




 本文介绍使用Jsoup库进行网络爬虫的实践案例,包括抓取优快云博客的文章标题及摘要,以及爬取小说网站的书籍列表。
本文介绍使用Jsoup库进行网络爬虫的实践案例,包括抓取优快云博客的文章标题及摘要,以及爬取小说网站的书籍列表。
jsoup 中文参考文献 http://www.open-open.com/jsoup/
本文将利用jsoup,简单实现网络抓取的功能,该实例效果为:获取http://blog.youkuaiyun.com/zhangvalue的所有文章的标题以及打印出来简单摘要。
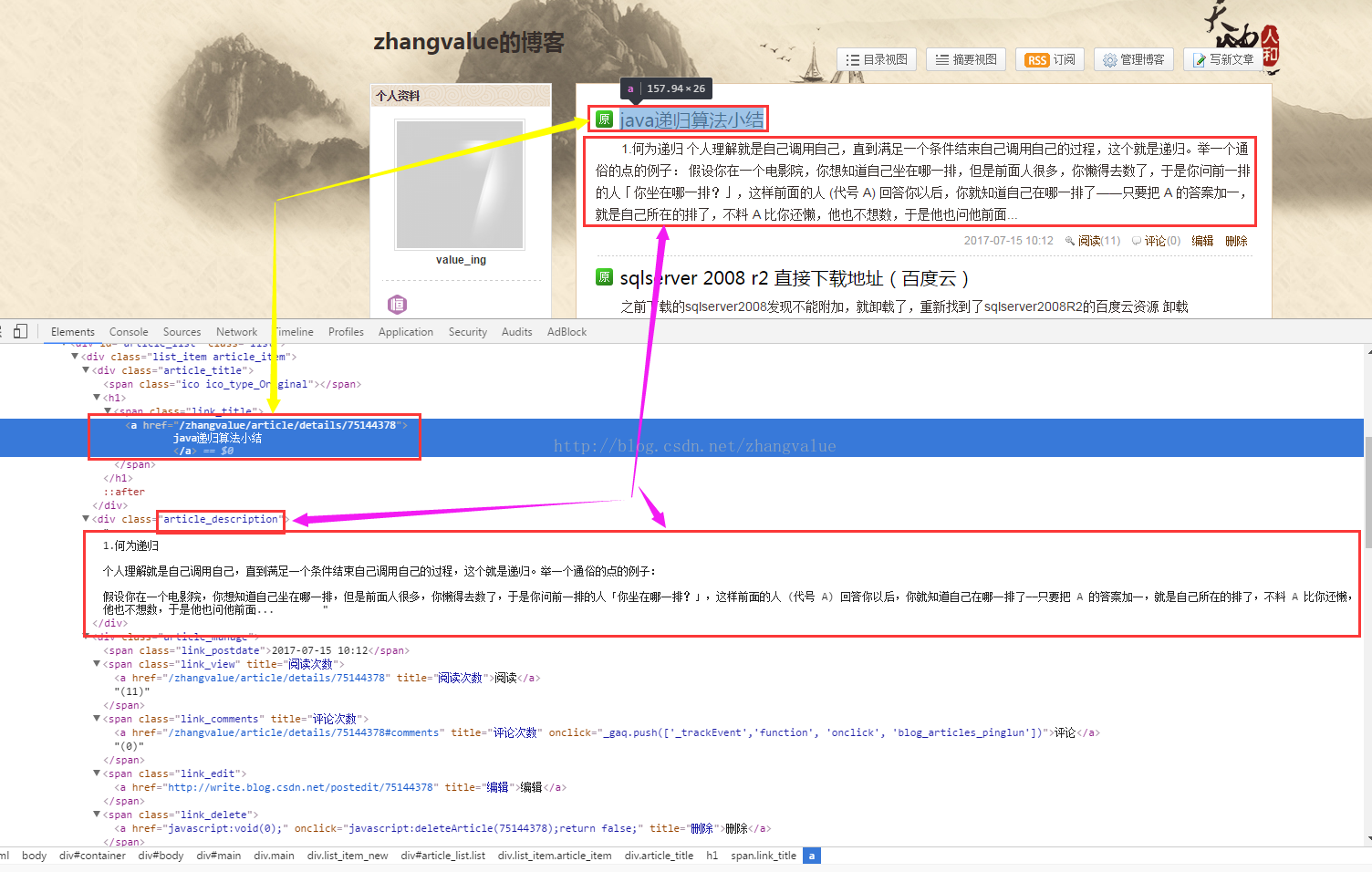
具体实现代码如下:
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class Warms {
public static void main(String[] args)throws IOException {
String url2 = "http://blog.youkuaiyun.com/zhangvalue";
Connection conn = Jsoup.connect(url2); // 建立与url中页面的连接
Document doc = conn.get(); // 解析页面
