







Flow control决定着network buffer和links的分配。它决定何时将buffer和link分配给消息、分配的粒度以及如何在使用network的众多消息之间共享这些资源。
一个好的flow control protocol会通过不在resource allocation中产生高开销,从而降低low loads下消息所经历的延迟,并通过在消息之间有效共享buffer和link来提高网络吞吐量。在确定packet访问buffer(或完全跳过缓冲区访问)和traverse link的速率时,flow control对于确定网络能量和功耗至关重要。flow control protocol的实施复杂性包括router microarchitecture的复杂性以及在router之间传递资源信息所需的布线开销。
MESSAGES,PACKETS,FLITS,ANDPHITS
当message被注入network时,它首先被setment into packets,然后被分成fixed-length flits,这个过程称之为flow control flit。
例如,a 128-byte cacheline sent from a sharer to a requester, 将injected as a message,如果最大packet size大于 128 字节,则整个message将被编码为as a single packet。packet将由:
- 包含目标地址的head flit、
- body flit
- 指示数据包结束的tail flit 组成。
Flit可以进一步细分为phits,它们是物理单元,对应于物理通道宽度。
图 5.1a 显示了message到packet, packet到flit的细分过程。
head、body和tal flit 都包含cache line和cache coherence command的部分内容。每个 flit 还包含某些控制信息,例如flit类型和虚拟通道号。
- 例如,如果 flit 大小为 128 位,则 128 字节数据包将包含 8 个 flit:1 个头部、6 个主体和 1 个尾部,忽略extra bits needed to encode the destination and other information needed by the flow control protocol。
简而言之:
- message is the logical unit of communication above the network
- packet is the physical unit that makes sense to the network
packet包含目的地信息,而flit可能不包含,因此packet的所有flit必须采用相同的路由。
由于片上布线资源丰富,片上网络中的信道往往更宽,因此message往往由单个packet组成。在off-chip networks中,通道宽度受到引脚带宽的限制;这个限制导致flit被分解成更小的块,称为phit。到目前为止,在片上网络中,由于片上信道较宽,flit由单个phit组成,是message的最小细分。此外,如图5 - 1所示,许多消息实际上是single flit组成。例如,一致性命令只需要携带一个16字节宽的flit所能容纳的命令和内存地址。
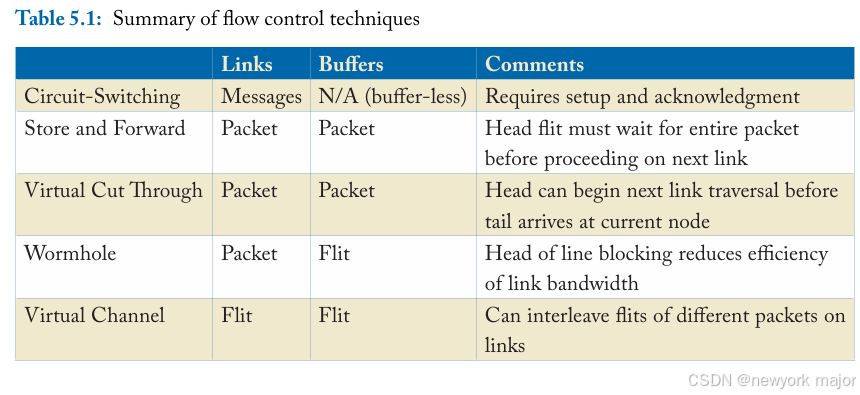
Flow control techniques按照资源分配的粒度进行分类。我们将在下一节中讨论在消message, packet, flit粒度上操作的技术,并在最后给出一个表来总结每种技术的粒度;

Message-based flow control
我们从circuit-switching开始,这是一种在最粗粒度的消息级别上操作的技术,然后将这些技术细化到更细的粒度。
CIRCUIT SWITCHING
Circuit switching会预先申请多个跳转中的资源(links)以传输整个message。
将probe(a small setup message)发送到network中,并reserve 将整个message(或multiple message)从src-dst所需的links。一旦probe到达目的地(having successfully allocated the necessary links),目的地就会将ack message发送source。当src收到ack message时,它会开始发送message,然后该message可以快速通过网络传播。一旦消息完成traversal,就会释放资 源。
setup phase之后,per-hop latency to acquire resources is avoided。
