






Druid是2013年底开源出来的, 主要解决的是对实时数据以及较近时间的历史数据的多维查询提供高并发(多用户),低延时,高可靠性的问题。
Druid简介:
Druid是一个为在大数据集之上做实时统计分析而设计的开源数据存储。这个系统集合了一个面向列存储的层,一个分布式、shared-nothing的架构,和一个高级的索引结构,来达成在秒级以内对十亿行级别的表进行任意的探索分析。
互联网技术的快速增长催生了各类大体量的数据,Hadoop很大的贡献在于帮助企业将他们那些低价值的事件流数据转化为高价值的聚合数据,这适用于各种应用
但Hadoop擅长的是存储和获取大规模数据,但是它并不提供任何性能上的保证它能多快获取到数据。此外,虽然Hadoop是一个高可用的系统,但是在高并发负载下性能会下降
Hadoop是一个很好的后端、批量处理和数据仓库系统。在一个需要高并发并且保证查询性能和数据可用性的并需要提供产品级别的保证的需求,Hadoop并不能满足,因此创建了Druid,一个开源的、分布式、列存储、实时分析的数据存储。在许多方面,Druid和其他OLAP系统有很多相似之处,交互式查询系统,内存数据库(MMDB),众所周知的分布式数据存储。其中的分布式和查询模型都参考了当前的一些搜索引擎的基础架构.
druid的一些特点:
Druid是一个开源的,分布式的,列存储的,适用于实时数据分析的系统,文档详细,易于上手,Druid的一些特性总结如下;
Druid支持亚秒级的OLAP查询分析,Druid采用了列式存储/倒排索引/位图索引等关键技术,能够在亚秒级别内完成海量数据的过滤/聚合以及多位分析等操作。Druid使用Bitmap indexing加速column-store的查询速度,使用了一个叫做CONCISE的算法来对bitmap indexing进行压缩,使得生成的segments比原始文本文件小很多
Druid的高可用性和高扩展性,Druid采用分布式,SN(share-nothing)架构,管理类节点课配置HA,工作节点功能单一,不互相依赖,耦合性低,各种节点挂掉都不会使Druid停止工作,例如如果不需要streaming data ingestion完全可以忽略realtime node,这些都是的Druid在集群的管理,容灾,容错,扩容等方面变得非常容易;
实时流数据分析。区别于传统分析型数据库采用的批量导入数据进行分析的方式,Druid提供了实时流数据分析,采用LSM(Long structure merge)-Tree结构使Druid拥有极高的实时写入性能;同时实现了实时数据在亚秒级内的可视化。
丰富的数据分析功能。针对不同用户群体,Druid提供了友好的可视化界面、类SQL查询语言以及REST 查询接口。
Druid的一些“局限”:
Segment的不可修改性简化了Druid的实现,但是如果你有修改数据的需求,必须重新创建segment,而bitmap indexing的过程是比较耗时的;
Druid能接受的数据的格式相对简单,比如不能处理嵌套结构的数据
Druid使用场景:
1:适用于清洗好的记录实时录入,但不需要更新操作
2:支持宽表,不用join的方式(换句话说就是一张单表)
3:可以总结出基础的统计指标,可以用一个字段表示
4:对时区和时间维度(year、month、week、day、hour等)要求高的(甚至到分钟级别)
5:实时性很重要
6:对数据质量的敏感度不高
7:用于定位效果分析和策略决策参考
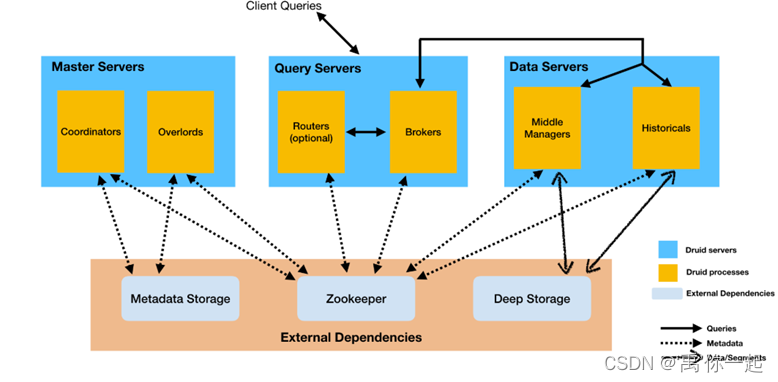
总体可以分为:四个节点 + 三个依赖
四个节点:
实时节点(Realtime Node):
实时摄入数据,对于旧的数据周期性的生成segment数据文件,上传到deep storage中
为了避免单点故障,索引服务(Indexer)的主从架构已经逐渐替代了实时节点,所以现在的实时节点,其实里面包含了很多角色:
作用:可以通过索引服务的API,写数据导入任务,用以新增、删除、合并Segment等。是一个主从架构:
统治节点(overlord):
类似于Yarn ResourceManager : 负责集群资源的管理和分配
监视数据服务器上的MiddleManager进程,将提取任务分配给MiddleManager
中间管理者(middle manager):
类似于Yarn NodeManager : 负责单个节点资源的管理和分配
新数据提取到群集中的过程。他们负责从外部数据源读取并发布新的段
苦工(peon):
类似于Yarn container :负责具体任务的执行
Peon进程是由MiddleManagers产生的任务执行引擎。
每个Peon运行一个单独的JVM,并负责执行单个任务。
Peon总是与生成它们的MiddleManager在同一主机上运行
Router(路由:可选):
可在Druid代理,统治节点和协调器之前提供统一的API网关
注:统治节点和中间管理者的通信是通过zookeeper完成的
历史节点(Historical Node):
加载已生成的segment数据文件,以供数据查询
启动或者受到协调节点通知的时候,通过druid_rules表去查找需要加载的数据,然后检查自身的本地缓存中已存在的Segment数据文件,
然后从DeepStorage中下载其他不在本地的Segment数据文件,后加载到内存!!!再提供查询。
查询节点(Broker Node):
对外提供数据查询服务,并同时从实时节点与历史节点查询数据,合并后返回给调用方
缓存:
外部:第三方的一些缓存系统
内部:在历史节点或者查询节点做缓存
协调节点(Coodinator Node):
负责历史节点的数据负载均衡,以及通过规则(Rule)管理数据的生命周期
①通过从MySQL读取元数据信息,来决定深度存储上哪些数据段应该在那个历史节点中被加载,②通过ZK感知历史节点,历史节点增加,会自动分配相关的Segment,历史节点删除,会将原本在这台节点上的Segment分配给其他的历史节点
注:Coordinator是定期运行的,并且运行间隔可以通过配置参数配置

















 4493
4493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