Elements links = doc.select("a[href]"); // 获取页面中所有的超链接
int i = 1;
for (Element link : links) {
if ("评论".equals(link.text())) { // 获取页面中每篇文章‘评论’的链接,进入文章
Document doc2 = Jsoup.connect(link.attr("abs:href")).get(); // 解析每篇文章的页面
System.out.println("第" + i + "篇:" + doc2.title()); // 把该文章的标题打印出来
i++;
}
}
int j=1;
Elements divs = doc.select(".article_description"); // 获取页面中article_description类的div
for (Element div : divs) {
System.out.println("第" + j + "篇:" + div.text()); // 把该文章的摘要打印出来
j++;
}
}
}
最终效果: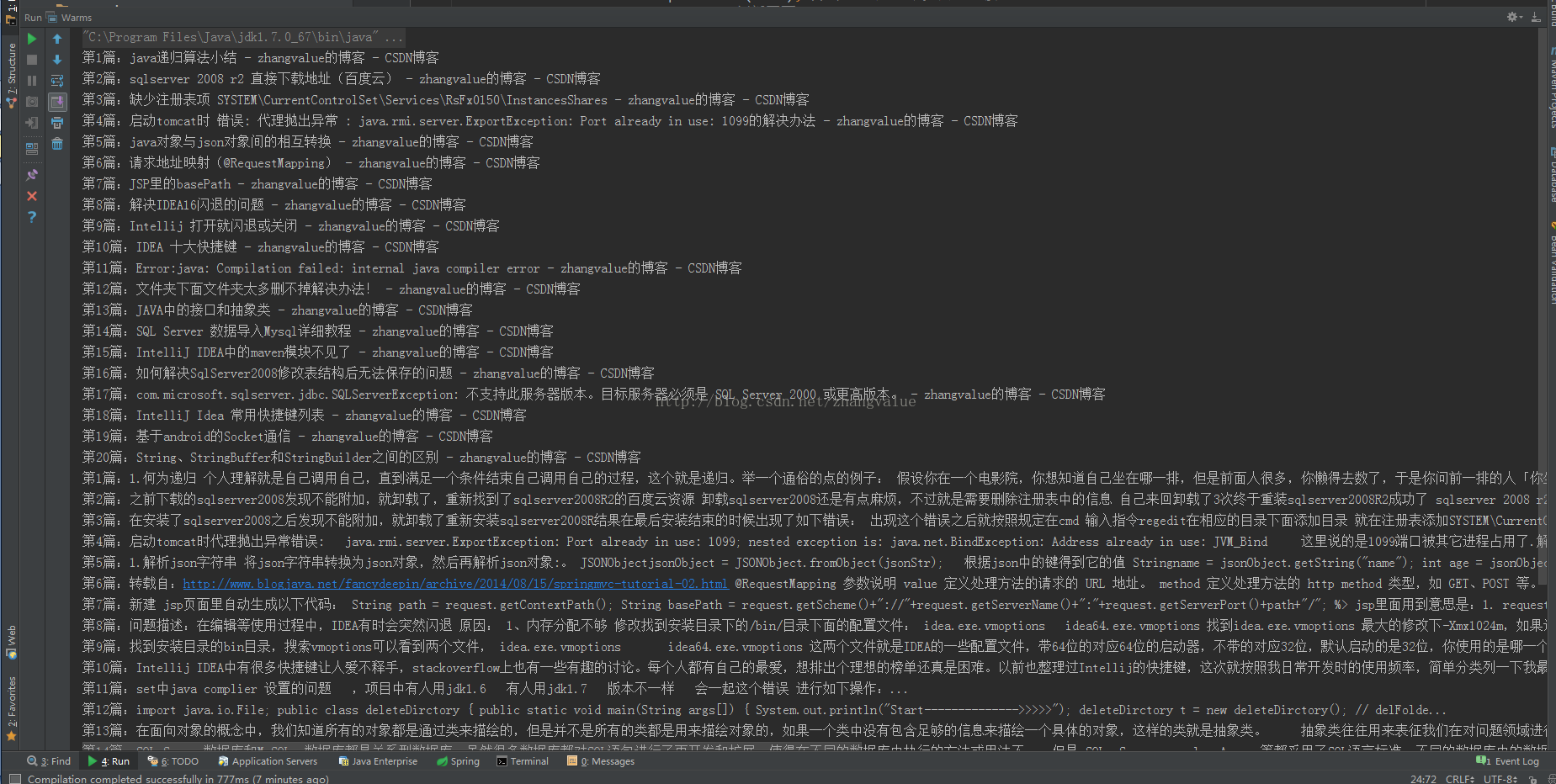