With sufficiently large messages,这种延迟减少可以分摊原始设置阶段的成本。除了可能的延迟优势之外,circuit switching也是bufferless的。由于links是预先保留的,因此不需要在每个跳转处设置buffers来保存等待分配的数据包,从而节省了功耗。虽然可以减少延迟,但circuit switching的带宽利用率很差。setup and the actual message transfer之间的links处于空闲状态,并且试图使用这些资源的其他消息将被阻止。
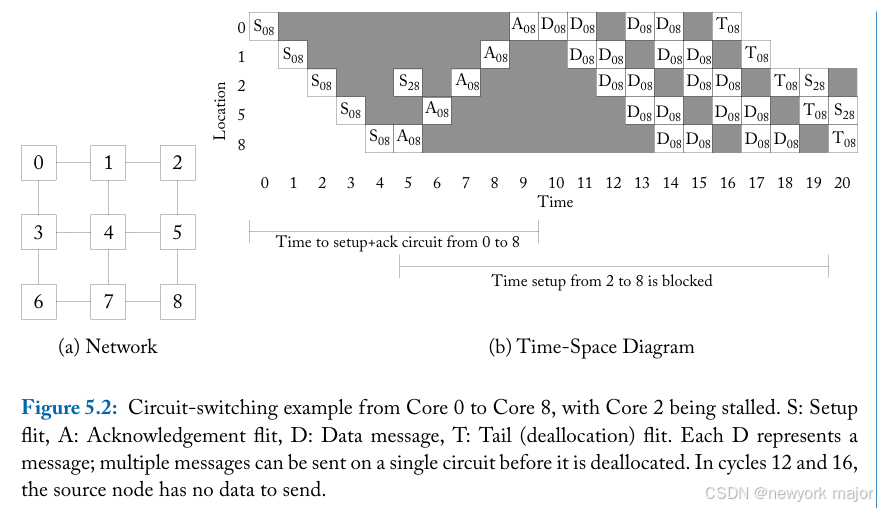
图5 - 2举例说明了circuit-switching flow control的工作原理。图5.2a所示的网络假设维度序X-Y routing。随着时间从左向右推移(图5 - 2b),
- setup flit S通过traversing network中选定的路径来构造一个从core 0到core 8的circuit。
- at time 4,setup flit已经到达目的地,并开始发送一个ack flit,返回到core 0。
- at time 5,core 2想要向core 8发起一次transfer;
- 然而,到达core 8所需的资源(links)已经分配给了core 0。因此,core 2的请求被stalled。
- at time 9,core 0接收到ack request,然后数据传输,D可以开始。
- 一旦发送了所需的数据,core0 发送tail flit来deallocate这些resources;
- at time 19,core 2现在可以开始acquire tail flit最近释放的资源。
从这个例子中,我们可以看到有大量的链路带宽被浪费。在setup time时,links has been reserved,但没有数据需要传输,这些link是空闲的,但对其他message不可用(浪费的链路带宽用灰色表示)。core 2在等待大部分空闲资源时也有明显的延迟;
异步传输模式 (ATM) establishes virtual circuit connections;在发送数据之前,必须从源到目的地保留network resources (如circuit switching)。但是,数据在网络中以packet粒度而不是message粒度进行switched。
Packet-based Flow control
Circuit-switching为message分配资源,and does so across multiple network hops。 这种方案存在一些低效之处;接下来,我们来看看为allocate resources to packets的方案。基于packet的flow control techniques首先将message分解为packet,然后在link上interleave这些packets,从而提高links利用率。
与Circuit-switching不同,the remaining techniques will require per-node buffering to store in-flight packets。
STORE AND FORWARD
使用packet-based techniques,message被分解成多个multiple packets,每个packet由网络独立处理。在store-and-forward flow control 中,每个节点都等到收到整个packet后才将packet的任何部分转发到下一个节点。因此,每一跳都会产生较长的延迟,这使得它们不适合通常对延迟至关重要的片上网络。此外,store-and-forward flow control 要求每个router都 有足够的缓冲来buffer整个packet。这些high buffering requirements降低了store and forward switching’s amenability to on-chip networks.
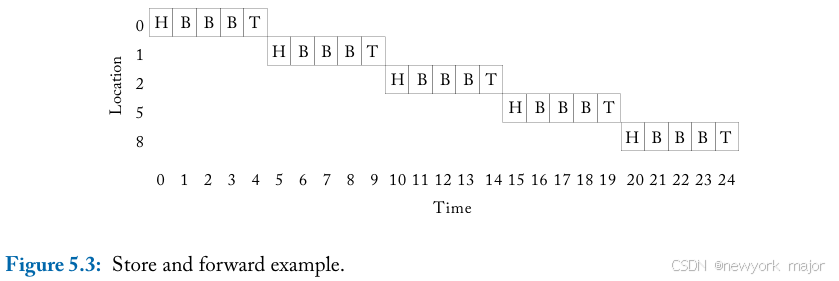
在图5.3 中,我们描述了一个packet使用store and forward switching从core 0传输到core 8。一旦tail flit 在每个节点缓冲完毕,head就可以alloc下一个link并前往下一个router。Serialization delay is paid for at each hop for the body and tail flits to catch up with the head flit.。对于5个flit的packet, 在每次跳跃中传输packet的延迟为5个周期。
VIRTUAL CUT-THROUGH
为了减少packet在每一跳所经历的延迟,virtual cut-through flow control允许整个packet在到达当前router之前,就开始之前已经窗户来的部分packet到下一节点;
