




1 商品维度表(全量)
建表语句
DROP TABLE IF EXISTS dim_sku_info;
CREATE EXTERNAL TABLE dim_sku_info (
`id` STRING COMMENT '商品id',
`price` DECIMAL(16,2) COMMENT '商品价格',
`sku_name` STRING COMMENT '商品名称',
`sku_desc` STRING COMMENT '商品描述',
`weight` DECIMAL(16,2) COMMENT '重量',
`is_sale` BOOLEAN COMMENT '是否在售',
`spu_id` STRING COMMENT 'spu编号',
`spu_name` STRING COMMENT 'spu名称',
`category3_id` STRING COMMENT '三级分类id',
`category3_name` STRING COMMENT '三级分类名称',
`category2_id` STRING COMMENT '二级分类id',
`category2_name` STRING COMMENT '二级分类名称',
`category1_id` STRING COMMENT '一级分类id',
`category1_name` STRING COMMENT '一级分类名称',
`tm_id` STRING COMMENT '品牌id',
`tm_name` STRING COMMENT '品牌名称',
`sku_attr_values` ARRAY<STRUCT<attr_id:STRING,value_id:STRING,attr_name:STRING,value_name:STRING>> COMMENT '平台属性',
`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id:STRING,sale_attr_value_id:STRING,sale_attr_name:STRING,sale_attr_value_name:STRING>> COMMENT '销售属性',
`create_time` STRING COMMENT '创建时间'
) COMMENT '商品维度表'
