







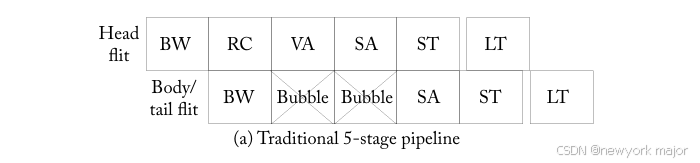
图6.15a显示了basic virtual channel router的logical pipeline stages,其中包含所有 到目前为止讨论过的组件。就像典型处理器的逻辑流水线阶段一样:指令获取、解码、执行、存储和写回,these are logical stages that will fit into a physical pipeline depending on the actual clock frequency。
- 当一个head flit到达输入端口时,它首先在buffer write(BW)pipeline stage, 根据其输入VC进行decode和buffer。
- 接下来,routing logic执行route computation(RC),以确定该paket的输出端口。
- 然后,在VC allocation(VA)阶段,该head flit仲裁一个与其输出端口(即下一个路由器的输入端口)对应的VC。
- 在成功分配VC后,该head flit进入switch allocation(SA)阶段,在此阶段中,it arbitrates for the switch input and output ports。
- 在成功赢得输出端口后,该flit从buffer中读出,然后进入switch traversal(ST)阶段,where it traverses the crossbar.。
- 最后,该flit在link traversal(LT)阶段被传递到下一个节点。
- body and tail flit遵循类似的pipeline,但它们不经过RC和VA阶段,而是继承由head flit分配的route和VC。tail flit在离开router时释放由head flit保留的VC。
没有VC的wormhole router省去了VA阶段,只需要四个逻辑阶段。在图6.1中,这样的router不需要VC分配器,并且在每个输入端口只有一个deep buffer queue。
Pipeline Implementation
The logical virtual channel pipeline consists of five stages.
在低时钟频率下运行的router将能够将所有五个阶段放入一个时钟周期。对于高频router,其架构必须是流水线的。实际的物理流水线取决于每个逻辑阶段的实现及其在该技术中的关键路径延迟。本章后面将讨论每个阶段的实现。
如果物理流水线像逻辑流水线一样有5个阶段,那么关键路径延迟最长的阶段将影响时钟频率的上限。通常,当VC数量很高时,这个阶段在VC or Switch allocation stage,或具有very wide, highly ported crossbars的crossbar traversal stage。时钟频率也可以由整个系统时钟确定,例如由处理器流水线的关键路径确定大小。
增加物理流水线阶段的数量会增加每个消息的per-hop router delay,以及buffer turnaround time,这会影响所需的minimum buffering needed并影响throughput。因此,pipeline optimizations被提出并用于减少阶段数量。下面将解释针对逻辑流水线阶段的常见优化。最先进的router实现可以在单个周期内执行所有操作。
Pipeline Optimizations
所有router的共同目标是使multiple flows能够在共享资源(links and buffers)上进行多路复用。
已经提出了 针对on-chip routers的无数pipeline优化,to help run various logical stages in parallel,从而减少部分/所有routers的cycles。这反过来又节省了latency and energy。Shallow pipelines还可以缩短buffer turnaround time,有助于提高network throughput。
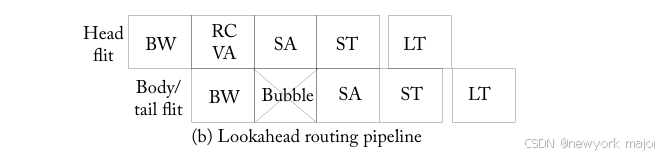
Lookahead Routing
remove the RC stage from the critical path;
packet的route, determined one hop in advance, 并在head flit内编码,使进入的flit在BW阶段后立即竞争VCs/switch。下一跳的route computation可以与VC/switch allocation并行进行,因为其不再需要确定为哪个输出端口进行仲裁。图6 - 15b展示了具有前瞻路由的router pipeline,也称为next route compute(NRC)或routepre-computation。
Low-load bypassing
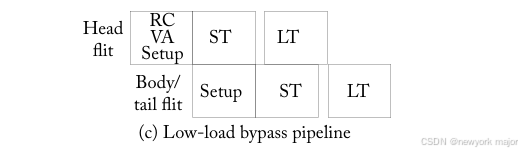
Removes the BW and SA stages from routers that are lightly loaded.