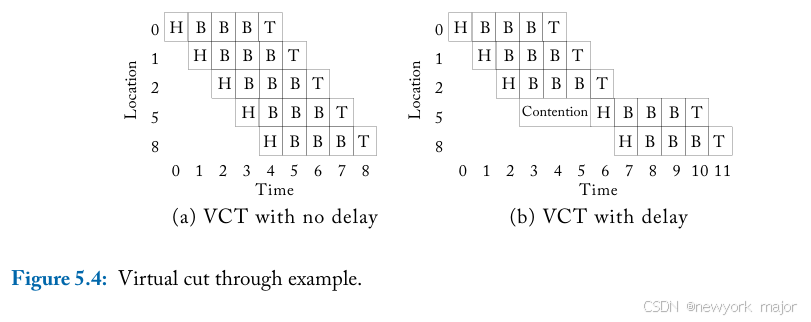
因此,与store and forward f lowcontrol相比,packet所经历的延迟大大减少,如图5.4a 所示。在图5.3 中,传输整个数据包 需要 25 个周期;使用virtual cut-through,此延迟减少到 9 个周期。但是,bandwidth and storage仍然以packet大小为单位分配。只有当next downstream router有足够的存储空间来容纳整个packet时,packet才会继续向前移动。当packet很大(例如64或128字节cacheline)时,面积和功率限制严格的片上网络可能难以容纳支持虚拟直通所需的大缓冲区。
在图5.4b 中,尽管node 5 有2个flit的缓冲区可用,但从node 2 到node 5时整个packet都会延迟。除非所有5个flit缓冲区都可用,否则任何flit都无法继续。
FLIT-BASED FLOW CONTROL
为了降低packet-based techniques的buffering要求,存在flit-based flow control机制。Low buffering要求有助于router满足片上严格的面积 或功率限制。
- WORMHOLE
与virtual cut-through flow control类似,wormhole flow control可以直通flit,允许flit在当前位置接收到整个packet之前移动到下一个router。 对于wormhole flow control,只要相对于当前的这个flit, 有足够的缓冲空间,flit就可以离开当前节点。
但是,与store-and-forward and virtual cut-through flow control不同,wormhole flow control将storage and bandwidth分配给flit而不是整个数据包。这允许在每个router中使用相对较小的flit buffer,即使对于较大的packet也是如此。虽然wormhole flow control有效地使用了bufferings,但它对link bandwidth的利用效率很低。
虽然它以flit大小的单位分配storage and bandwidth,但link在router中会保留packet的整个生命周期。因此,当packet is blockd,该packet所持有的physical links都处于空闲状态。由于wormhole flow control以flit粒度分配buffer,因此由许多flit组成的数据包可能 会跨越多个router,这将导致许多空闲的physical links。吞吐量会受到影响,因为排队在被阻止的packet后面的其他packet无法使用空闲的物理链路。
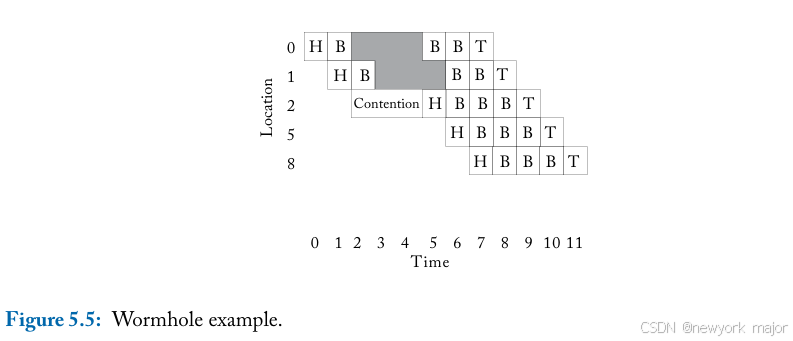
在图 5.5 的示例中,每个路由器都有 2 个 flit buiffers。当head flit 在从 1 到 2 的传输过程 中遇到contention时,其余两个body 和tail flit 会停滞在core 0,因为在head移动到core 2 之前,core 1 上没有可用的缓冲区空间。但是,即使packet处于空闲状态(如灰色所示),通道仍由数据包 占据。
Wormhole flow control允许 flit 在下游缓冲区可用时立即离开router,从而减少packet延迟(在 没有contention的情况下,延迟与virtual cut through相同)。此外,与packet-based techniques相比,wormhole flow control可以使用更少的buffers来实现。由于片上网络的面积和功耗限制严格,wormhole flow control是迄今为止采用的主要技术。
VIRTUAL CHANNELS
虚拟通道被解释为互连网络的“瑞士军刀” 。 它们最初是作为避免死锁的解决方案提出的,但也被应用于缓解流量控制中的队首阻塞(mitigate head-of-line blocking in flow control),从而提高吞吐量。
Head-of-line blocking(队头阻塞)发生在上述所有流量控制技术中,其中每个输入都有一个queue;当queue的头部的packet被阻塞时,它会阻止排队阻塞的后续packet, 即使对于后续的stalled packet来说,resource是足够的;
本质上,一个虚拟通道(VC)基本上是router的一个独立queue;多个VCs 虚拟通道共享两个router之间的物理线路(physical links)。通过为每个输入端口关联多个独立的队列,可以减少队首阻塞。虚通道对physical link bandwidth进行周期性的仲裁。当一个hold 虚通道的packet被阻塞时,其他packet仍然可以通过其他虚通道traverse物理链路。因此,VCs提高了物理链路的利用率,扩大了网络的整体吞吐量。
