




 本文是强化学习系列的第三篇文章,重点介绍Q学习,一种重要的价值迭代算法。通过学习Q表,智能体能够做出最优决策。我们将探讨Q学习的基本原理,并结合实例展示其在解决复杂问题中的应用。
本文是强化学习系列的第三篇文章,重点介绍Q学习,一种重要的价值迭代算法。通过学习Q表,智能体能够做出最优决策。我们将探讨Q学习的基本原理,并结合实例展示其在解决复杂问题中的应用。
Q learning
强化学习例子----穿越冰湖的游戏
FrozenLake environment是OpenAI公司(特斯拉公司的老板的另外一个公司,主要研究AI技术)开发的一个环境,这个环境可以让开发者用来练习和测试各种强化学习算法。
代码:
env = gym.make('FrozenLake-v0')
冰封的湖面有4X4个小格子组成,这些小格子有一个是穿越游戏的起点,有些是安全结实的冰面,有些是危险的会陷下去的冰面,有一个是穿越湖面的终点。游戏者每走一步,将会获得一个奖赏值0,除非游戏者成功到达终点,将会获得一个奖赏值1。另外,这个游戏的另一个随机因素是强风,环境中会随机挂起强风,把游戏者刮到随机的位置。这样其实没有确定的一定成功的游戏策略,但整个环境的还是相当稳定,能够训练出能够稳定躲避危险,并到达目的地的游戏策略。
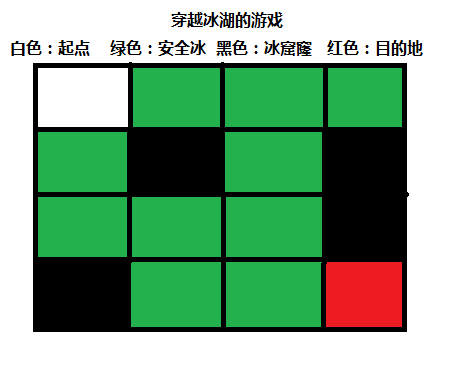
所以我们的目标是开发、训练一个模型,这个模型能够成功的完成这个游戏。
如何把强化学习过程数学表示?---马尔科夫决策过程(MDP)
如何用数学形式表示深度学习问题:MDP(马尔科夫决策过程,Markov Decision Process)。
一个状态与行动对(State, Action),代表在状态State的情况下,执行了动作Action。其后后续将导致两个结果,一个是得到一个立即收益Reward,另外一个结果就是从从一个State转换到另一个State。这种状态转移的过程就构成了MDP。这个过程(例如一局游戏)中只包含了有限的State,Action和Reward的集合。
s
0
,a
0
,--->r
1
,s
1
,a
1
,--->r
2
,s
2
,…,s
n−1
,a
n−1
,--->r
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









