



大家好,我是飞哥!
在现在的主流编程语言中,内存管理是非常重要的组件。Golang 也一样,在 runtime 中实现了自己的内存分配器。内存分配和协程栈、堆、GC 等话题息息相关,只有理解了内存管理才更容易掌握其它核心原理。
经典的内存分配器有 GNU libc 的内存分配器 ptmalloc、google 开发的 tcmalloc、facebook 开发的 jemalloc 等,另外还有 Linux 内核的 slab 我也把它算作一个内存分配器。其实所有的内存分配器考虑的核心问题其实无非就是两个。第一是如何高效地管理页面。第二是如何高效、低碎片率地地在这些页面上为各种不同大小的对象分配内存。
Golang 是 google 生出来的,因此内存分配也是基于 tcmalloc 发展而来。 但如果单独学习 tcmalloc 的话,我感觉有些单调。今天我的思路是从内核的 SLAB 讲起,和 golang 的分配器对比着来讲。这样更能加深你对内存分配器的原理的认知。
好,我们开始今天的内功修炼之旅!
一、内核中页内存的管理
1.1 物理内存页管理
在现代的服务器上,内存和CPU都是NUMA架构。每一个CPU以及和他直连的内存条组成了一个 node(节点)。
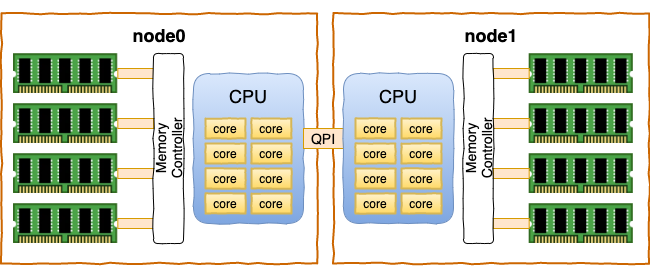
每个 node 又会划分成若干的 zone(区域) 。zone 表示内存中的一块范围
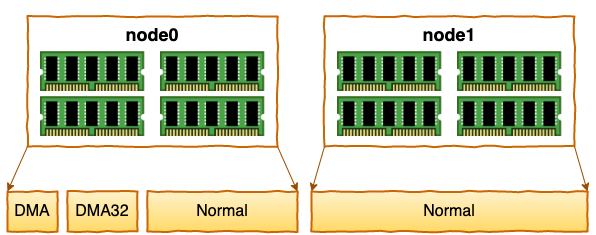
在每个zone下,都包含了许许多多个 Page(页面), 在linux下一个Page的大小一般是 4 KB。
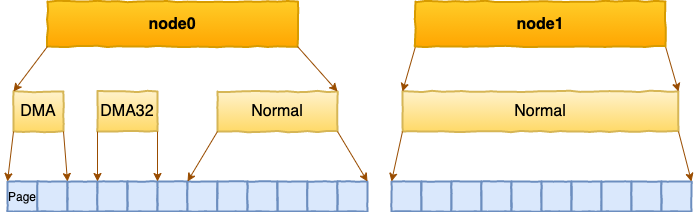
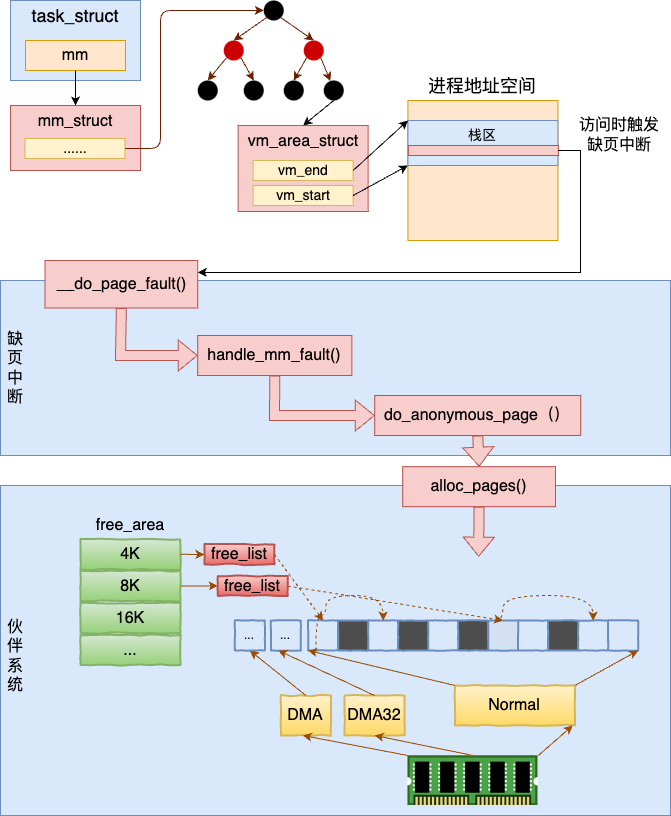
每个 zone 下面都有如此之多的页面,Linux使用伙伴系统对这些页面进行高效的管理。 在内核中,表示 zone 的数据结构是 struct zone。 其下面的一个数组 free_area 管理了绝大部分可用的空闲页面。这个数组就是伙伴系统实现的重要数据结构。
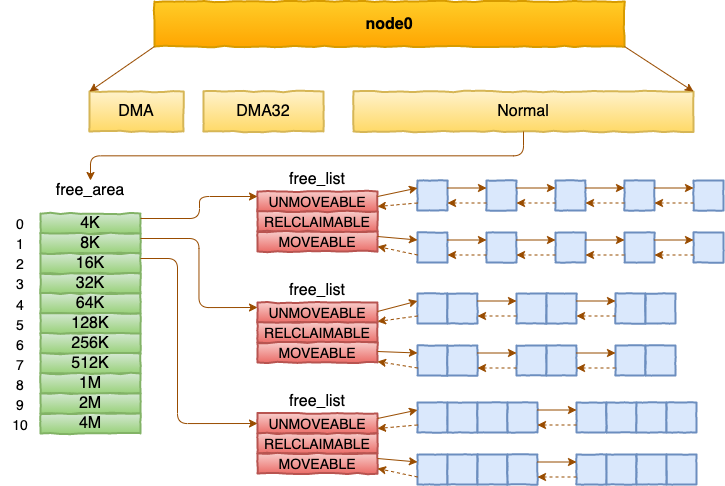
内核提供分配器函数 alloc_pages 到上面的多个链表中寻找可用连续的物理页面。
