







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、实验环境
Ubuntu18.04
Spark 2.4.0
Python 3.6.5
二、实验流程
1.PySpark交互式编程
在 spark下创建文件夹sparksqldata,将data01.txt上传到sparksqldata下:
cd /usr/local/spark
mkdir sparksqldata
cd /bin
./pyspark(1)统计学生人数(即文件的行数)
lines = sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt")
res = lines.map(lambda x:x.split(",")).map(lambda x: x[0]) //获取每行数据的第1列
distinct_res = res.distinct() //去重操作
distinct_res.count()//取元素总个数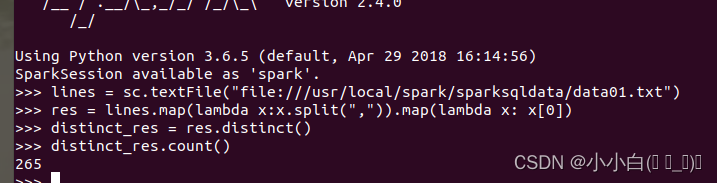
(2)统计开设课程总数
lines = sc.textFile("file:///usr/local/spark/sparksqldata/data01.txt")
df = lines.map(lambda x:x.split(",")).map(lambda x:x[1])
df1 = df.distinct()
df1.count() 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