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_sku_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
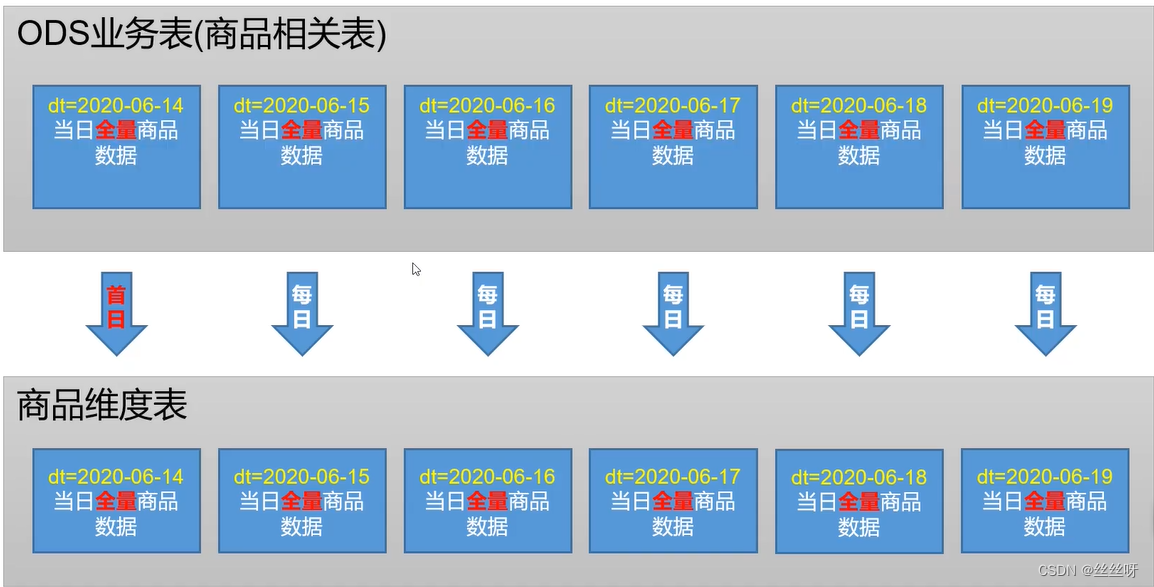
数据装载思路
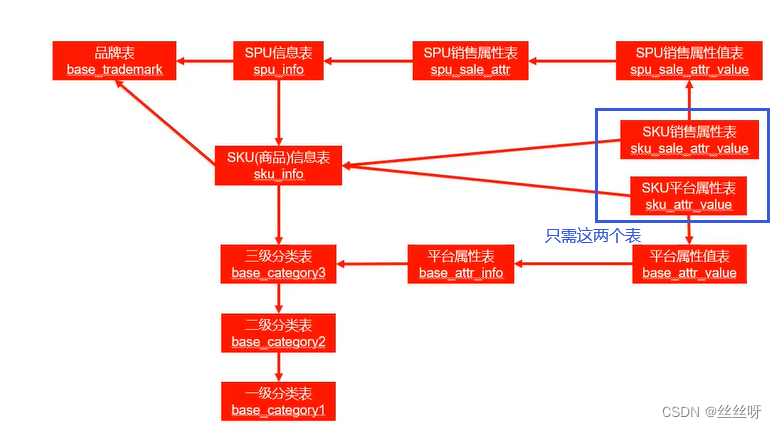
装载语句:
首日装载
with
sku as
(
select
id,
price,
sku_name,
sku_desc,
weight,
is_sale,
spu_id,
category3_id,
tm_id,
create_time
from ods_sku_info
where dt='2020-06-14'
),
spu as
(
select
id,
spu_name
from ods_spu_info
where dt='2020-06-14'
),
c3 as
(
select
id,
name,
category2_id
from ods_base_category3
where dt='2020-06-14'
),
c2 as
(
select
id,
name,
category1_id
from ods_base_category2
where dt='2020-06-14'
),
c1 as
(
select
id,
name
from ods_base_category1
where dt='2020-06-14'
),
tm as
(
select
id,
tm_name
from ods_base_trademark
where dt='2020-06-14'
),
attr as
(
select
sku_id,
collect_set(named_struct('attr_id',attr_id,'value_id',value_id,'attr_name',attr_name,'value_name',value_name)) attrs
from ods_sku_attr_value
where dt='2020-06-14'
group by sku_id
),
sale_attr as
(
select
sku_id,
