




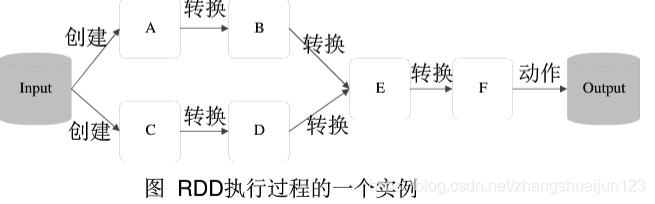
RDD的执行过程
(1)RDD读入外部数据源进行创建
(2)RDD经过一系列的转化(Transformation)操作,每一次会产生不同的RDD,供给下一个转化操作使用
(3)最后一个RDD经过”动作“操作进行转化,并输出到外部数据源
这一系列的操作称为一个Lineage(血缘关系),即DAG拓扑排序的结果
优点:
惰性调用,管道化,避免同步等待,不需要保存中间的结果,每次操作简单
RDD的运行原理
最新推荐文章于 2022-06-14 00:05:10 发布
RDD的执行过程
(1)RDD读入外部数据源进行创建
(2)RDD经过一系列的转化(Transformation)操作,每一次会产生不同的RDD,供给下一个转化操作使用
(3)最后一个RDD经过”动作“操作进行转化,并输出到外部数据源
这一系列的操作称为一个Lineage(血缘关系),即DAG拓扑排序的结果
优点:
惰性调用,管道化,避免同步等待,不需要保存中间的结果,每次操作简单
 862
890
862
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