如果input buffer queue中没有其他的flit位于其前面,则允许传入的 flit 推测性地进入 ST 阶段。图6.15c显示了 flit goes through a single stage of switch setup,在此期间,设置crossbar以便在下一个周期中flit traversal,同时分配一个与期望输出端口对应的空闲VC,然后是ST and LT。当输出端口发生冲突时,flit会被写入缓冲区(BW),然后执行SA。
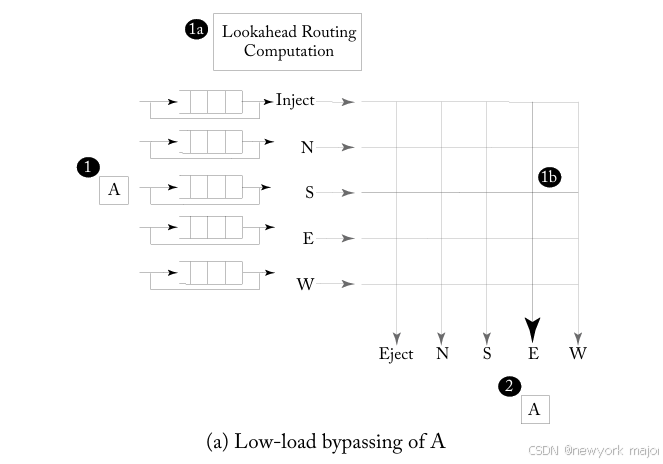
图6.16a展示了low-load bypass的例子。在时间点1,A到达South输入端口,输入队列中没有buffered flit wating。
- 在第一周期(1a)中执行lookahead routing computation,并在
- (1b)中在South输入端口和East输出端口之间建立crossbar connection。
- 在时间点2,A traverses the crossbar并exits ths router。Buffering and allocation are bypassed。
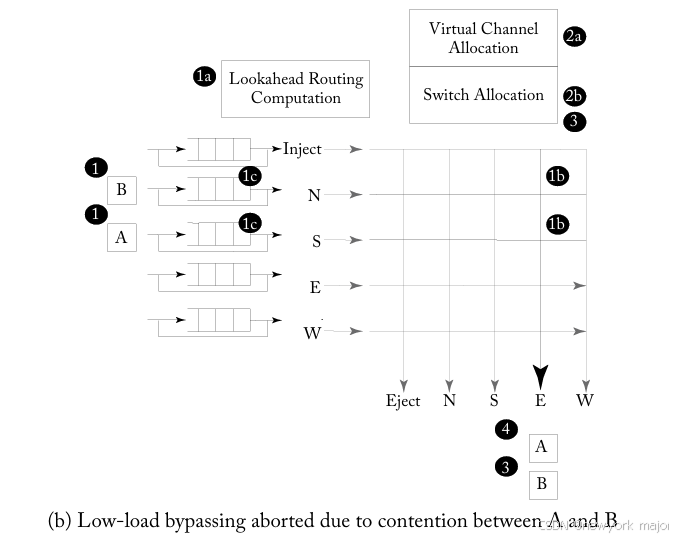
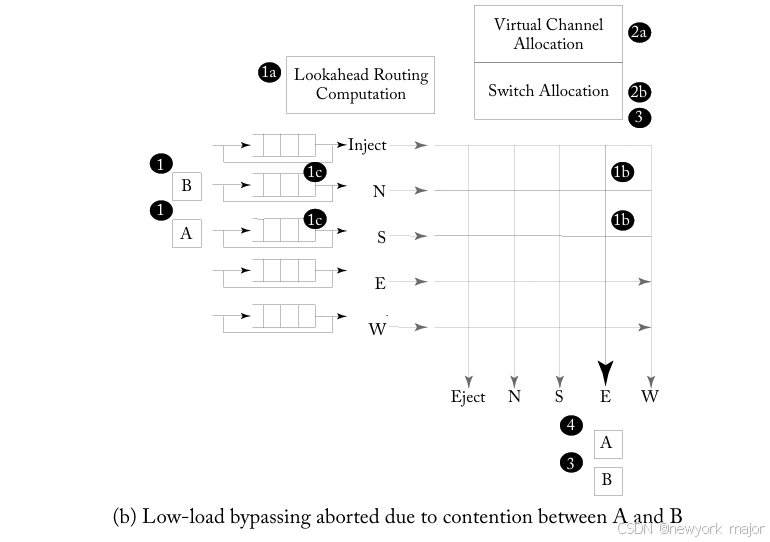
在图6.16b中:
- 在时间点1(南输入端口上的A和北输入端口上的B)同时到达2个flits;
- 它们都有empty input queues,并试图bypass the pipeline。
- 然而,在crossbar setup(1b)期间,检测到端口冲突,因为两个flits都试图setup the crossbar for the East output port。现在,两个flits必须被写入input buffers(1c),并go through the regular pipeline。
Speculative VA
Removes the VA stage from the critical path.
