







目录
1.数据分布
1.1数据分区规则
- 节点取余

翻倍扩容迁移50%
- 一致性哈希


- 虚拟槽

slot=CRC16(key)&16383

1.2集群功能限制
![]()
![]()
3)集群模式下只能使用一个数据库空间,即db0
1.3搭建集群
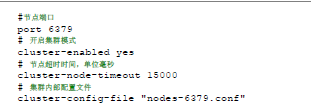
- 节点握手
![]()
![]()
![]()
- 分配槽
![]()
- 从节点
![]()
![]()
注:笔者用的redis5.0已自带redis-trib.rb,较低版本可能需要自己安装。
集群完整性检查:
![]()
3.节点通信
在分布式存储中需要提供维护节点元数据信息的机制,所谓元数据是指:节点负责哪些数据,是否出现故障等状态信息。
常见的元数据维护方式分为:集中式和P2P方式。Redis集群采用P2P的Gossip(流言)协议,Gossip协议工作原理就是节点彼此不断通信交换信息,一段时间后所有的节点都会知道集群完整的信息
3.1 Gossip消息
- ping消息:用于检测节点是否在线和交换彼此状态信息。ping消息发送封装了自身节点和部分其他节点的状态数据
- pong消息:当接收到ping、meet消息时,作为响应消息回复给发送方确认消息正常通信。pong消息内部封装了自身状态数据。节点也可以向集群内广播自身的pong消息来通知整个集群对自身状态进行更新。
- meet消息:用于通知新节点加入
- fail消息:当节点判定集群内另一个节点下线时,会向集群内广播一个fail消息,其他节点接收到fail消息之后把对应节点更新为下线状态
4.集群伸缩
4.1.扩容
- 加入集群
![]()
- 分配槽
![]()
- 检查槽之间的均衡性
![]()
- 添加从节点
![]()
4.2收缩
- 迁移槽
![]()

- 忘记节点

5.请求路由
5.1请求重定向
在集群模式下,Redis接收任何键相关命令时首先计算键对应的槽,再根据槽找出所对应的节点,如果节点是自身,则处理键命令;否则回复MOVED重定向错误,通知客户端请求正确的节点
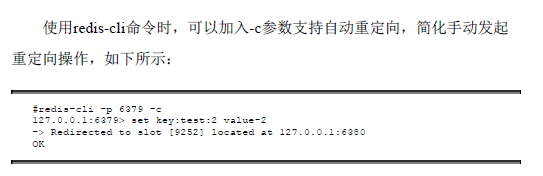

Dummy(傀儡)客户端:依赖于MOVE机制
- 代码实现简单,对客户端协议影响较小,只需要根据重定向信息再次发送请求即可。
- 但是它的弊端很明显,每次执行键命令前都要到Redis上进行重定向才能找到要执行命令的节点,额外增加了IO开销
5.2Smart客户端
1)在JedisCluster初始化时会选择一个运行节点,初始化槽和节点映射关系,使用cluster slots命令完成
2)JedisCluster解析cluster slots结果缓存在本地,并为每个节点创建唯一的JedisPool连接池。映射关系在JedisClusterInfoCache类


