




 本文详细介绍了TensorFlow中的数据操作流程,包括变量定义、初始化、计算图构建及Session使用等核心概念。通过实例演示了变量操作、矩阵运算及变量更新等常见任务。
本文详细介绍了TensorFlow中的数据操作流程,包括变量定义、初始化、计算图构建及Session使用等核心概念。通过实例演示了变量操作、矩阵运算及变量更新等常见任务。
Tensorflow – 数据操作
tensorflow的数据操作有着一个固定的模式,它先定义变量,操作,然后创建计算图,在图里计算:
如下面的:
1、定义变量、操作(其实也是理解为生成新的变量),此时即使定义时赋值了,变量还是没有值的,是在创建session计算的时候,首先就得变量初始化,赋值操作。
2、创建Session,然后将变量或者操作放入session中计算(run)
- 数据只在Session内有效。run函数里只能是操作,比如矩阵相乘(或者是前面的变量所代表的操作),或者一些zeros初始化变量等操作,不能是
tf.Variable()定义的变量 - 所有
Variable()定义的变量,在session中使用时,需要初始化.session.run(tf.global_variables_initializer())
3、定义的一些操作,要在seesion中run或者调用才会执行(在run里面可以用 上面定义的“操作”前面变量当作参数),总之要明白,上面只是定义的变量和操作,真正执行的是在session里面,且数据的生命期也是在本seesion里。
下面这个例子体现了,上面定义的是变量和操作,在session外变量是没有值的,
1、在session里 run了变量初始化后w、x才有值,
2、后面在打印y的值 y.eval()时候,y也赋值了。
import tensorflow as tf
# create a varibale 创建变量、操作(矩阵相乘)
w = tf.Variable([[1, 2]])
x = tf.Variable([[2, 4], [3, 5]])
y = tf.matmul(w, x)
# 这时候y还没有值,这里只是定义了操作
print(y)
# 变量初始化操作,初始化所有定义的数据,既计算所有的操作
init_op = tf.global_variables_initializer()
# 初始化,所有变量的计算需要在session中初始化,初始化后才有值,打印值需要eval()
with tf.Session() as sess:
sess.run(init_op)
print(y.eval())
# 下面打印出错,结果只在session内有数据
# print(y.eval()) 下面是一个简单的对a加一操作的例子,虽然简单,但也能体现:
1、只有Variable定义的变量需要初始化,
2、当定义的其他操作或者变量也用到了Variable的时候才需要对初始化tf.global_variables_initializer()
3、session.run(update_a)和 aupdate_a.eval() 效果相同,但设计多个session时用run
4、打印当前变量结果,也可使用print(sess.run(a)),如过是操作,最好不要这么用,会多一次改变其他变量的值(如打印print(sess.run(update_a)) 只是为了看结果,则让a的值多加一次1)
import tensorflow as tf
a = tf.Variable(1)
b = tf.ones([2, 3], tf.int32)
new_a = tf.add(a, tf.constant(1))
update_a = tf.assign(a, new_a)
with tf.Session() as sess:
# b没有用到variable变量不需初始化操作
print("----b---")
print(b.eval())
print("----a---")
sess.run(tf.global_variables_initializer())
print(a.eval())
print("----a- sess.run(update_a)--")
sess.run(update_a)
print(a.eval())
print("----a- update_a.eval()--")
# 这里通 sess.run(update_a),如果直接写update_a,则a不会加一
update_a.eval()
print(a.eval())
print("------c-------")
# 这里操作c只是定义了操作(与update_a相同),并不会更新a的值
c = tf.assign(a, new_a)
print(a.eval())
# 下面执行c.eval()则会执行c操作,a的值才会加一
print(c.eval())
print(a.eval())
"""
执行结果:
----b---
[[1 1 1]
[1 1 1]]
----a---
1
----a- sess.run(update_a)--
2
----a- update_a.eval()--
3
------c-------
3
4
4
"""tensorflow定义了变量,只能说在计算用到的时候才会真正对变量赋值,并执行赋值附带的操作。
常用的一些函数,
与numpy类似,tensorflow的一些数据操作比较相似,并且可以相互转化(不建议)
为了节约时间直接传图得了:
最后2个解释一下都是在区间内平均取值,前面的第三个参数是个数,第二个函数是间隔

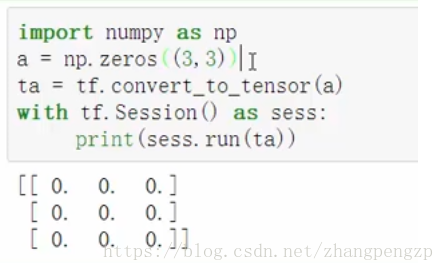
numpy转化为tensorflow
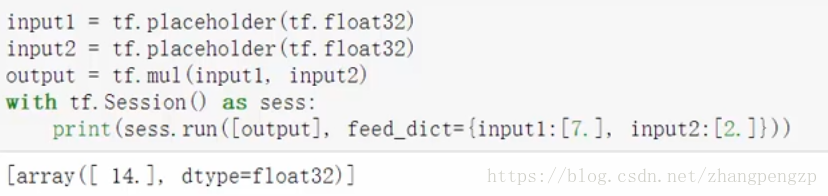
placeholder用法
先占据位置,在session中赋值,进行操作


















 2908
2908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









