




1 DataGrip准备
1.1 启动HiveServer2
[zhang@hadoop102 hive]$ hiveserver2
1.2 配置DataGrip连接
启动DataGrip,创建连接
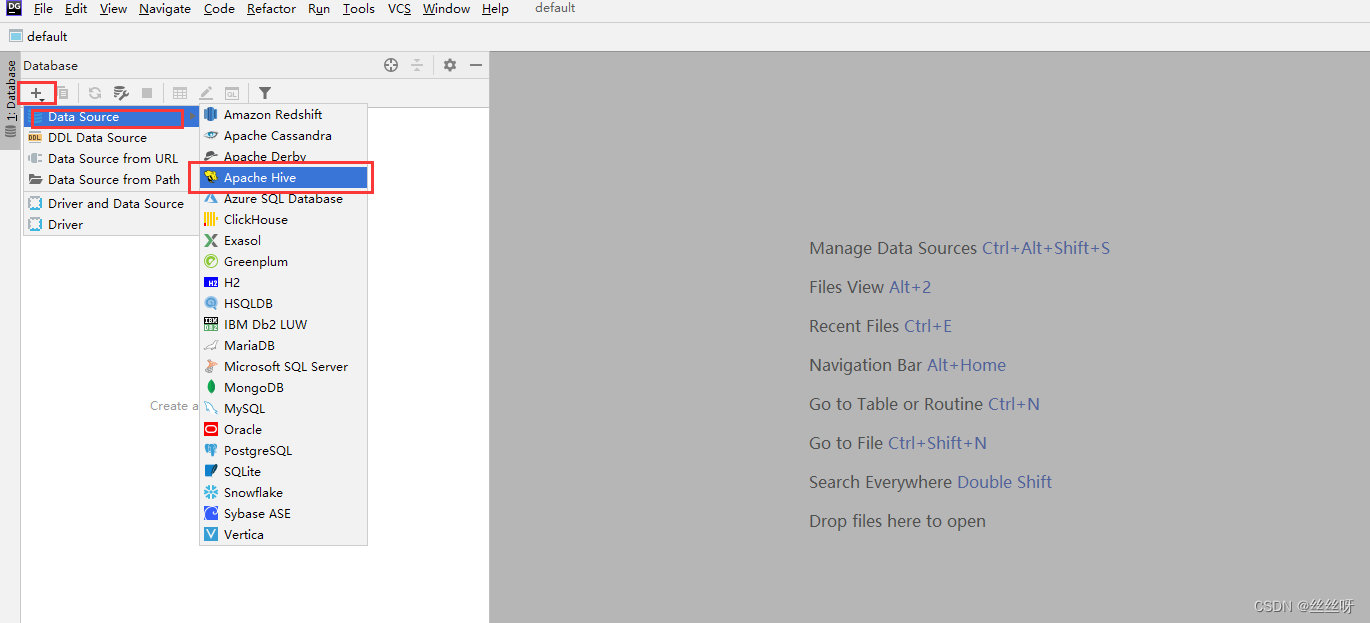
配置连接属性
所有属性配置,和Hive的beeline客户端配置一致即可。初次使用,配置过程会提示缺少JDBC驱动,按照提示下载即可。
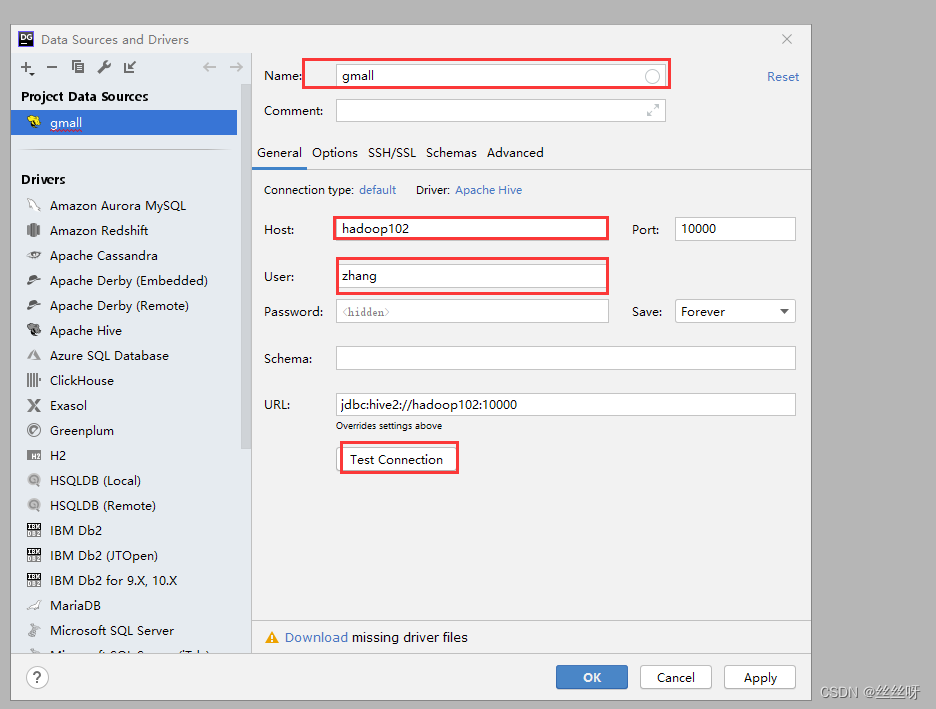
测试时,根据提示下载驱动。
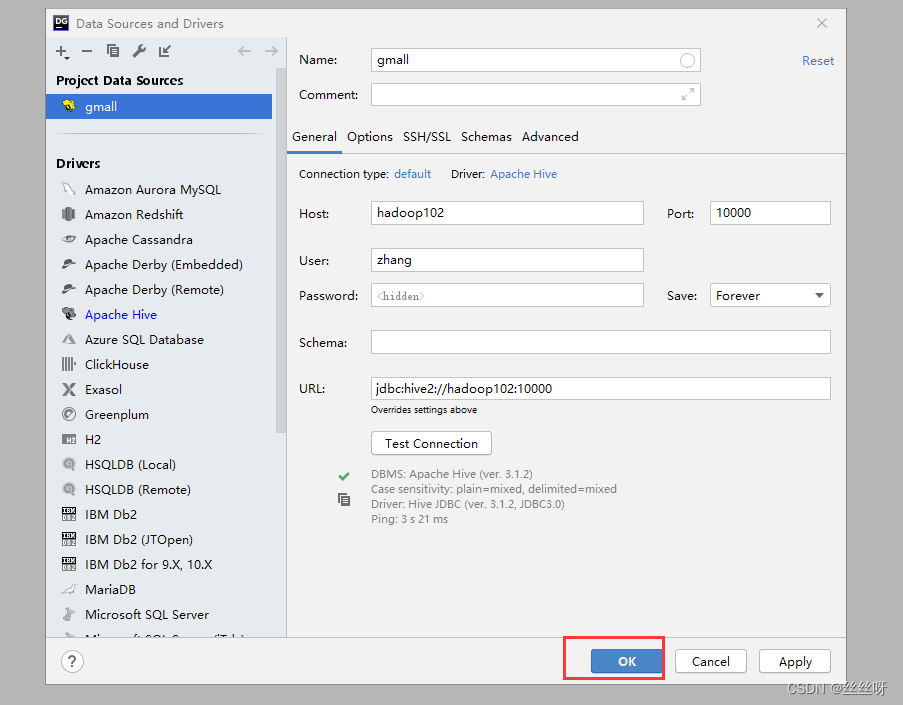
