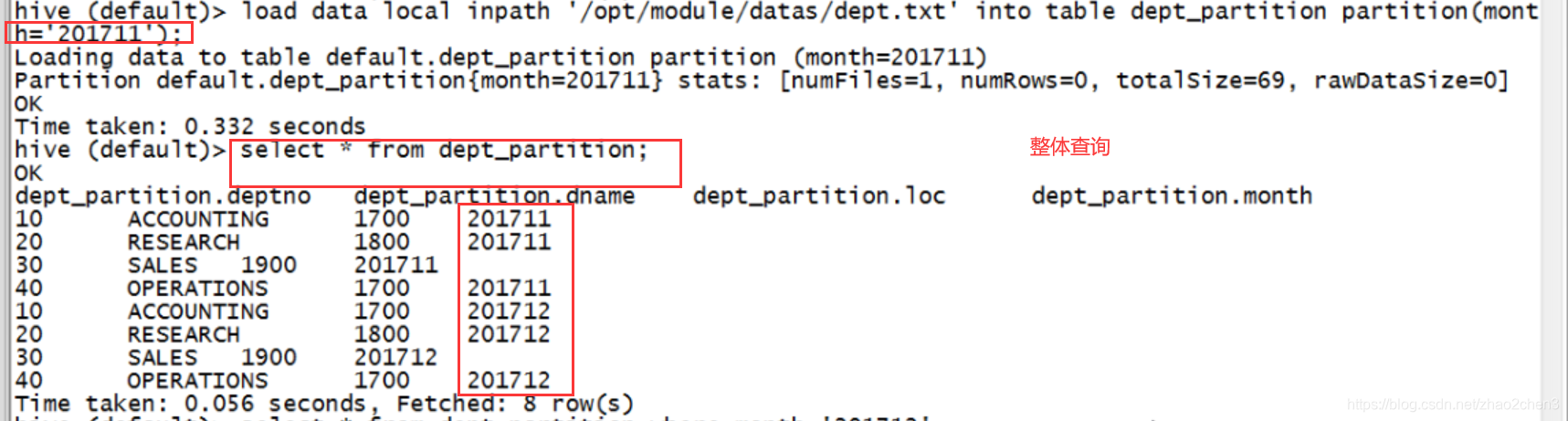
单分区查询
根据分区进行查询,大大提高了查询效率。

多分区联合查询


增加分区
增加单个分区


同时创建多个分区


删除分区
删除单个分区

同时删除多个分区

查看分区表有多少分区

查看分区表结构

创建二级分区表


查询二级分区的数据

把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
1.上传数据后修复msck repair table dept_partition2;
dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=01/day=28;
dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=01/day=28;
msck repair table dept_partition2;
select * from dept_partition2 where month='01' and day='28';

2.上传数据后添加分区alter table dept_partition2 add partition(month='01',day='30');
dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=01/day=30;
dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=01/day=30;
select * from dept_partition2 where month='01' and day='30';
alter table dept_partition2 add partition(month='01',day='30');
select * from dept_partition2 where month='01' and day='30';

3.上传数据后load数据到分区 load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition2 partition(month='01',day='31');
dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=01/day=31;
load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition2 partition(month='01',day='31');
select * from dept_partition2 where month='01' and day='31';


















 1497
1497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