内核自己在使用内存的时候,都是直接使用物理内存。内核的 SLAB 内存系统直接调用伙伴系统的 alloc_pages 分配物理页来使用。但是对于用户进程来说,内核处于各种考虑,并不会直接开放物理内存的权限。
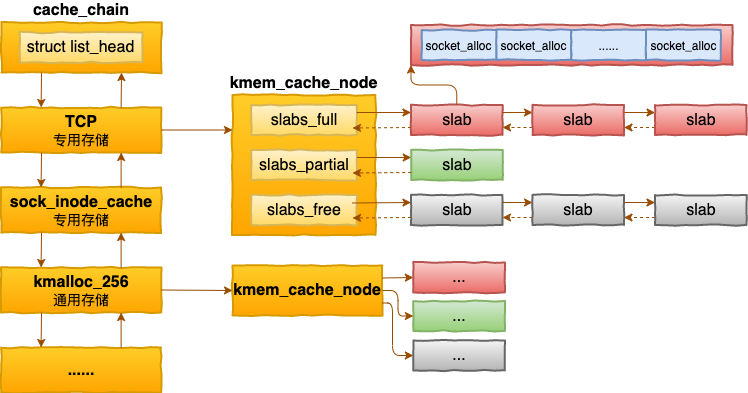
1.2 SLAB cache 之内存分配
在 说出来你可能不信,内核这家伙在内存的使用上给自己开了个小灶! 中我们了解到内核使用了一种叫做 SLAB 的机制完美解决了以上问题。内核中的 SLAB 是类似我们生活实践中的集装箱。要装什么对像就装什么,这样每个 SLAB 中的元素大小完全一致,如果有元素释放了,下次可以非常完美地被复用。
每一个 SLAB 由 N 个整数 Page 组成,是提前批量好的,也叫做缓存。每当需要分配对象的时候,直接从缓存中分配即可,极大地提高了效率。
内核中的每一种不同的对象都有自己独立的 SLAB cache。虽然后来的 slab merge 允许不同的对象复用同一套 cache,但是仍然要求必须是相同大小的对象才行。
1.3 虚拟内存的管理
内核给用户进程的 task_struct 中提供了一个 mm_struct。在这个 mm_struct 使用红黑树管理了一个完整的地址空间,每一个红黑树上的 vm_area_struct 都是已经分配的地址空间中的一段范围。
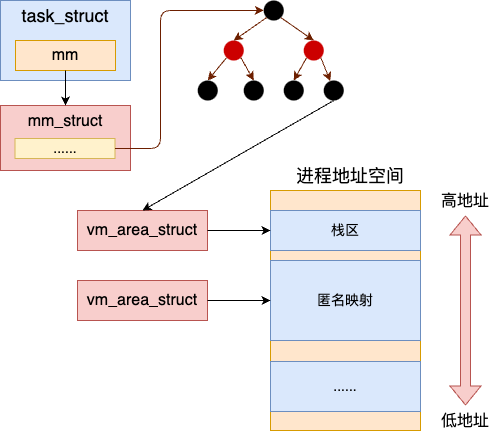
当用户进程调用 mmap 等系统调用的时候,实际上并不涉及任何的内存操作。而是只是申请一个 vm_area_struct,表示下这个地址范围(注意仅仅只是地址范围)被用户进程使用了就可以了。
当用户进程中真正访问这段内存的时候,再由缺页中断分配。
二、Golang 内存管理
在上一小节介绍的内核的管理机制里,有一个最核心的点,那就是内核是以 4 KB 为单位来管理内存的。无论是伙伴系统,还是 mmap 系统调用。但在外面的应用程序中,用户有可能申请任意大小的内存,有可能只要几个字节,几十字节的小内存。
所有的内存管理系统要解决的问题之一是如何在以固定大小的内存页面解决灵活分配任意大小的内存,既要效率高,碎片率还要尽可能的低。其实 go 语言内存分配器和上面这套 SLAB 管理机制的思想有不少相近之处。
在 TC malloc 中,为了应对多线程并发,还在线程级实现了缓存,规避锁的开销。整个 TCMalloc 由三级缓存,分别是 mcache(线程级对象分配缓存),mentral(中央缓存),mheap(页分配系统),最后两级需要加锁访问。
