







Caffeine/Guava性能测试
处于性能优化考虑,项目准备将本地缓存从guava cache 转到caffeine cache,于是着手对caffeine进行了一波调研,首先通过一系列测试,通过caffeine和guava从结果来看,在相同cpu负载下,Caffeine Cache的读取和写入速度优于Guava Cache,差距在4倍以上。
但在内存占用方面来看,两者无明显区别。
测试环境:
- CPU:i7-8700 3.20GHz 6核
- 内存:16g
- 系统:Windows 10
- JDK版本:8
- IDE:IDEA
- 内存监控工具:JProfiler
一、速度测试:
测试逻辑:
- 构建Cache,load方法为简单的字符串拼接
- 将250000个字符串加载到cache后,启动任务线程,预热10s后,开始计时,统计每10秒的count,共6轮,最后统计每轮中的每秒平均值
测试结果:
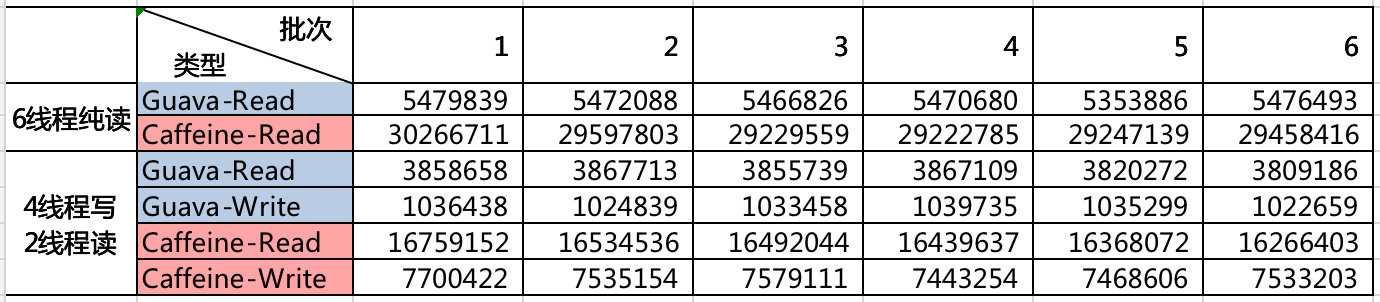
(1) 6个线程纯读:
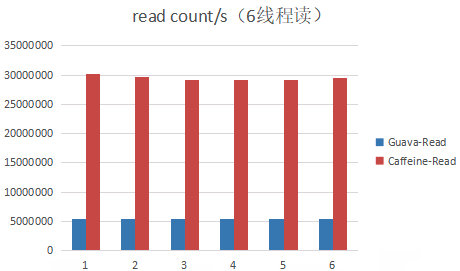
(2) 4个线程读+2个线程写:
二、内存占用测试
测试逻辑:
- 基于项目中使用内存缓存需求最大的数据,构建缓存
- 先初始化缓存对象,10s后将数据库中的20w+条数据存入缓存中,并主动触发一次gc,对比剩余内存占用
测试结果:
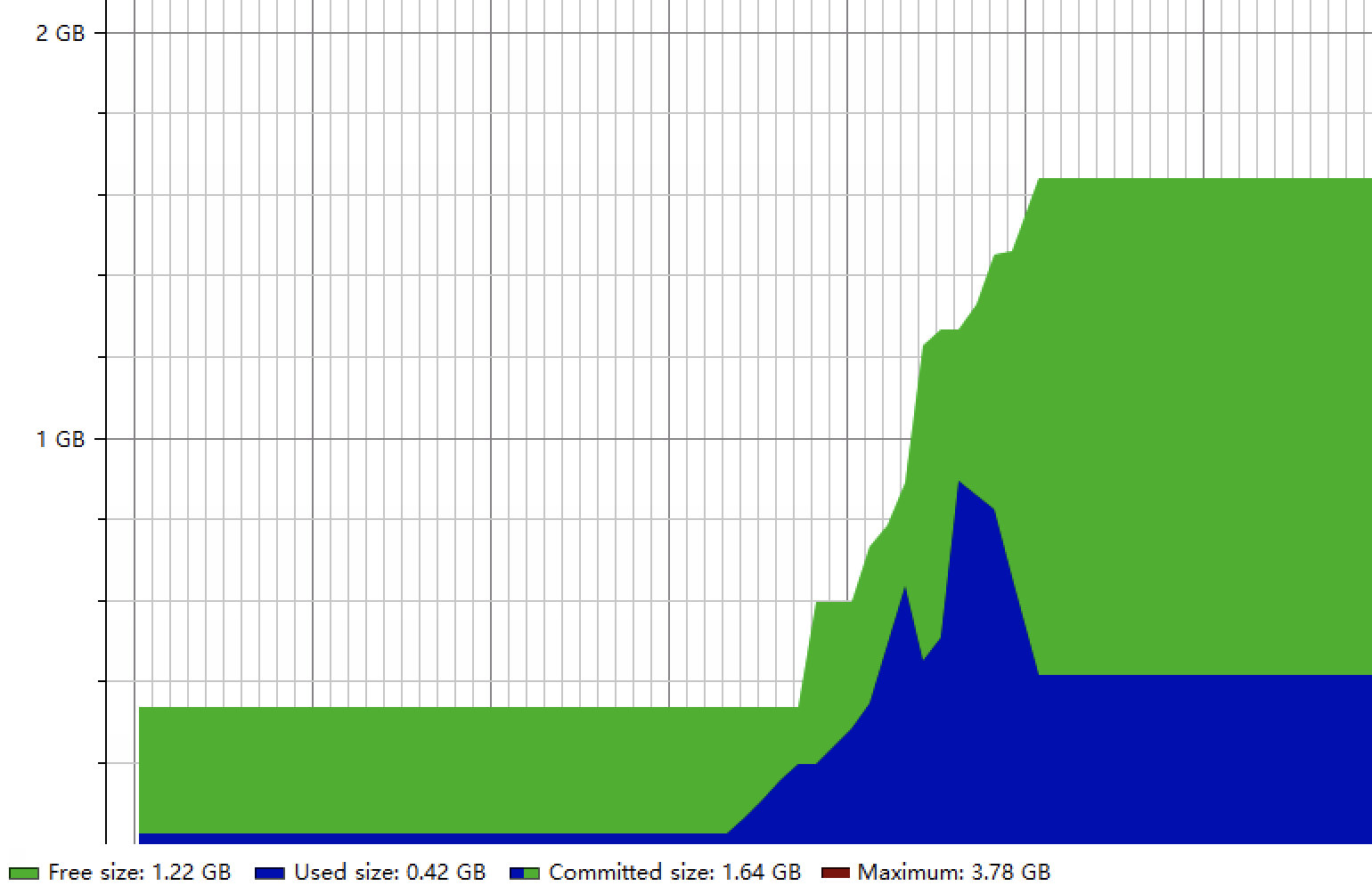
Guava和Caffeine在加载完24w条柜机数据后,通过GC清理掉临时占用的内存,最后都保持了420M的内存占用,无明显区别,整个内存变化如下:
(1)Guava:
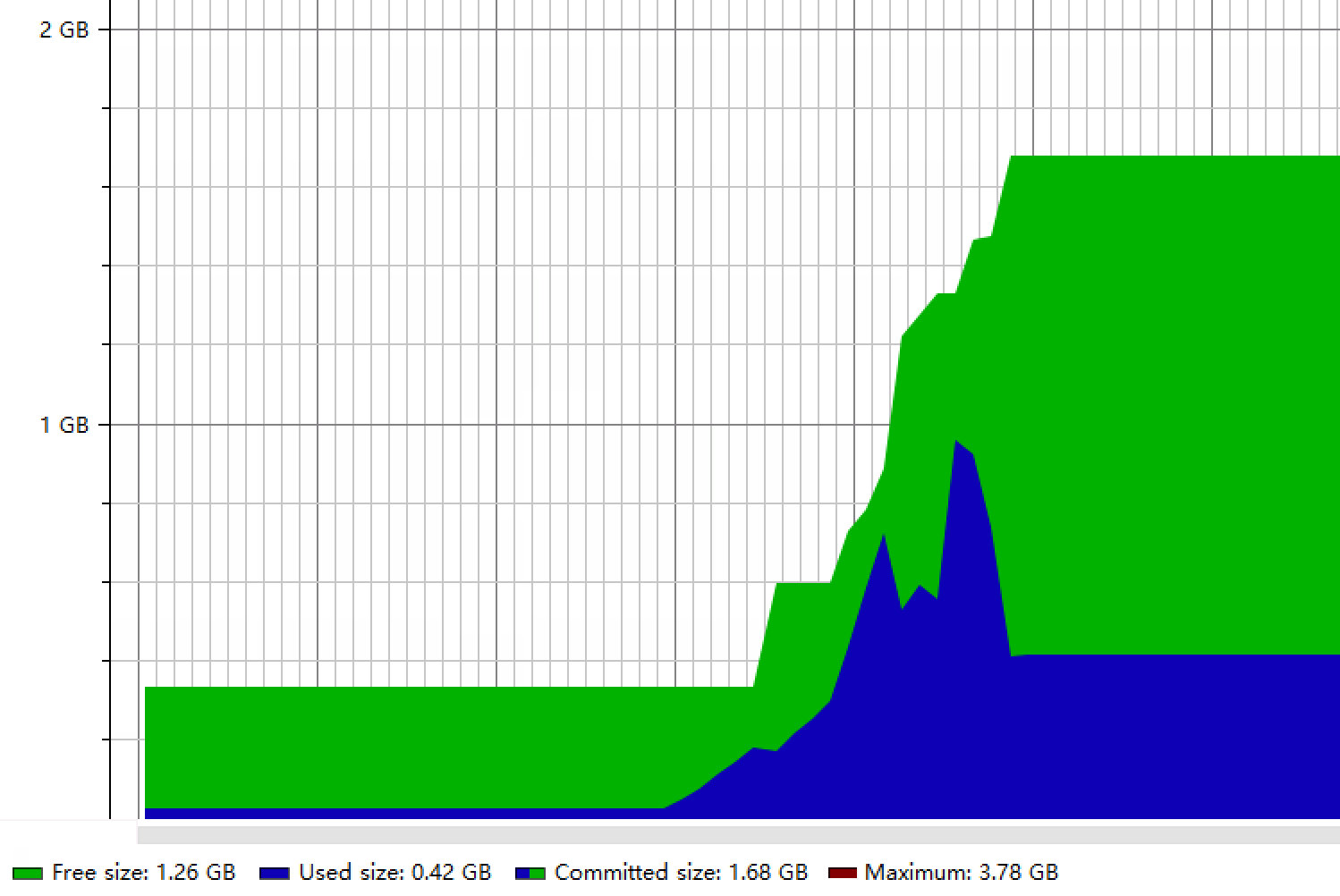
(2)Caffeine:
三、源码分析
Caffeine是在guava基础上进行优化的产物,也是带着替代guava的目的而来的,因而在使用上差别不大,但是通过测试可以明显看到Caffeine在性能上的优势,进而,通过源码,进一步探究了一下Caffeine和guava的区别
一、初始化
Caffeine、Guava都通过builder的方式进行初始化操作,生成缓存对象,通过builder方式可以生成两种缓存对象LoadingCache(同步填充)和Cache(手动填充),LoadingCache继承Cache,相比于Cache,提供了get获取值时,如果不存在值,自动通过CacheLoader的load方法下载数据并返回的功能,此处load方法在初始化时通过重写进行定义,项目中基本通过同步填充的方式,从数据库中加载数据,需要提的是,通过手动加载的方式,也可以在put时传递可执行函数
方式一 cache:
//guava
Cache cache = CacheBuilder.newBuilder()
.maximumSize(maximumSize).
expireAfterWrite(expireAfterWriteDuration, timeUnit)
.recordStats().build( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