5.3ASK重定向
当一个slot数据从源节点迁移到目标节点时,期间可能出现一部分数据在源节点,而另一部分在目标节点

6.故障转移
6.1故障发现
主观下线:集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong消息作为响应。如果在cluster-node-timeout时间内通信一直失败,则发送节点会认为接收节点存在故障,把接收节点标记为主观下线(pfail)状态
客观下线:当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播。ping/pong消息的消息体会携带集群1/10的其他节点状态数据,当接受节点发现消息体中含有主观下线的节点状态时,会在本地找到故障节点的ClusterNode结构,保存到下线报告链表中。通过Gossip消息传播,集群内节点不断收集到故障节点的下线报告。当半数以上持有槽的主节点都标记某个节点是主观下线时。触发客观下线流程。
- 为什么必须是负责槽的主节点参与故障发现决策?因为集群模式下只有处理槽的主节点才负责读写请求和集群槽等关键信息维护,而从节点只进行主节点数据和状态信息的复制。
- 为什么半数以上处理槽的主节点?必须半数以上是为了应对网络分区等原因造成的集群分割情况,被分割的小集群因为无法完成从主观下线到客观下线这一关键过程,从而防止小集群完成故障转移之后继续对外提供服务。
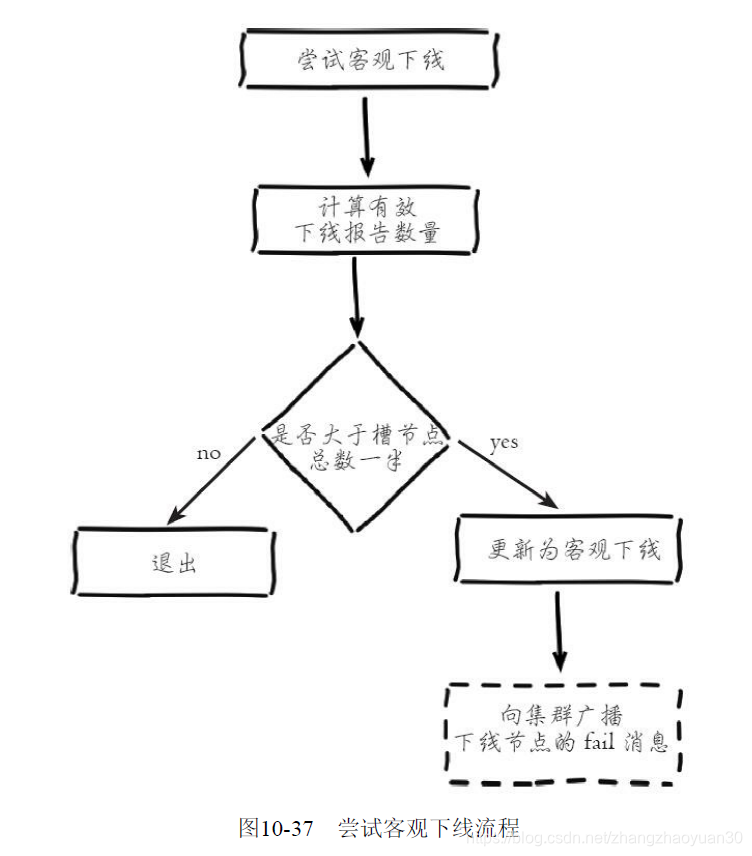
广播fail消息是客观下线的最后一步,它承担着非常重要的职责:
- 通知集群内所有的节点标记故障节点为客观下线状态并立刻生效。
- 通知故障节点的从节点触发故障转移流程。
6.2故障恢复
故障节点变为客观下线后,如果下线节点是持有槽的主节点则需要在它的从节点中选出一个替换它,从而保证集群的高可用。
下线主节点的所有从节点承担故障恢复的义务,当从节点通过内部定时任务发现自身复制的主节点进入客观下线时,将会触发故障恢复流程
![]()
![]()

注:

7.集群运维
7.1集群完整性

7.2带宽消耗
![]()
![]()
![]()
![]()
7.3集群倾斜
-
数据倾斜
![]()

![]()
![]()
使用太多tag
![]()
-
请求倾斜

7.4集群读写分离

7.5手动故障转移

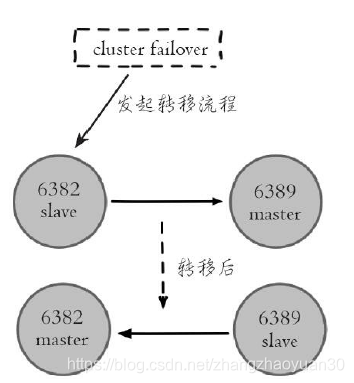
使用场景:
![]()

![]()


7.6数据迁移
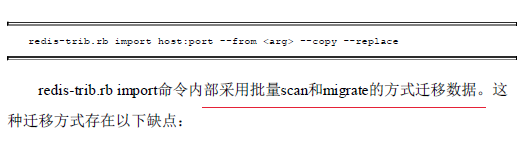


















 2897
2897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









