







 本文详细解析了HashMap的工作原理,包括put方法、构造函数、resize机制,以及为何在多线程环境下会出现数据不一致和死循环等问题。同时探讨了HashMap与ConcurrentHashMap在不同Java版本中的线程安全性差异。
本文详细解析了HashMap的工作原理,包括put方法、构造函数、resize机制,以及为何在多线程环境下会出现数据不一致和死循环等问题。同时探讨了HashMap与ConcurrentHashMap在不同Java版本中的线程安全性差异。
目录
HashMap在面试的时候会问哪些问题?
比如HashMap与HashTable的区别,HashMap的默认容量、扩容因子、扩容机制、底层的数据结构,以及HashMap底层在Java7与Java8中的区别,为何要将数组+链表改为数组+链表+红黑树,最后还要说一下HashMap线程不安全的场景,由此会延伸至线程安全的ConcurrentHashMap,然后就要讲ConcurrentHashMap的底层结构,以及ConcurrentHashMap在Java7与Java8中是如何保证线程安全的,由此又会延伸至CAS算法……总之面试都是环环相扣的,不会只问你单个知识点。
1put方法
①如果hash定位( (n - 1) & hash)到的数组位置没有元素,就直接插入。
②如果有元素就和要插入的key比较,如果key相同就直接覆盖,
如果key不相同,就判断p是否是一个树节点,如果是就调用e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)将元素添加进入。
如果不是就遍历链表插入,如果插入后链表长度大于8转化为红黑树。
2constructor
// 指定“容量大小”和“加载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
3resize
没超过最大值就是2倍
4HashMap为什么线程不安全
1、put的时候导致的多线程数据不一致。
这个问题比较好想象,比如有两个线程A和B,首先A希望插入一个key-value对到HashMap中,首先计算记录所要落到的桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的桶索引和线程B要插入的记录计算出来的桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
2、另外一个比较明显的线程不安全的问题是HashMap的get操作可能因为resize而引起死循环(cpu100%),具体分析如下:
下面的代码是resize的核心内容:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
这个方法的功能是将原来的记录重新计算在新桶的位置,然后迁移过去。
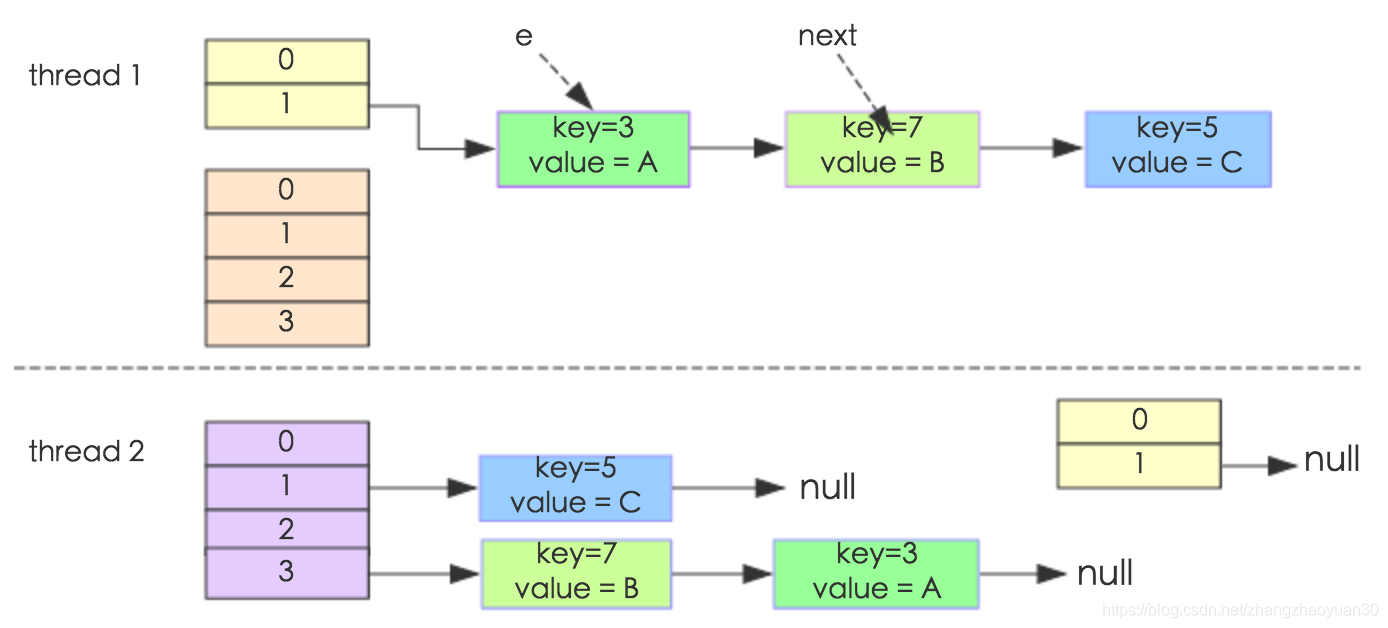
多线程HashMap的resize
我们假设有两个线程同时需要执行resize操作,我们原来的桶数量为2,记录数为3,需要resize桶到4,原来的记录分别为:[3,A],[7,B],[5,C],在原来的map里面,我们发现这三个entry都落到了第二个桶里面。
假设线程thread1执行到了transfer方法的Entry next = e.next这一句,然后时间片用完了,此时的e = [3,A], next = [7,B]。线程thread2被调度执行并且顺利完成了resize操作,需要注意的是,此时的[7,B]的next为[3,A]。此时线程thread1重新被调度运行,此时的thread1持有的引用是已经被thread2 resize之后的结果。线程thread1首先将[3,A]迁移到新的数组上,然后再处理[7,B],而[7,B]被链接到了[3,A]的后面,处理完[7,B]之后,就需要处理[7,B]的next了啊,而通过thread2的resize之后,[7,B]的next变为了[3,A],此时,[3,A]和[7,B]形成了环形链表,在get的时候,如果get的key的桶索引和[3,A]和[7,B]一样,那么就会陷入死循环。
如果在取链表的时候从头开始取(现在是从尾部开始取)的话,则可以保证节点之间的顺序,那样就不存在这样的问题了。
综合上面两点,可以说明HashMap是线程不安全的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