从技术上讲,VC 可以应用于上述所有流量控制技术,以缓解队头阻塞,尽管 Dally 首先提出了Wormhole flow control。例如,
- circuit switching 可以应用于虚拟通道而不是物理通道,因此一条消息reserves一系列 VC,而不是物理链路,并且 VC 是时间复用的, 逐周期地将数据包发送到物理链路上,也称为virtual circuit switching。
- Store-and forward flowcontrol也可以与 VC 一起使用,具有多个packet buffer queue,每个 VC 一个, VCsmultiplexed on the link packet-by-packet。
- 使用 VC 的Virtual cut-through flow control类似地,except that VCs are multiplexed on the link flit-by-flit.。
然而,作为片上网络由于wormhole flow control面积小、功耗低,因此大多数设计都采用wormhole flow control。 并使用虚拟通道在需要时扩展带宽,对于本书的其余部分,当我们提到虚拟通道流量控制,我们假设它应用于wormhole flow control,同时buffer和link以flit的粒度进行管理和多路复用。
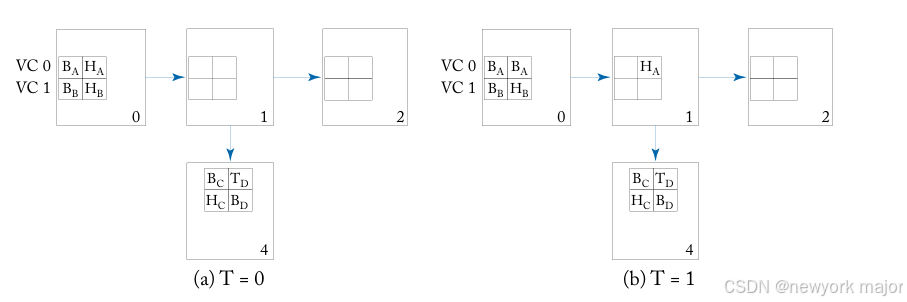
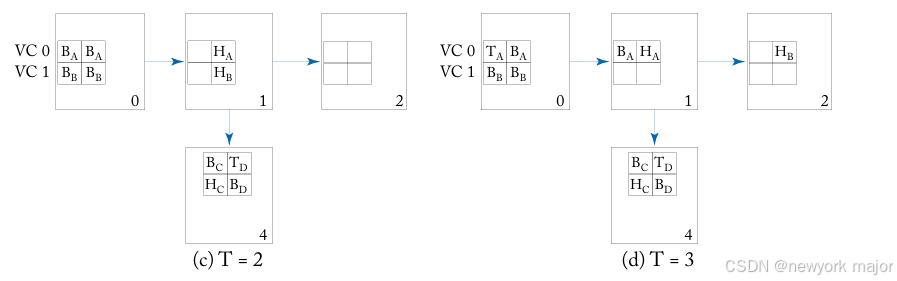
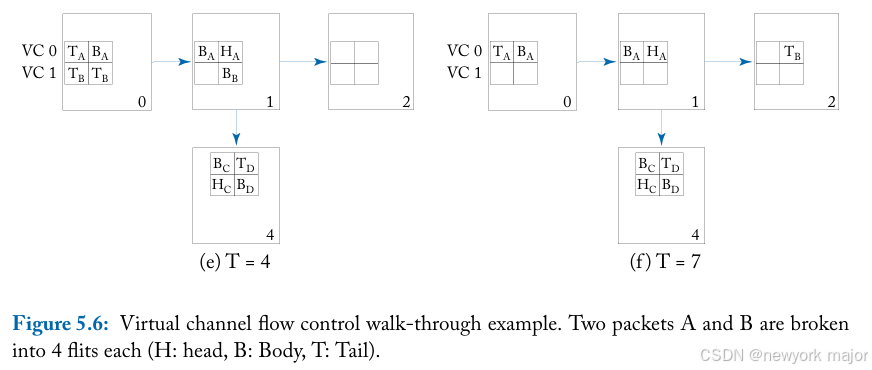
图 5.6 显示了virtual channel flow control操作的演示示例。
- packet A 最初占用VC 0并发往node 4,而packet B 最初占用VC1,目的地为node 2。
- 在时间点0,packet A 和 B 都具有在节点 0 的west input virtual channel中等待的flits。
- Both A and B want to travel outbound on the east output physical channel。
- packet A的head flit, allocated 虚拟通道0,用于router 1的east output和 wins switch allocation(处理此分配的技术是 在第 6 章中讨论过)。
- 在时间点1, A 的header传到router 1。
- 在时间点2:
- packet B的headeris granted switch allocation,并travel到router 1,并存储在虚拟 通道 1。
- A 的header flit fails to receive a virtual channel for router 4(其下一个 hop), 两个虚拟通道都被其他数据包的 flit 占用。
- 在时间点3:
- A 的第一个body flit inherits虚拟通道 0,并在时间3到达router1。
- B 的header flit能够在router 2上分配虚拟通道0并继续。
- 在时间点4,packet B 的第一个body flit 从header flit inherits虚拟通道 1,并wins switch allocation to continue to router 1。
- 在时间点7, all of the flits of B have arrived at router 2,header和body flit继续运行,tai flit仍有待路由。packet A的header 仍然被阻塞,等待空闲的虚拟通道to travel to router 4;
使用单个虚拟通道进行wormhole flow control时,packet B 将被block在router 1, 落后于packet A,不能往router 2 发送,尽管此时buffers,links and switch都可用。多个虚拟通道的设计,允许packet B 继续向其dst发送, 尽管此时packet A 被阻塞。virtual channel在每个router上分配一次 到head flit,其余 flit 继承该虚拟通道。With virtual-channel flow control,不同packet的flit可以交错在同一个物理信道上,如上图中的 时间 0 和 2 之间的示例。
虚拟通道也被广泛用于打破网络内的死锁(见 5.6节),以及处理系统级或协议级死锁(参见2.1.3 节)。 前面几节解释了不同的技术如何处理资源分配 和利用。这些技术总结在表5.1 中。