第一,页分配系统 mheap。内核的伙伴系统管理的是物理页,然而应用层是没有办法直接使用物理页的。对于应用层来说,使用内存的唯一方法就是通过操作系统提供的系统调用来申请虚拟内存页。而且虚拟页分配 mmap 分配出来的也是整数页。所以应用层需要一个类似内核中的伙伴系统,来高效地将应用进程中使用到的虚拟内存页管理起来。golang 中是用 mheap 实现的。
第二,对象分配系统 mcache。当应用页分配系统具备了以后,还需要解决高效分配任意大小的内存对象的问题。在内核中的 SLAB 很好地实现了这个功能。应用程序也需要这样一个系统来高效地为任意大小的对象分配内存。速度要快,而且碎片率还要低。golang 中是用 mcache 实现的。
2.1 go 的页分配系统
操作系统通过 mmap 为应用层提供虚拟内存分配的接口。然后每一次调用 mmap 都需要一次系统调用,开销是比较高的。所以在应用层更高效的办法是自己批量申请一些虚拟内存页,然后自己管理起来。当有需求的时候,先从自己的页堆中获取分配。而不是每次都要调用系统调用。这就是页分配系统的主要功能。
申请到的 Page 比较多的话,就需要高效地将所有的页面管理起来。前面我们看到了在内核中,是使用伙伴系统来高效管理所持有的所有物理页的。在 go 中,这个页分配系统的核心数据结构就是 mheap。
同内核不一样的是,mheap 并没有采用伙伴系统来管理页堆。而是使用的稀疏数组的方式。 Go runtime 定义了一个 mheap 类型的全局变量 mheap_。在该全局变量内,定义了一个 4 M(400 万个元素) 大小的指针数组,每一个元素中的指针或者为空,或者指向一个管理着 64 MB 大小内存块的 heapArena。
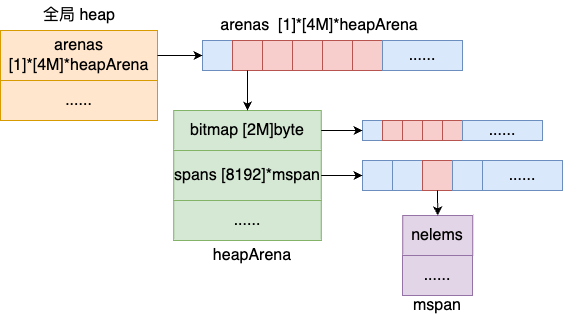
由上图可以看出,每一个 heapArena 中包含了 8192 个 mspan 指针,同时还包括了管理这些内存的各种各样的 bitmap。有了示意图,相信再看起来源码就要轻松多了。
//file:runtime/mheap.go
type mheap struct {
// arenaL2Bits 的值为 22
arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena
//mcentral内存
central [numSpanClasses]struct {
mcentral mcentral
pad ...