测试使用
创建数据库gmall,并观察是否创建成功。
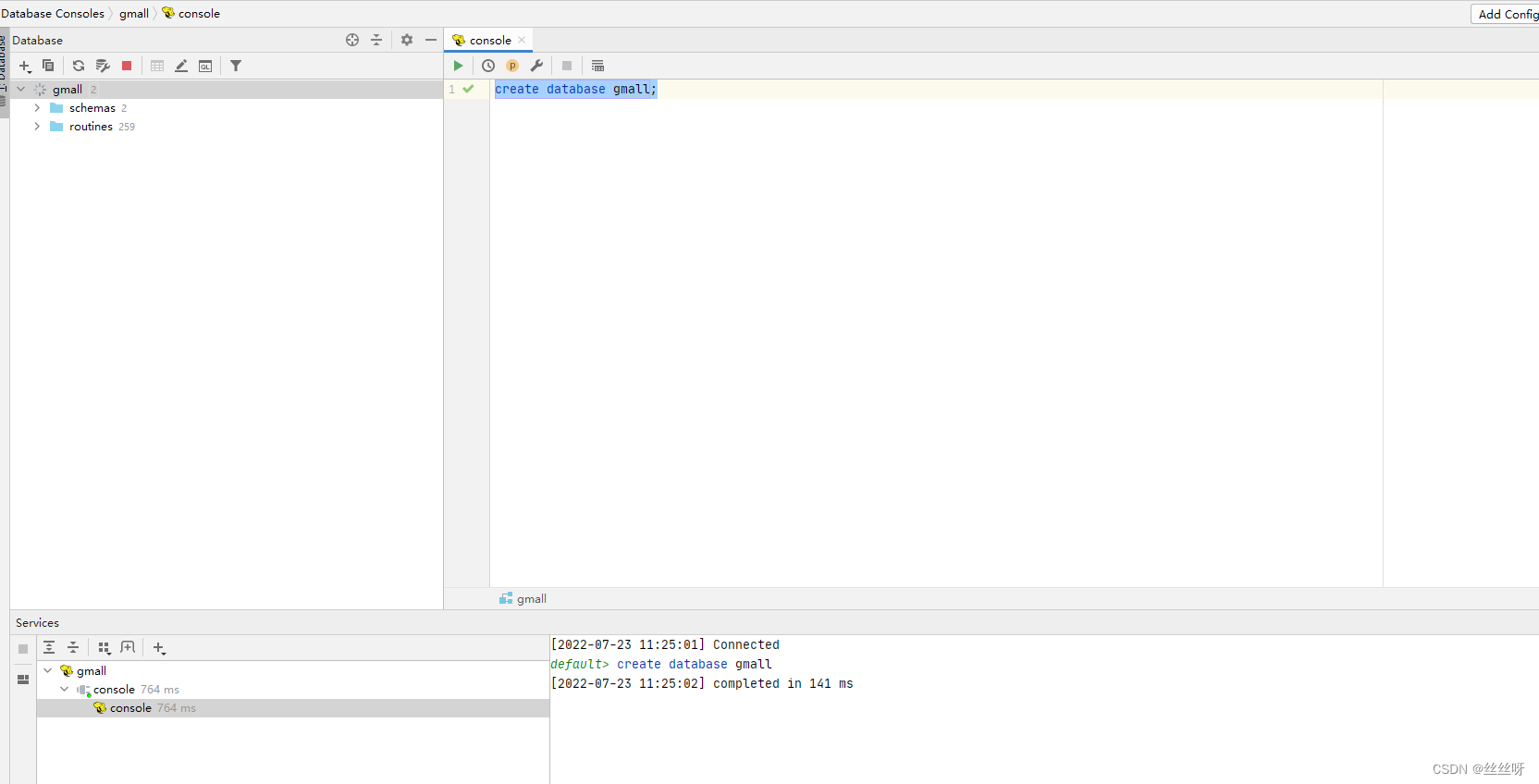
注意当前使用的数据库是谁,默认default
 本文介绍了如何通过DataGrip配置连接HiveServer2,详细步骤包括启动服务、配置属性并验证。重点讲述了如何模拟用户行为日志和业务数据,以2020-06-14为例,涉及Flume-Kafka-Flume日志采集、配置文件修改及数据生成。
本文介绍了如何通过DataGrip配置连接HiveServer2,详细步骤包括启动服务、配置属性并验证。重点讲述了如何模拟用户行为日志和业务数据,以2020-06-14为例,涉及Flume-Kafka-Flume日志采集、配置文件修改及数据生成。
[zhang@hadoop102 hive]$ hiveserver2
启动DataGrip,创建连接
配置连接属性
所有属性配置,和Hive的beeline客户端配置一致即可。初次使用,配置过程会提示缺少JDBC驱动,按照提示下载即可。
测试时,根据提示下载驱动。
测试使用
创建数据库gmall,并观察是否创建成功。
注意当前使用的数据库是谁,默认default

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