Deadlock-Free Flow Control
Deadlock freedom,可以通过使用constrained routing algorithms来确保no cycles ever occur(参见第4章),或者通过使用deadlock-free flow control,它允许使用任何路由算法。
Dateline and VC Partitioning
图5.7说明了当routing protocol允许循环时,如何使用两个虚拟通道来打破网络中的循环死锁。在这里,由于每个VC都与一个独立的buffer queue相关联,并且每个VC逐个周期地时间复用到物理链路上,因此持有一个VC意味着持有与其相关联的缓冲队列,而不是锁定一个物理链路。通过对这些VC施加一个顺序,使得较低优先级的VC无法请求和等待较高优先级的VC,从而可以避免资源使用中的循环。在图5.7中,所有消息都通过VC 0发送,until they cross the dateline。After crossing the dateline,消息被分配到VC 1,并且在整个网络穿越过程中的任何时候都不能再分配给VC 0。这确保了通道依赖图(CDG)是无向图的。
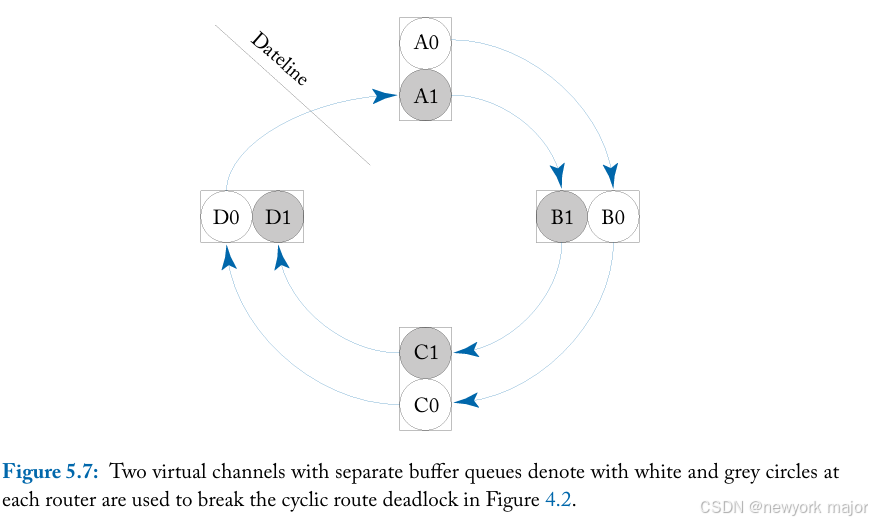
同样的思想也适用于允许所有转弯的oblivious/adaptive routing algorithms,这些算法容易陷入死锁状态。一种随机选择X-Y和Y-X路由的路由算法可以通过强制所有X-Y包使用VC 0和所有Y-X包使用VC 1来避免死锁。同样,那些为了实现路径多样性而允许所有转弯的路由算法可以通过在VC 0中实现一种转弯模型并在VC 1中实现另一种转弯模型来避免死锁,并且不允许在穿越过程中来自同一VC的包跳转到另一VC。
在系统级,可能相互阻塞的message可以被分配到不同的message classes,这些message classes在网络中被映射到不同的虚拟通道上,例如一致性协议的request and acknowledgment消息。这些设计通过将所有可用的VC分为多个类来扩展到多个VC,并在这些类之间强制执行上述排序规则。在每个class中,flits可以使用任何VC。有关virtual channel routers的实现复杂性将在第6章中详细讨论router微架构。
Escape VCs
上一节讨论了通过enforcing ordering between VCs来防止死锁的好处。然而,enforcing an order on VCs会降低它们的利用率,when the number of VCs is small,会影响网络吞吐量。如图5.7所示,all packets最初都被分配到VC 0上,并且一直保持在VC 0上,until they cross the dateline。因此,VC 1的利用率较低。
Duato提出了Escape VCs来解决这个问题。Duato证明,对于无死锁的路由算法,无向循环CDG是一个充分但不必要的条件;即使CDG是循环的,只要存在无向循环子图,就可以使用它来逃脱循环依赖。这个acyclic connected sub-part of the CDG定义了一个escape virtual channel。因此,与其在所有VCs之间强制固定的顺序/优先级,不如设置一个escape VC是无死锁的,其他所有VCs都可以使用完全自适应的路由,无需任何路由限制。
这个escape VC通常通过在内部使用deadlock-free routing function来实现无死锁。例如,如果将VC 0指定为逃生通道,那么所有通过VC 0的流量都必须使用dimension-ordered routing,而其他所有VC都可以使用任意路由函数。简单来说,只要对VC的访问得到公平仲裁,每个数据包都有机会到达逃生VC,从而摆脱死锁。逃生VC有助于提高VC的利用率,或者允许在较少的VC数量下实现更高的吞吐量,从而使路由器更加精简。
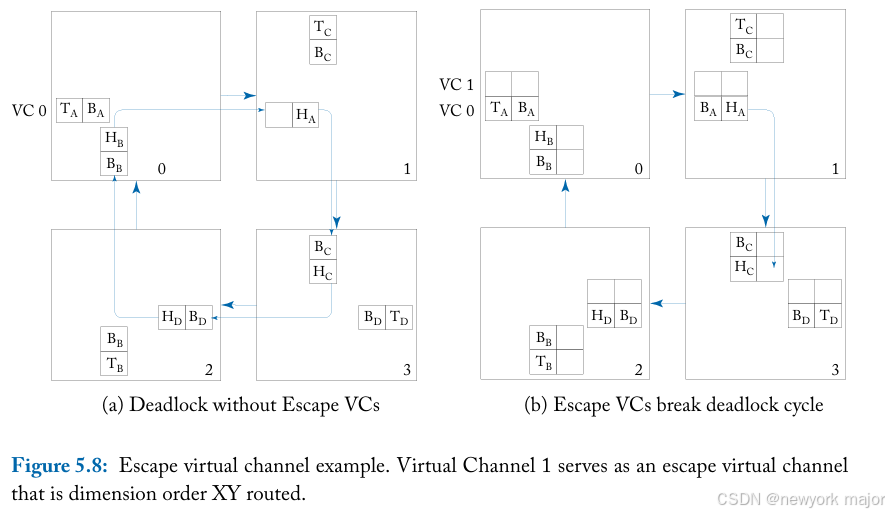
如图5.8a所示,仅使用一个虚拟通道的无约束路由可能会导致死锁。每个数据包都在试图获取资源以绕行一圈。如图5.8b所示,使用了两个虚拟通道。虚拟通道1用作逃生虚拟通道(应该是所有router的vc1, 都是逃生通道,否则跟正常vc没啥区别)。例如:
- packet A可以分配虚拟通道1(并因此按DOR到目的地)。
- 通过为packet A在router 4分配虚拟通道1,所有数据包都可以继续前进。
- packet A的flit最终会从router 1的VC 0中耗尽,从而允许packet B在router 1上分配任意一个虚拟通道。
- 一旦packet B的flit耗尽,packet D可以在虚拟通道0上继续传输,或者分配到虚拟通道1上,并在packet B耗尽之前继续传输。