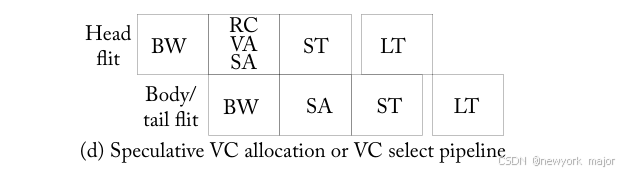
一个flit在BW阶段之后,speculatively的进入SA阶段,同时为switch port进行仲裁,并试图获取一个空闲的VC。如果speculation成功,该flit直接进入ST pipeline stage。但如果speculation失败,该flit必须再次经过这些pipeline stage中的一些,具体取决于speculation失败的位置。图6.15d显示了带有the speculative pipeline(BASE + LA-RC + BY + S-VA)的router pipeline。
在图6 - 16 B中,
- 在步骤2中,At time 2,flit A和B都并行地执行virtual channel and switch allocation(2a和2b)。报文B成功allocates an output virtual channel and the switch,并在
- 时间点3时traverses the switch at Time 3。报文A virtual channel allocation,switch allocation失败。
- 在时间点3时,A将再次尝试allocate the switch。A的请求现在是非推测的,因为它已经获得了一个输出虚拟通道(2a)。
- A的请求成功,traverses the switch and exits the router at Time 4。
VC selection
eliminates the VA stage from the router pipeline。
VC选择背后的思想是,对于buffered的flits来说,a full-fledged VA for multiple output VCs是不必要的,因为在任何周期中只有一个flit可以从输出端口输出。
在每个输出端口维护一个空闲VC id队列。每个输出端口的SA winner被分配到队列头的VCid。head flit只有在其输出端口的空闲VC队列非空时(即下一个router的输入端口至少有一个空闲VC)才进入SA。body和tail可以直接进入SA,无需此检查。
The update of the free VC queue发生在关键路径之外。当存在多个message classes/virtual networks时,每个虚拟网络都需要维护free VC queues,并且SA阶段可以被扩展以适应在每个队列头之间进行选择的额外的mux。
The pipeline is the same as the speculative VC one (Figure 6.15d) except that there is no speculation involved。
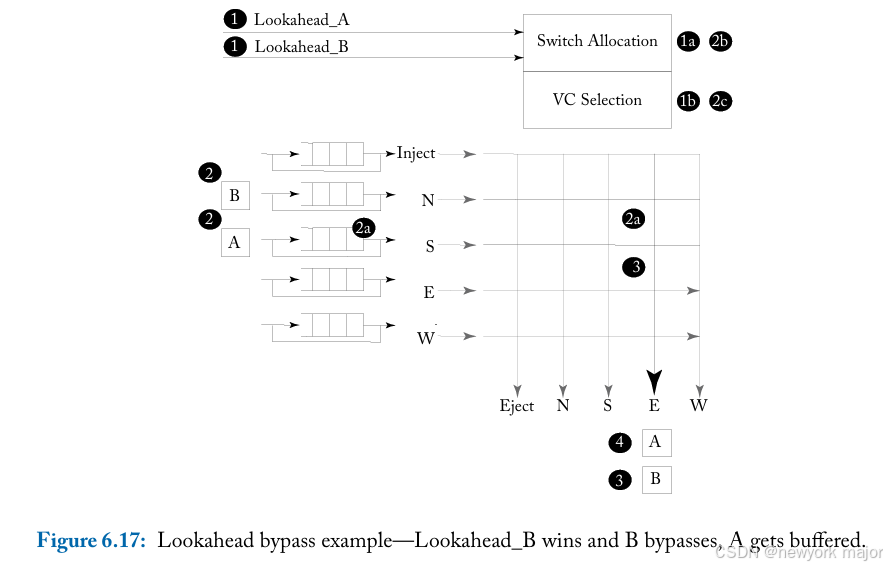
Lookahead bypass
leverages the above optimization to design a single-cycle router.
它从flit traversal的关键路径中删除BW和SA阶段。其思想是,当the flit is traversing the link between the current and next router,perform SA for a flit at the next router。
This is implemented by sending a few bits in advance, called lookaheads to the next router while the flit is in ST.
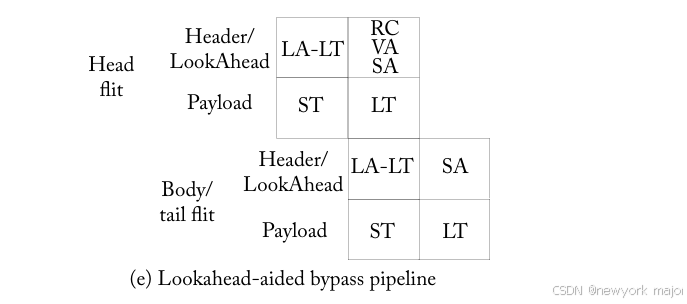
这些lookaheads只是flit的header (route, VCid, etc.),允许信道带宽简单地重新分配,而不需要额外的线路。当flit执行LT时,它的lookahead执行SA at the next router。成功的lookahead仲裁使得其flit可以绕过BW和SA直接进入ST,从而将时延降低到每跳2个周期(ST+LT)。结果如图6 - 15e所示。
这种方法不仅节省了延迟,而且缓冲了读写功耗。如果lookahead arbitration失败,flit会被缓冲并通过正常的管道。被缓冲的flit无论如何都会支付功耗成本,并且如果有一个竞争的超前flit或具有更高优先级的flit,则只会支付额外的延迟惩罚。
Figure 6.17 shows an example where two lookaheads arrive at the router in Cycle 1.
- B的lookahead赢了switch allocation,选择了VC;flit B绕过buffer,直接进入switch。
- 因为A的lookahead失败了,所以flit A得到了缓冲;
- A在第2轮完成switch allocation和VC选择,在第3轮完成switch traversal。
State-of-the-art
networks can be designed today at modern technologies that spend a S single-cycle for switch arbitration and VC selection in the router, and the subsequent cycle for traversing both the switch and link , while operating at GHz frequencies. This enables two-cycles per-hop traversal (at no contention)

















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









