



 本文详细介绍了C++中的异常处理,包括throw、try和catch的使用。通过一个具体的例子展示了如何在除数为0时抛出并捕获异常,利用runtime_error类和what()函数进行错误信息的显示。异常处理机制确保了程序在遇到错误时能够优雅地处理并提供反馈。
本文详细介绍了C++中的异常处理,包括throw、try和catch的使用。通过一个具体的例子展示了如何在除数为0时抛出并捕获异常,利用runtime_error类和what()函数进行错误信息的显示。异常处理机制确保了程序在遇到错误时能够优雅地处理并提供反馈。
异常是指存在于运行时的反常行为,典型的异常包括失去数据库的连接以及遇到意外的输入。
异常处理机制包括检测和处理这两个部分。
C++中通过throw 抛出异常,try主要是检测可能出现问题的部分,catch 用来捕异出现的异常并提供解决方案。
下面来看一个例子:输入两个整数,求商,并且当除数为0时异常。代码如下:
#include<iostream>
#include<stdexcept>
using namespace std;
int main()
{
#if 0
int i,j;
cin>>i>>j;
cout<<i/j<<endl;
#else
int i,j;
label:
while (cin>>i>>j)
{
try{
if(j==0)
throw runtime_error("fail:divisor is 0");
}
catch(runtime_error err)
{
cout<<err.what()<<"\ntry again? Enter y or n"<<endl;
char c;
cin>>c;
if(c=='n')
break;
else
{
cout<<"entry two number:"<<endl;
goto label;
}
}
cout<< i/j <<endl;
}
#endif
}
runtime_error是 stdexcept中定义的异常类 表示只有在运行时才检测出问题。
what( )是runtime_error类中的一个成员函数,返回值是初始化一个具体对象时所用的string对象的副本。
//其实以上的抛出异常之后用what()来接收,和线程结束时 pthread_exit(void * retval)的 retval能被线程回收 pthread_join( pthread_t thread , void **retval) 获取有点像,关于线程结束、回收的内容看笔者前面的文章即可。
上面的简例结果如下:
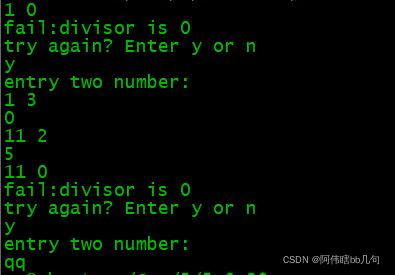
总结:本文用简单的例子介绍了 throw try catch 的用法。

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