- 同样,packet C的分组也是如此。
Bubble flow control
在不需要多个VC class的情况下,避免死锁的另一种方法是确保缓冲区之间的封闭循环依赖关系永远不会在运行时创建。由于在每个维度上都存在环形网络,k-ary,n-cubes 容易死锁。即使在使用DOR等无死锁路由时,ring 型网络也会产生循环依赖。
Bubble Flow Control与virtual cut-through相结合,在k-ary,n-cubes网络中提供deadlock free dom。当前在特定维度内传输的packet通过virtual cut-through flow control进行正常处理。需要injected into the network或change dimensions的packet 则based on bubble flow control进行处理,可以控制injection into the ring,以确保不创建闭合的循环依赖关系。只有在环中有容纳两个数据包的empty buffer时,packet才能被注入。
- 为两个packet预留empty buffer space,保证了如果packet被注入,环中仍然会有一个空的flit buffer。这个empty buffer被称为气泡(bubble),它确保环中至少有一个flit能够继续前进,从而防止循环产生。
图5 - 9展示了一个R1有两个empty bubbles的例子,这两个bubble将允许flit P1被注入。其余的router只有一个自由气泡,每个pteventing the injection of P0和P2。该规则同样适用于改变维度的数据包,它被认为是注入到新维度。
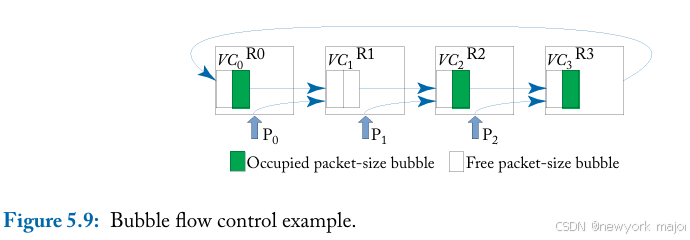 由于在环中搜索所有缓冲区的复杂性,bubble flow control要求在本地队列中有两个空的flit缓冲区,以便注入一个flit。这增加了对最小缓冲区大小的要求,这对于在片上网络中保持低面积和功耗是不可取的。最近的工作探索了将bubble flow con trol应用于wormhole switching,以减少buffer需求,并使其与片上网络更兼容。
由于在环中搜索所有缓冲区的复杂性,bubble flow control要求在本地队列中有两个空的flit缓冲区,以便注入一个flit。这增加了对最小缓冲区大小的要求,这对于在片上网络中保持低面积和功耗是不可取的。最近的工作探索了将bubble flow con trol应用于wormhole switching,以减少buffer需求,并使其与片上网络更兼容。
Buffer Backpressure
由于大多数片上网络设计无法容忍数据包丢失,因此必须有buffer backpressure机制来stalling flit。如果下一跳 没有可用的buffer来容纳 flit,则不得传输 flit。buffer backpressure的单位取决于特定的流量控制协议;
- store-and-forward和virtual cut-through flow control以packet为单位管理buffers,
- 而wormhole and virtual channel flow control以 flit 为 单位管理buffers。
- Circuit switching是一种无缓冲流量控制技术,不需要buffer backpressure mechanisms。
两种常用的缓冲区背压机制是信用和开/关信令。
Credit-based
Credits跟踪下一跳可用的缓冲区数量,方法是当buffer空出时(当 flit/packet离开router时)向前一跳发送credit,并在收到credit后增加前一跳的credit count。当 flit 离开当前router时,当前router会减少相应下游buffer的credit count。
On/off
On/off 信号涉及相邻router之间的信号,when the number of buffers drop below a threshold,该信号将被关闭以阻止前一跳传输flit。 必须设置此阈值以确保所有正在传输的 flit 在到达时都有buffer。
在关闭信号的传输延迟期间,必须有buffer可供离开当前router的 flit 使用。当下游router的空闲buffer数量超过阈值时,信号将打开,flit 传输可以恢复。
The on threshold should be selected so that the next router will still have flits to send to cover the time of transmission of the on signal plus the delay to receive a new flit from the current router.