}
}
var mheap_ mheap我们先重点看 arenas,这是一个表示页堆的数组。每一个页堆的大小是 64 MB。在 Linux 64 位系统下,上述二位数组的第一维是 1 ,第二维是 4 MB。所以整个堆区最多可以管理 256 TB 的内存。
mheap 中直接定义了一个 4 MB 大小的数组指针,64 位系统下每一个指针 8 个字节。所以光这个二维数组就是 32 MB 的内存,消耗挺大的。不过好在这占用的只是虚拟内存,没有实际访问发生的时候不会分配物理内存。
其中每一个页堆的是一个 heapArena,里面包含了 8192 个页面,每个页面大小是 8 KB,所以总共是 64 MB 的内存。为了管理这些内存,heapArena 还定义了若干个 bitmap。
//file:runtime/mheap.go
type heapArena struct {
// pagesPerArena 大小为 8192
spans [pagesPerArena]*mspan
// heapArenaBitmapBytes 大小为 2097152
bitmap [heapArenaBitmapBytes]byte
// 使用的页的 bitmap
pageInUse [pagesPerArena / 8]uint8
......
}我们来重点看下 bitmap 和 pageInUse 这两个位图。
bitmap:这个 bitmap 的作用是为 GC 功能进行标记。将总 64 MB 的数据,划分成每 8 字节为一个单位。每个单位分配两个 bit,一个 bit 标记对应地址中是否存在对象,另外一个 bit 标记此对象是否被 gc 标记过。总共需要 2097152 大小的内存来完成 gc 标记。
pageInUse:是一个位图,使用1024 * 8 bit来标记 8192 个页 (8192*8KB = 64MB) 中哪些页正在使用中;
在 go 中,对每一个 Page 的大小定义为 8 KB。spans: 这是一个数组,定义了 8192 个 mspan。其中每一个 mspan 使用一个页。所以,整个 heapArena 所管理的内存的大小是 64 MB。
了解了页堆的数据结构,我们再来看看页堆对外提供的接口是如何工作的。页堆通过 runtime.alloc 函数对 runtime 中的其他函数提供分配页面的功能。
//file:runtime/mheap.go
func (h *mheap) alloc(npages uintptr, spanclass spanClass, needzero bool) (*mspan, bool) {
systemstack(func() {
s = h.allocSpan(npages, spanAllocHeap, spanclass)
})
}runtime.alloc 又通过 runtime.mheap.allocSpan 分配新的内存管理单元。
//file:runtime/mheap.go
// allocSpan allocates an mspan which owns npages worth of memory.
func (h *mheap) allocSpan(npages uintptr, typ spanAllocType, spanclass spanClass) (s *mspan) {
gp := getg()
...
// 省略掉 pcache 获取缓存页逻辑
...
// 内存比较大或者线程的页缓存中内存不足,从 mheap 的 pages 上获取内存
if base == 0 {
base, scav = h.pages.alloc(npages)
if base == 0 {
growth, ok = h.grow(npages)
...
base, scav = h.pages.alloc(npages)
}
}
//申请内存完毕,初始化 span
HaveSpan:
...