注意事项:需要的jar包最好是配置maven最方便
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.7.2</version>
</dependency>
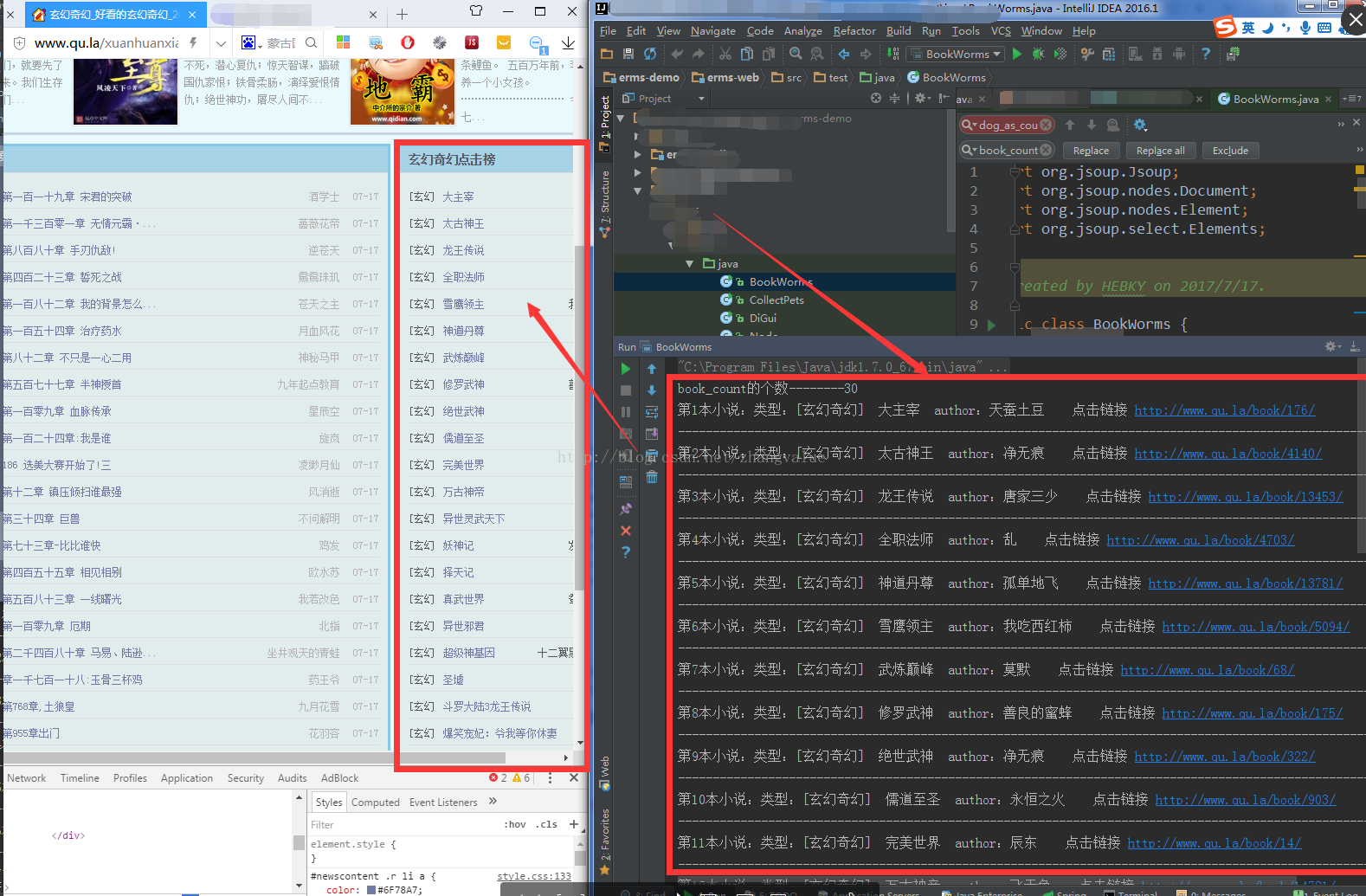
例子二:爬取如下小说网站右边列表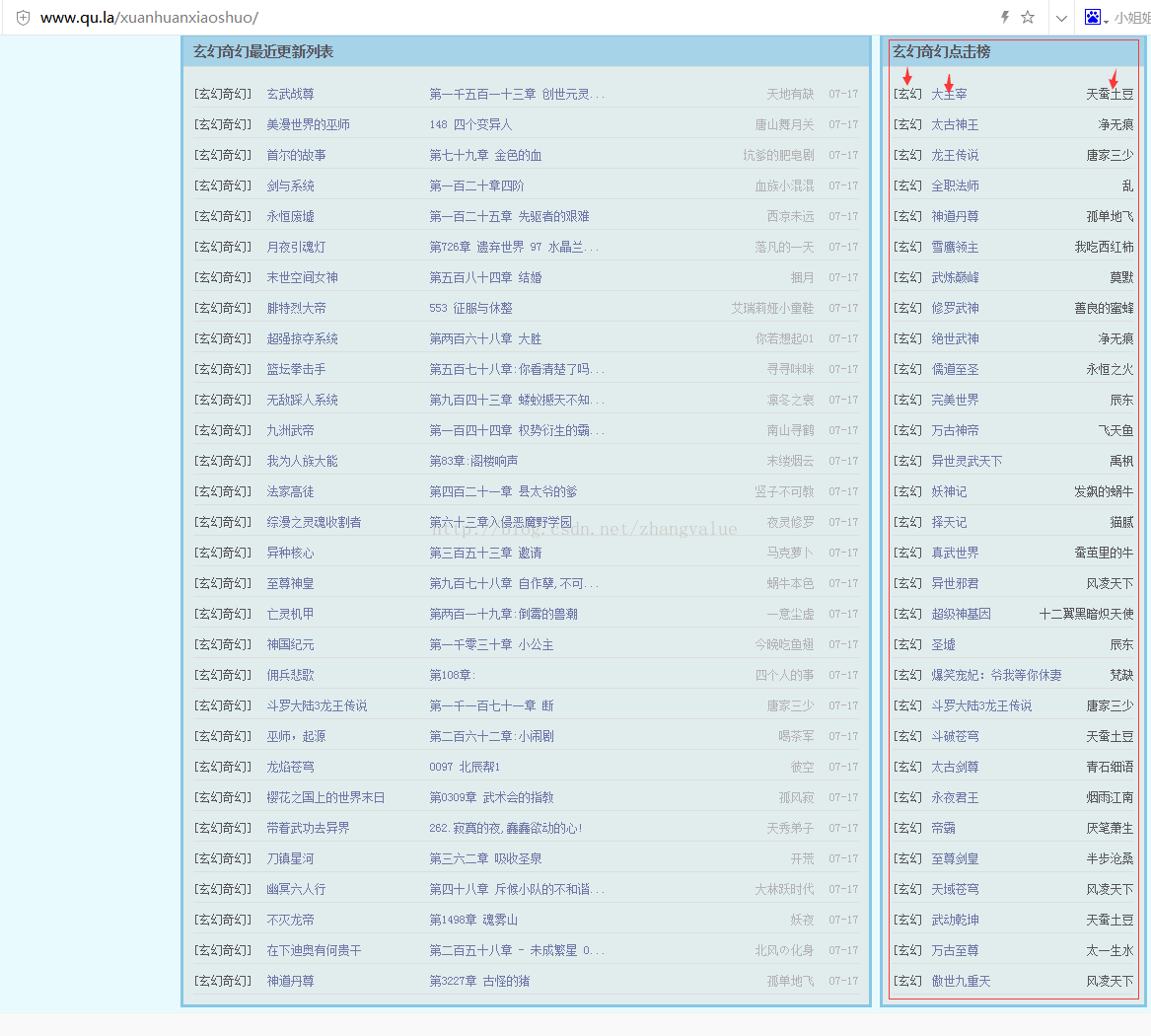
通过查看元素发现了想要爬取的结构如下:
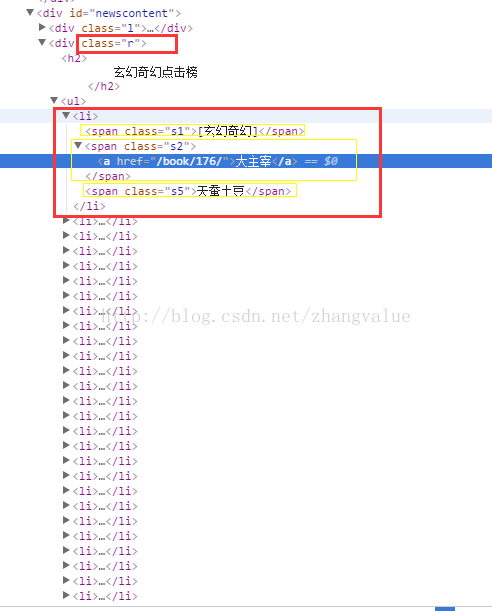
代码如下:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* Created by zhangvalue on 2017/7/17.
*/
public class BookWorms {
public static void main(String[] args) {
try {
Document html = Jsoup.connect("http://www.qu.la/xuanhuanxiaoshuo/")
//timeout里面的值我写的大,
.timeout(100000).get();
// 所有注释对应着网页查看(检查元素)
// 首先拿到类名为r的div里的所有数据
Elements div_content = html.select(".r");
// 然后拿到div中所有的li标签,就是相对应的所有玄幻小说的列表
Elements lis = div_content.select("li");
int book_count =lis.size();
System.out.println("book_count的个数--------"+book_count);
int i = 1;
for (Element element : lis) {
Element ele = element.getElementsByAttributeValue("class","s5").first();
//寻找属性为指定值的元素。不区分大小写。(下面的S1为s1也一样)
Element ele2 = element.getElementsByAttributeValue("class","s1").first();
String sort = ele2.text();
String author = ele.text();
//或者使用selectElement link = element.select("a").first();
Element link = element.getElementsByTag("a").first();
String absHref = link.attr("abs:href"); //使用 abs: 属性前缀来取得包含base URI的绝对路径
//String href = link.attr("href");
String name = link.text();
System.out.println("第"+i+"本小说:"+ "类型:"+sort+" "+ name+" "+"author:"+author+" "+"点击链接"+" "+absHref);
System.out.println("-----------------------------------------------------------------------------------------------------");
i++;
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
实现效果如下:


















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