Implemention
flow control protocol的实现复杂性主要涉及整个router微架构的复杂性以及在router之间传递资源信息时 产生的布线开销。这里我们重点讨论后者,因为第6章将详细介绍router微架构及其相关的实现问题。
当选择特定的buffer backpressure mechanism时,我们需要考虑其buffer turnaround time方面的性能,以及reverse signaling wires数量方面的开销。
Buffer Sizing For Turnaroud Time
Buffer turnaround time是连续的flits可以重用buffer的最小空闲时间。
Buffer turnaround time过长导致buffer重用效率低下,进而导致网络吞吐量下降。如果实现的buffer number没有覆盖Buffer turnaround time,那么网络将在每个router上被人为地限制,因为flit将不能连续地流向下一个router,即使在router的其他端口没有竞争的情况下。
如图5 - 10所示,两个router之间的link在等待下游router的空闲缓冲区时空闲了6个周期;
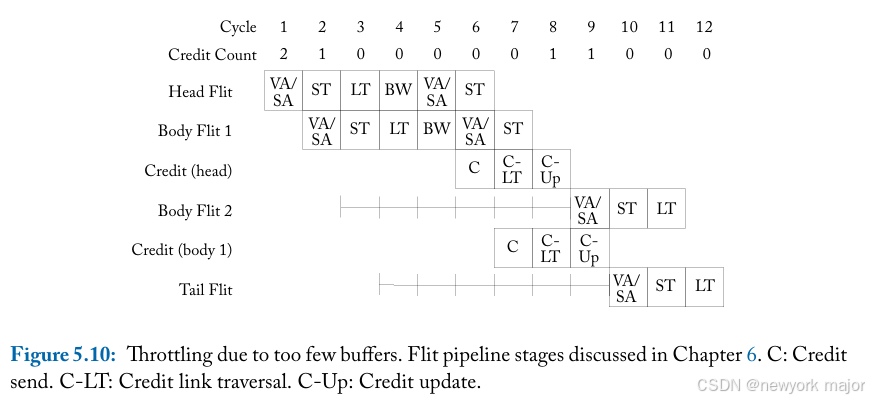
对于credit-based buffer backpressure,a buffer从 flit 离开当前节点(credit counter递减时)开始一直被保留,直到credit return 以通知当前节点buffer已被释放(因此credit counter可以再次递增)。只有这样,buffer才能分配给下一个 flit,尽管直到 flit 穿过当前router pipeline并传输到下游router时,它才真正被重新使用。
因此,the turnaround time of a buffer至少是the propagation delay of a data flit to the next node、the credit delay back和pipeline delay的总和,如图5.11a 所示。
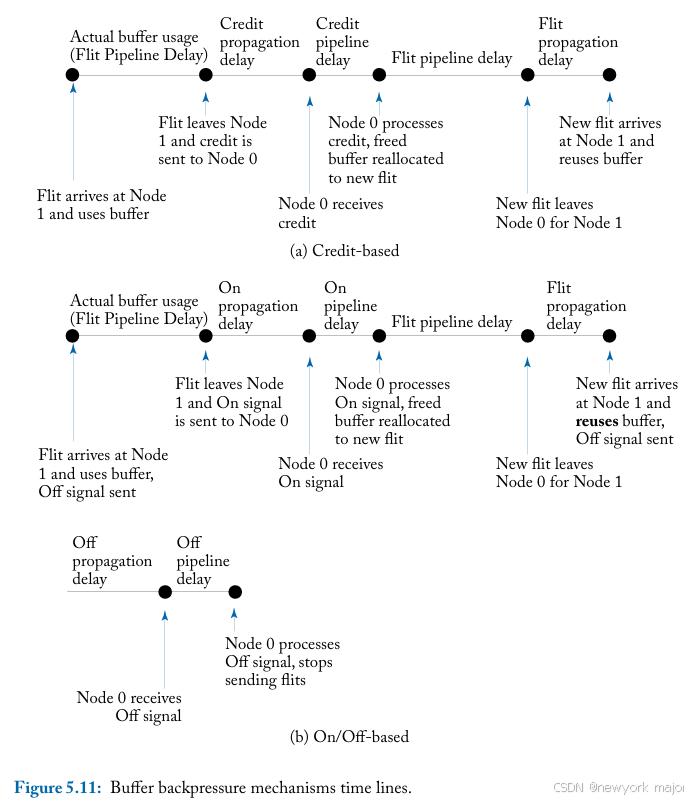
相比之下,在on/off buffer backpressure,从 flit 到达下一个节点并占用最后一个buffer(高于阈值)时起,buffer就被held,从而触发发送关闭信号以停止当前节点发送。这种情况持续到 flit 离开下一个节点并释放buffer(导致空闲缓冲区计 数超过阈值)。因此,开启信号被置位,通知当前节点现在可以恢复发送 flit。当数据 flit 到达下一个节点时,该buffer再次被占用。因此,此处的buffer turnaround time至少是the on/off signal propagation delay,加上数据 flit 的传播延迟和pipeline delay的两倍,如图5.11b 所示;
如果相邻节点之间的propagation delay和reverse signaling的传播延迟均为 1 周期,pipeline delay for buffer backpressure signals为 1 周期,3-cycle router pipeline,,则credit-based backpressure的buffer turnaround time至少为 6 周期,而on/off backpressure的 buffer turnaround time至少为 8 周期。
请注意,这意味着使用on/off backpressure的网络每个端口至少需要 8 个buffer才能覆盖turnaround time,而如果选择credit-based backpressure,则每个端口需要的buffer将减少 2 个。 因此,buffer turnaround time也会影响面积开销,因为buffer占据了router空间的很大一部分。 请注意,一旦确定 flit 将离开router并且不再需要其buffer,就可以通过backpres sure signals(credits or on/of)来优化buffer turnaround time,而不是等到 flit 实际已从缓冲区中读出。