collect_set(named_struct('sale_attr_id',sale_attr_id,'sale_attr_value_id',sale_attr_value_id,'sale_attr_name',sale_attr_name,'sale_attr_value_name',sale_attr_value_name)) sale_attrs
from ods_sku_sale_attr_value
where dt='2020-06-14'
group by sku_id
)
insert overwrite table dim_sku_info partition(dt='2020-06-14')
select
sku.id,
sku.price,
sku.sku_name,
sku.sku_desc,
sku.weight,
sku.is_sale,
sku.spu_id,
spu.spu_name,
sku.category3_id,
c3.name,
c3.category2_id,
c2.name,
c2.category1_id,
c1.name,
sku.tm_id,
tm.tm_name,
attr.attrs,
sale_attr.sale_attrs,
sku.create_time
from sku
left join spu on sku.spu_id=spu.id
left join c3 on sku.category3_id=c3.id
left join c2 on c3.category2_id=c2.id
left join c1 on c2.category1_id=c1.id
left join tm on sku.tm_id=tm.id
left join attr on sku.id=attr.sku_id
left join sale_attr on sku.id=sale_attr.sku_id;
先创建商品维度表,再执行装载语句:
查看商品维度表中的结果
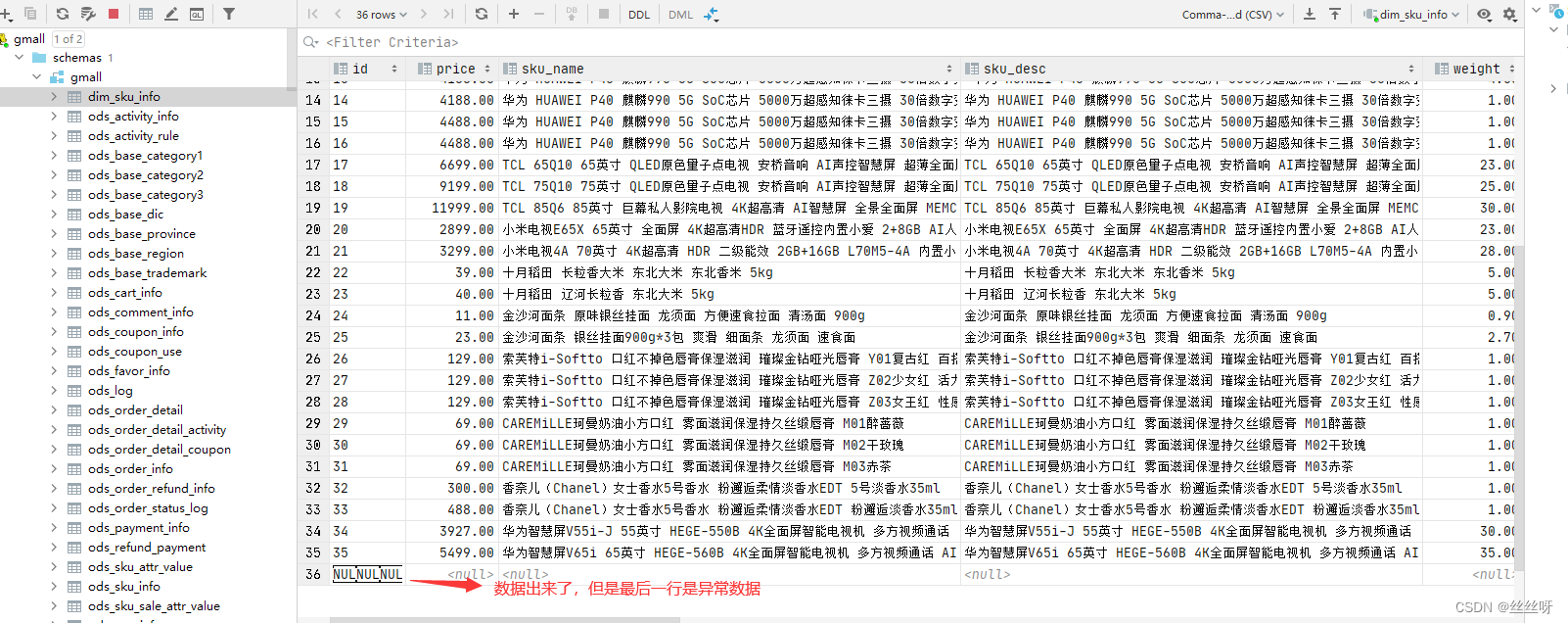
出现异常的原因:会先将索引文件当成小文件合并,将其当做普通文件处理。更严重的是,这会导致LZO文件无法切片。
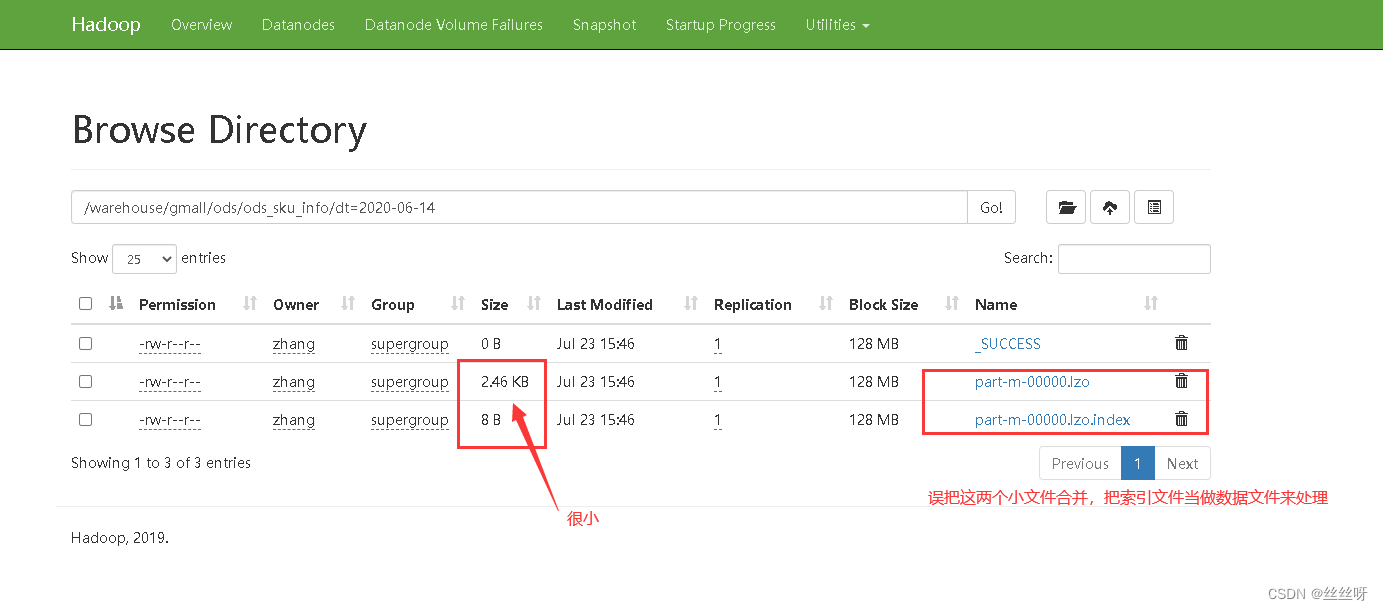
解决索引文件被误合并的问题:(关闭hive的mat端的小文件合并)
