




R1-Searcher++: Incentivizing the Dynamic Knowledge Acquisition of LLMs via Reinforcement Learning 2025.05
- 对于LLMs而言,在大规模数据上的广泛预训练已赋予它们丰富的内部知识。因此,为模型配备根据需求在内部和外部知识源之间动态切换的能力至关重要。此外,还应鼓励模型将训练过程中遇到的知识内化,逐步丰富内部知识并持续向更高智能进化。
- 此外,R1-Searcher经过RL训练之后会过度依赖外部搜索引擎。
训练分为两个阶段:
第一阶段:SFT冷启动阶段,让模型以正确的格式响应问题。
通过拒绝采样收集符合格式要求的数据,使用 SFT 进行冷启动训练,初步使模型学会自主使用外部检索,输出融合内外知识的格式化回答。
该阶段的损失函数:
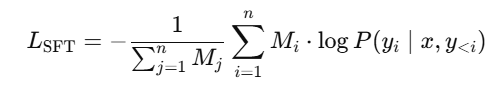
其中,
Mi=1M_i = 1Mi=1 → 如果这个 token 是模型内部知识生成的();
Mi=0M_i = 0M
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











