







 逻辑回归是一种基于线性回归的分类模型,通过将线性回归的连续输出转化为离散类别。它使用sigmoid函数将预测值映射到(0,1)区间,适用于二分类问题,可以作为概率预测。训练时,逻辑回归采用极大似然估计优化参数,常见的优化算法包括梯度下降法和牛顿法。因其简单易用和高效,逻辑回归在机器学习中扮演了基础角色。"
127507178,9640242,C语言循环结构编程实践,"['C语言', '算法', '编程实践']
逻辑回归是一种基于线性回归的分类模型,通过将线性回归的连续输出转化为离散类别。它使用sigmoid函数将预测值映射到(0,1)区间,适用于二分类问题,可以作为概率预测。训练时,逻辑回归采用极大似然估计优化参数,常见的优化算法包括梯度下降法和牛顿法。因其简单易用和高效,逻辑回归在机器学习中扮演了基础角色。"
127507178,9640242,C语言循环结构编程实践,"['C语言', '算法', '编程实践']
逻辑回归是一种用于分类任务的线性模型,它是建立在线性回归的基础上,通过将线性回归模型的结果利用一个函数映射到离散值上来实现分类的。线性回归试图学得一个通过样本属性的线性组合来进行预测的函数,即
<div align=center>
![]() (1)
(1)
向量形式写成
fx=wx+b![]() (2)
(2)
线性回归产生的预测值为实值z=wx+b![]() ,逻辑回归通过一个单调可微函数将分类样本的标签与该实值联系起来,例如在二分类任务中的sigmoid函数
,逻辑回归通过一个单调可微函数将分类样本的标签与该实值联系起来,例如在二分类任务中的sigmoid函数
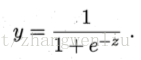 (3)
(3)
该函数图像如下
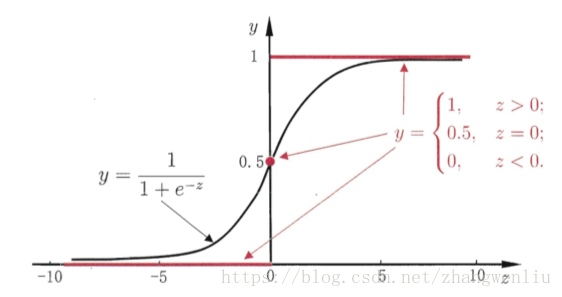
从图中可以看出,该函数将线性回归预测的结果映射到(0,1)范围内,从而可以设定阈值(例如0.5)来判断二分类的类别,并且由于该函数的特点,它还能得到近似概率预测。
逻辑回归的训练过程就是根据训练氧泵确定参数w![]() 和b的过程,通常采用极大似然法来估计,即令每个样本属于其真实标记的概率越大越好。根据似然函数可以得到其损失函数,通常采用迭代的方法,求解使损失函数最小的参数w
和b的过程,通常采用极大似然法来估计,即令每个样本属于其真实标记的概率越大越好。根据似然函数可以得到其损失函数,通常采用迭代的方法,求解使损失函数最小的参数w![]() 和b,在这个过程中,可以使用一些数值优化算法,如梯度下降法和牛顿法等。
和b,在这个过程中,可以使用一些数值优化算法,如梯度下降法和牛顿法等。
逻辑回归是一种基础的线性机器学习模型,形式简单,易于建模,训练速度快。

















 6117
6117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