解决办法:修改CombineHiveInputFormat为HiveInputFormat
hive (gmall)>
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;
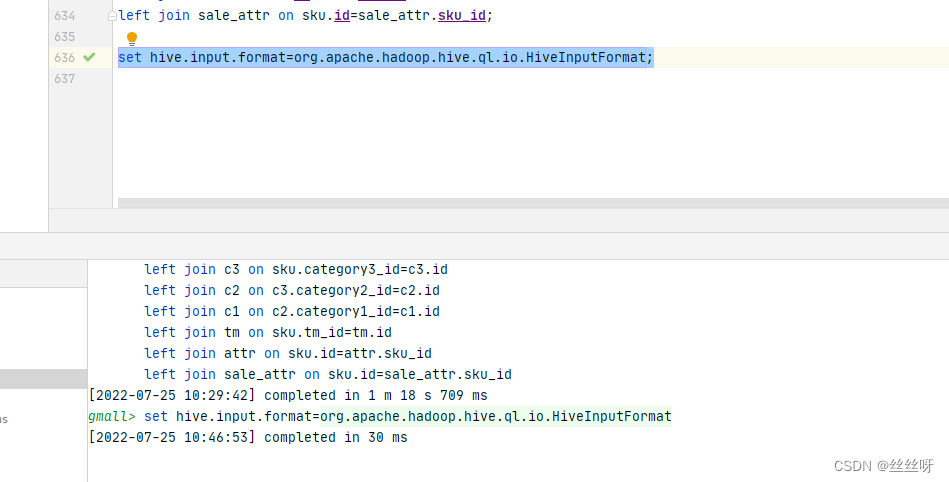
再来执行一下装载语句
(insert overwrite会把原来的数据覆盖掉,所以可以多次执行装载语句)
2 优惠券维度表(全量)
建表语句
DROP TABLE IF EXISTS dim_coupon_info;
CREATE EXTERNAL TABLE dim_coupon_info(
`id` STRING COMMENT '购物券编号',
`coupon_name` STRING COMMENT '购物券名称',
`coupon_type` STRING COMMENT '购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券',
`condition_amount` DECIMAL(16,2) COMMENT '满额数',
`condition_num` BIGINT COMMENT '满件数',
`activity_id` STRING COMMENT '活动编号',
`benefit_amount` DECIMAL(16,2) COMMENT '减金额',
`benefit_discount` DECIMAL(16,2) COMMENT '折扣',
`create_time` STRING COMMENT '创建时间',
`range_type` STRING COMMENT '范围类型 1、商品 2、品类 3、品牌',
`limit_num` BIGINT COMMENT '最多领取次数',
`taken_count` BIGINT COMMENT '已领取次数',
`start_time` STRING COMMENT '可以领取的开始日期',
`end_time` STRING COMMENT '可以领取的结束日期',
`operate_time` STRING COMMENT ' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