}在 runtime.mheap.allocSpan 中,我们省略掉了一些逻辑,直接看从 mheap 的 pages 上获取内存。
调用 h.pages.alloc 从页堆中的现有页面分配
如果没有分配则调用 grow 从操作系统申请页面
重新调用 h.pages.alloc 从页堆分配
从页堆中分配页面的逻辑就先不看了,我们来看 runtime.mheap.grow 方法是如何从操作系统申请内存,并管理起来的。
//file:runtime/mheap.go
func (h *mheap) grow(npage uintptr) bool {
av, asize := h.sysAlloc(ask)
...
}最后 sysAlloc 会通过 sysReserve、sysReserveAligned 等方法发起 mmap 系统调用向操作系统申请内存。
//file:runtime/malloc.go
func (h *mheap) sysAlloc(n uintptr) (v unsafe.Pointer, size uintptr) {
for h.arenaHints != nil {
v = sysReserve(unsafe.Pointer(p), n)
...
}
if size == 0 {
v, size = sysReserveAligned(nil, n, heapArenaBytes)
}
mapped:
// 创建 arena 元数据.
// 把 arena 添加到 heap 的 arenas 数组中.
...
return
}在向操作系统申请到内存之后,会创建 arena 元数据,并把 arena 添加到 heap 的 arenas 数组中。
最后看一眼 sysReserve ,它确实是调用的 mmap 系统调用。
//file:runtime/mem_darwin.go
func sysReserve(v unsafe.Pointer, n uintptr) unsafe.Pointer {
p, err := mmap(v, n, _PROT_NONE, _MAP_ANON|_MAP_PRIVATE, -1, 0)
return p
}到这里,页分配系统就就绪了。如果用户分配的内存块比较大的时候,就可以直接使用该系统进行分配。事实上,golang 在分配大于 32 KB 的内存的时候,就是将其对齐到整数页,然后调用 runtime.mheap.alloc 来获取整数页的。
// runtime/malloc.go
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
// 如果小于32K,maxSmallSize 为 32678
if size <= maxSmallSize {
...
} else {
// 如果大于32K,则直接使用页分配
span = c.allocLarge(size, noscan)
...
}
}其中 allocLarge 主要就是调用 runtime.mheap.alloc 实现的。
2.3 go 的对象分配系统
当应用页分配系统具备了以后,分配大内存(32 KB 以上)是没有问题了。但是应用程序中存在大量的小内存的需求,可能就是几个、几十字节。还需要解决高效分配较小的对象内存的问题。
在内核中的 SLAB 很好地实现了这个功能。为每一种内核对象类型,或者特定大小的内核对象定制一个专属的 SLAB 缓存是可行的。每一个 SLAB 缓存都提前从页分配系统里获取批量的页,用这些页组成一个一个的 SLAB。在每一个 SLAB 内都固定特定的内核对象,或者特定大小的内核对象。
应用程序也需要这样一个系统来高效地为任意大小的对象分配内存。速度要快,而且碎片率还要低。但是对于应用层来说,可以借鉴内核的这个思想。但直接照搬这个模式是不太可行的。因为应用层要分配的对象的大小是千变万化的。总不至于从1、2、3、...、10000、..., 依次为每一种大小都定制一个专用的缓存吧。
Golang 的做法是允许适度的浪费,比如设定一个 64 字节大小的缓存区,将超过 56 字节但小于等于 64 字节的对象都存储到这个缓存区里。这样虽然存在些许的浪费,但高效的应用层对象分配系统就有希望建设出来了。和内核中 slab 对应,golang 中用来存储特定大小的单元叫做 span。
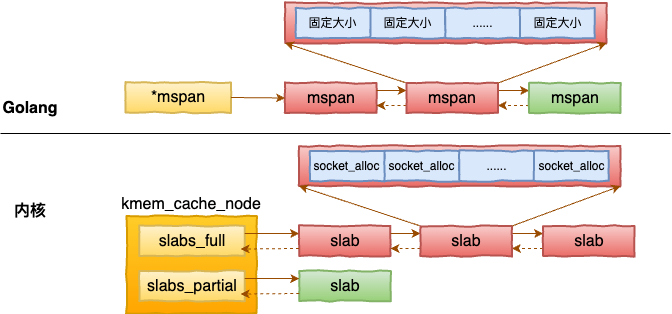
我们再来看下 span 的源码。
//file:runtime/mheap.go
type mspan struct {
// 多个 span 用一个链表来串起来
next *mspan
prev *mspan
// 当前 span 所管理的内存
startAddr uintptr//起始地址
npages uintptr//页面数量
// 当前 span 所管理的元素
elemsize uintptr//管理元素大小
nelems uintptr//可管理的元素数量
......