Reverse Signaling Wires
虽然on/off backpressure与o credit-based backpressure相比性能较差,但它在reverse signaling overhead方面开销较低。
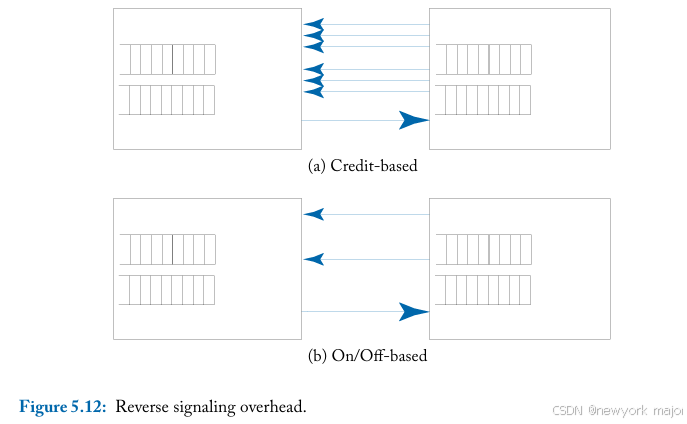
图5.12说明了两种backpressure mechanisms所需的reverse signaling wires number:credit-based的backpressure需要每个queue(虚拟通道) log(B) wires,其中B是队列中的buffer数量,to encode the credit count。另 一方面,on/off 每个队列只需要一条线。如果每个queu有⼋个buffer和两个虚拟通道,credit-based backpressure需要六条reverse signaling wires (图5.12a),而On/Off 只需要两条reverse signaling wires(图5.12b)。
在片上网络中,由于片上布线丰富,因此reverse signaling overhead往往比area overhead and throughput更不值得关注。因此,credit-based backpres sure will be more suitable。
Flow Control In Application Specific On-Chip Networks
Multiprocessor SoCs (MPSoC) 通常依赖于wormhole flow control,其原因与更通用的片上网络采用wormhole flow control的原因相同。在 MPSoC 上运行的应用 程序通常具有实时性能要求。此类quality of service requirements会影响flow control design decisions。The network interface controller可以调节注入网络的流量,以减少争用并确保公平性。使用时分复用 (TDM) 为每个节点分配固定数量的带宽是提供保证吞吐量和避免争用的一种方法。时分复用对communications进行调度,以便每个communication flow在network links上都有自己的time slot。实现的The size and number of time slots决定了可以分配网络资源的粒度。由于TDM slots是先验分配的,实际带宽需求的偏差将导致idling channels。
MPSoC 的custom network可能会导致heterogeneous set of switches;这些switches在端口数量、虚拟通道数量和buffers数量方面可能有所不同。对于flow control implementation,可以根据communication characteristics在每个节点上实例化不同数量 的buffer。buffers resource将影响on/off flow control的阈值或credit based flowcontrol所需的reverse signaling wires。此 外,自定义拓扑中的非均匀链路长度将影响buffer turn-around time of the flow control implementation。在这种类型的环境中,规则性和模块化被牺牲了;但是,功率、性能和面积增益可能很大。

















 2911
2911

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









