




目录
问题:百度防爬虫机制:动态加载图片,当值无法读取 html源码中的图像src。后续用go语言实现2种爬虫方法
解决方案:
acjson 方法
使用动态加载时候的acjson方法,就是原生百度图片搜索,临时出现的acjson文件,通过一些规律自己编写acjson,方法就是修改keywords 和pn的值,看下面例子
url = "http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord="+keyworlds +
"&cl=2&lm=-1&ie=utf-8&oe=utf-8&st=-1&ic=0&word="+keyworlds +"&face=0&istype=2nc=1&pn="+ strconv.Itoa(page)+"&rn=60"如下图,不停请求上图url,其中keyworlds是关键字,如下面例中 “周杰伦”,page则是从0开始每次加一。请求得到的html中,过滤出 objectURL=“http://.....jpg”等,然后去下载。
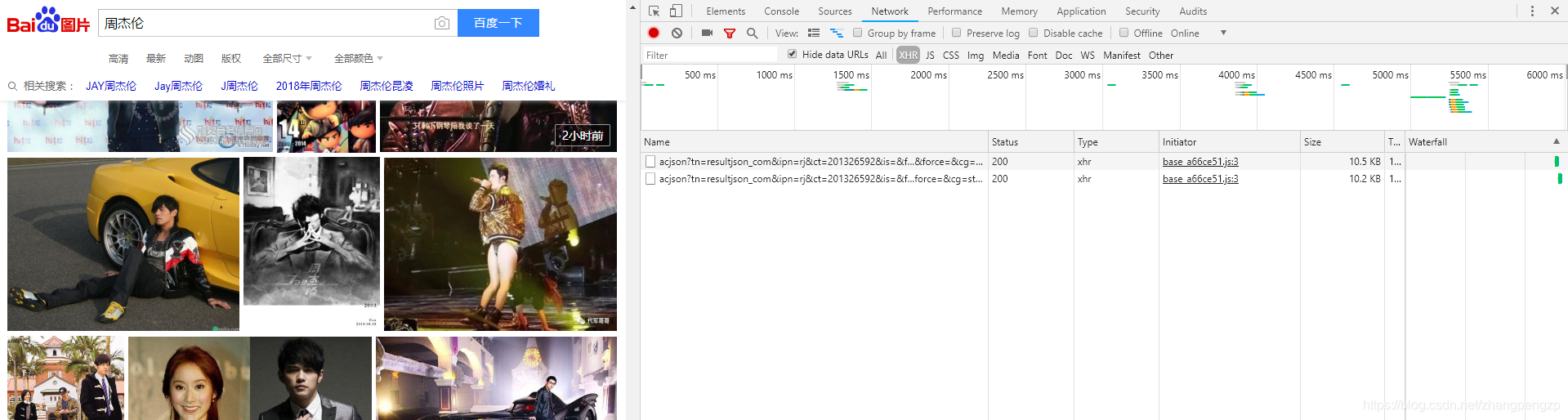
下面是在google百度搜索周杰伦,滚动页面时候产生的acjson文件 (方法,F12 , network XHR,然后滚动鼠标,下滑页面)
flip方法
就是采用flip网站代替,这是百度检索图片的另一种方式,改变其中的page,每一页有20图片,其实大家可以打开这个网站,将page置为0,关键字置为“周杰伦”,如下( pn每次加20即可到下一页)
http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=周杰伦&pn=0&gsm=140&ct=&ic=0&lm=-1&width=0&height=0url = "http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word="+keyworlds +"&pn="
+ strconv.Itoa(page*20)+"&gsm=140&ct=&ic=0&lm=-1&width=0&height=0"当然,第一种动
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1776
1776

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









