



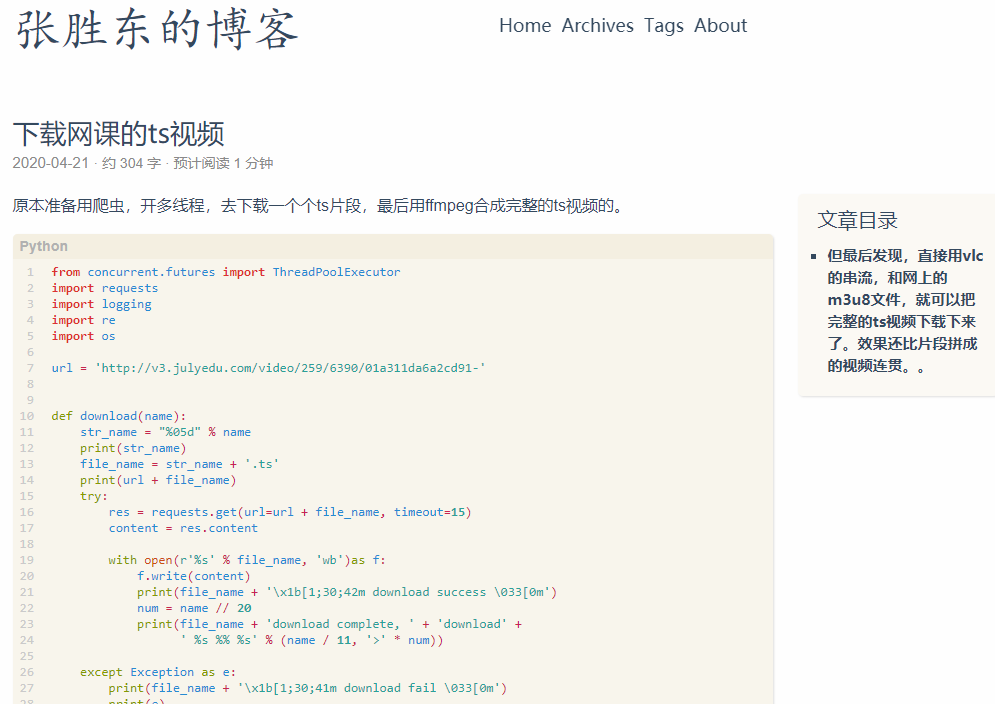
原本准备用爬虫,开多线程,去下载一个个ts片段,最后用ffmpeg合成完整的ts视频的。
from concurrent.futures import ThreadPoolExecutor
import requests
import logging
import re
import os
url = 'http://v3.julyedu.com/video/259/6390/01a311da6a2cd91-'
def download(name):
str_name = "%05d" % name
print(str_name)
file_name = str_name + '.ts'
print(url + file_name)
try:
res = requests.get(url=url + file_name, timeout=15)
content = res.content
with open(r'%s' % file_name, 'wb')as f:
f.write(content)
print(file_name + '\x1b[1;30;42m download success \033[0m')
num = name // 20
print(file_name + 'download complete, ' + 'download' +
' %s %% %s' % (name / 11, '>' * num))
except Exception as e:
print(file_name + '\x1b[1;30;41m download fail \033[0m')
print(e)
name = re.findall('(\d+).ts', file_name)[0]
print(name + ' download fail')
my_log = logging.getLogger('lo')
my_log.setLevel(logging.DEBUG)
file = logging.FileHandler('error.log', encoding='utf-8')
file.setLevel(logging.ERROR)
my_log_fmt = logging.Formatter('%(asctime)s-%(levelname)s:%(message)s')
file.setFormatter(my_log_fmt)
my_log.addHandler(file)
my_log.error(file_name + ' download fail ')
my_log.error(e)
download(int(name))
p = ThreadPoolExecutor(2)
for name in range(1, 556 + 1):
p.submit(download, name)
# win: copy /b *.ts video.ts
# ffmpeg -allowed_extensions ALL -i HdNz1kaz.m3u8 -c copy new.mp4
# https://blog.youkuaiyun.com/weixin_34190136/article/details/85989221但最后发现,直接用vlc的串流,和网上的m3u8文件,就可以把完整的ts视频下载下来了。效果还比片段拼成的视频连贯。。


















 1128
1128




 到【灌水乐园】发言
到【灌水乐园】发言









