






[数据分析两三事](谈谈机器学习中的过拟合和欠拟合)
机器学习中的过拟合和欠拟合
作为一只坚挺的小码农,想想一直没有将自己学到的知识有一些自己的见解和沉淀,为了以后能更好地进步,向“张聪明”更进一步,决定开启自己的博客之路,以后的博客会将自己的工作中遇到的问题和学到的知识和大家分享,希望大家能共同进步,有所收获。
——看起来的毫不费力,是背后的无限努力
唠了这么多,这就进入正题。
1.基础概念-训练误差和泛化误差
在进入今天的正题之前,有必要先了解一下这两类误差:训练误差和泛化误差。训练误差就是模型在训练数据集上的错分样本比率,而在任意一个测试数据样本上表现出的误差的期望值叫做泛化误差。
通俗意义上可以理解为,如果我们在做分类问题时,模型在训练样本集上分类的错误率,而泛化误差是模型在测试集上进行应用分类时,真正对数据分类的错误率。俗话说得好,“是骡子是马拉出来遛遛”。
2.什么是过拟合和欠拟合
2.1过拟合
所谓过拟合,指的就是模型在训练集上表现得很好,而在测试集上表现却一般,说明模型训练时,将训练数据的抽样误差也进行了很好的拟合,这就使得模型的泛化能力差(即在对未知数据进行预测时表现一般)。此时应该是训练误差小,泛化误差大。
2.2欠拟合
欠拟合就没什么需要特别解释的了,就是模型的特征较少,无法很好的拟合数据,使得训练时,产生较大的训练误差。
粗略画了下过拟合和欠拟合的示意图,方便理解:

3.什么情况下容易过拟合和欠拟合
3.1过拟合
- 训练集的数量级和模型的复杂度不匹配;
在训练集的数量级要小于模型的复杂度的情况下,在对模型进行训练时,有可能训练数据不够,即训练数据无法对整个数据的分布进行拟合时,或者模型参数数量过多,甚至大于数据量时,容易产生过拟合问题。 - 训练集和测试集特征分布不一致;
- 样本里的噪音数据干扰过大,大到模型过分记住了噪音特征,反而忽略了真实的输入输出间的关系;
- 权值学习迭代次数足够多(overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
3.2欠拟合
特征维度过少,模型过于简单,导致拟合的函数无法满足训练集,误差较大; 因此需要增加特征维度,增加训练数据。
4.过拟合和欠拟合如何解决
4.1如何解决过拟合
事先说明一些概念:
机器学习算法中,常常将原始数据集分为三部分: training data、validation data,testing data。validation data(验证集),用来避免过拟合的,在训练过程中,样本量不是很充足时,我们经常用K折交叉验证的方法来划分训练集和验证集,即将要进行训练的数据分成K份,每次取K-1份进行训练,剩下的一份用来验证,通常我们用验证集(validation data)来确定一些超参数(比如根据验证集上的ACCURACY来确定early stopping的epoch大小、根据validation data确定learning rate等等)。
- 调小模型复杂度,使其适应自己训练集的数量级(缩小宽度和减小深度)。
- 数据增强:训练集越多,过拟合的概率越小。增加数据量有时并不是那么容易,通常可以利用现有数据进行扩充,比如,在计算机视觉领域中,增广的方式是对图像旋转,缩放,剪切,添加噪声等。
- 正则化:参数太多,会导致我们的模型复杂度上升,容易过拟合,也就是我们的训练误差会很小。
下面重点说说正则化吧~
正则化是指通过引入额外新信息来解决机器学习中过拟合问题的一种方法。这种额外信息通常的形式是模型复杂性带来的惩罚度。 正则化可以保持模型简单,另外,规则项的使用还可以约束我们的模型的特性。常用的正则化有L1正则和L2正则,具体使用哪个视具体情况而定,一般L2正则应用比较多。
(当然L1正则也有使用的情况,这一块内容大家可以查阅一下有关向量范数和稀疏性算子的资料)
正则化的函数形式:
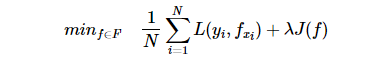
第一项是经验风险,第二项则是正则化项,lamda>0是调整两者之间的关系的系数。
正则化项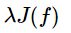 λJ(f)可以取不同的形式。
λJ(f)可以取不同的形式。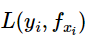 是平方损失,
是平方损失,
正则化项往往是参数向量的L2范数。
L2正则化:
L2正则化是指正则化为参数向量的L2范数。相应的损失函数为:
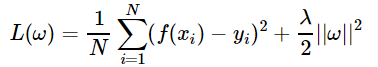
- Dropout:往往针对的是神经网络这一块。例如,训练前,随机删除神经网络的一部分隐层单元,保持输入输出层不变,依照BP算法更新上图神经网络中的权值。
- early stopping: Early stopping是一种以迭代次数截断的方法来防止过拟合。Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,当accuracy不再提高时,就停止训练。
- Bagging用不同的模型拟合不同部分的训练集;Boosting只使用简单的神经网络;
- 数据清洗:将错误的label纠正或者删除错误的数据。
说完了过拟合的解决办法,其实欠拟合的解决办法也就显而易见了。
4.2如何解决欠拟合
过拟合怎么操作,那欠拟合就是它的反向操作:
- 添加其他特征:做特征工程,通过特征组合,转化。
- 减少正则化参数:可以降低lamda,甚至删除正则项,从而增加模型的复杂度。
- 用复杂的模型代替简单的模型:比如,随机森林代替决策树。
- 集成方法:通过一组弱学习器集成一个强的学习器,比如GBDT(XGB,LGM等)
(后面的博文可能会说一些集成学习,主要是GBDT方面的内容,尽请关注~)
参考链接:
博客1: https://www.cnblogs.com/excellent-ship/p/9090949.html.
博客2: https://www.cnblogs.com/hichens/p/12314118.html#autoid-1-0-0


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