}在 mspan 的几个重要字段含义如下:
startAddr 和 npages 两个字段指明了当前 span 所管理的内存的起始地址,以及管理了几个页面。
elemsize 指明了当前 span 所管理的元素的大小,nelems 代表这个 span 可以存多少个对象。nelems 等于(npages * pageSize) / elemsize。
有了 span 以后,就可以按照不同的尺寸来定义专用的 span 了,将大小接近的对象都存储到一个 span 中。在 golang 中是在 mcentral 中维护着不同大小的 span。
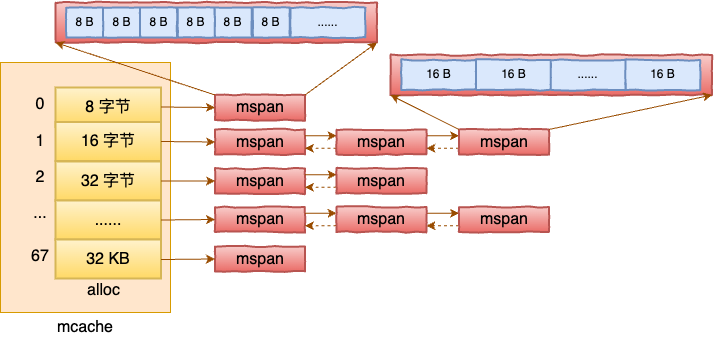
值得注意的是在 Golang 中,为了避免不同线程之间申请内存的锁的冲突和开销,做法是为每一个 P 都准备了一套对象分配系统 - mcache。
我们再来看下 golang 分配内存的核心函数 mallocgc。
// runtime/malloc.go
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
...
// 如果小于32K,maxSmallSize 为 32678
if size <= maxSmallSize {
//如果要分配的对象小于 16字节,maxTinySize 为 16
if noscan && size < maxTinySize {
...
} else {
//如果要分配的对象大于等于 16 字节,但小于 32678
...
}
} else {
// 如果大于32K,则直接使用页分配
...
}
}在 mallocgc 中除了大于 32 KB 的情况外,又细分了小于 16 字节和大于 16 字节但小于 32678 两种情况。但无论哪种情况。都是使用到了 mcache。通过在要申请的内存的大小寻找到合适的 mspan 链表,调用 nextFreeFast 从 mspan 中根据 bitmap 找到一块内存然后分配给用户。
span = c.alloc[...]
v := nextFreeFast(span)当 mcache 中没有足够的 span 可用的时候,会调用到 mcentral 中缓存的 span,如果还没有,就会调用 mheap,最后向操作系统发起内存申请。
三、总结
所有的内存管理系统要解决的核心问题是如何在以固定大小的内存页面解决灵活分配任意大小的内存,既要效率高,碎片率还要尽可能的低。
Golang 使用页堆 mheap 批量地向操作系统申请虚拟内存。这样的好处是申请到的都是连续的地址,这样访问效率高,使用起来也方便,而且系统调用的次数也会降到最低。
Golang 的 mcache 中的 span 管理内存的思想和操作系统中的 SLAB 非常的相像。唯一的区别是内核是给每个内核对象都准备一套 SLAB 缓存。但 Golang 由于对象大小的不确定性,需要容忍一定程度的浪费,将对象大小进行上对齐后,再放到固定大小的 mspan 中。 golang 中的 mspan 和 内核的 SLAB 非常的接近。
在应用程序向 runtime 申请内存的时候,大于 32 KB 的就直接走 mheap 申请了。小于这个的需要走到 mcache 中寻找大小合适的 mspan 来分配。当然了,mcache 中的 mspan 也都是向 mheap 申请来的。
就这样,golang 实现了它的内存分配器。


















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









