



 本文介绍基于会话的推荐算法,它在用户未登录时依赖匿名会话预测行为,是序列推荐子领域。文中阐述GRU4Rec、NARM、STAMP、SR - GNN四种算法原理与结构,指出该推荐本质是Next - Item - Prediction任务,训练数据时间跨度和session长度会影响指标,还提及对SR - GNN的改进。
本文介绍基于会话的推荐算法,它在用户未登录时依赖匿名会话预测行为,是序列推荐子领域。文中阐述GRU4Rec、NARM、STAMP、SR - GNN四种算法原理与结构,指出该推荐本质是Next - Item - Prediction任务,训练数据时间跨度和session长度会影响指标,还提及对SR - GNN的改进。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
基于会话的推荐算法(Session-based Recommendation)是指在用户未登录状态下, 仅仅依赖匿名会话进行用户下一个行为预测的一种算法, 在许多领域(如电商、短视频、直播等)有着重要的作用.
Session-based Recommendation易与序列推荐(Sequencial Recommendation)混淆, 这里区分一下,序列推荐中常将用户长期历史序列建模表征用户, 可能还包括用户画像等信息, 典型算法如MIND、SDM等; 而基于会话的推荐中, session行为长度相对更短, 且用户长期偏好完全未知, 主要侧重于建模用户近期实时兴趣, 可以视为序列推荐的子领域.
基于会话推荐, 简单的可直接根据session内的item进行I2I扩充, 但每个item取多少?session内多个I2I队列如何融合?传统方法如马尔科夫链(Markov chain)也可进行next item predict, 但其依赖的强假设: 下一状态只能由当前状态决定, 在时间序列中之前的行为均与之无关, 导致其在实际场景中运用受限; 近期Session-based推荐的SOTA结果都是基于神经网络模型取得的. 2016年提出的GRU4Rec1是该系列中经典的一篇, 首次利用RNN对session序列建模, 取得了很好的结果; 在此基础上, NARM2将注意力机制应用于对session的顺序行为及主要意图进行分别建模,捕捉用户兴趣; 与NARM相似, STAMP3利用简单的多层感知机(MLP)和注意力网络对session内长短期兴趣分别表征; 之前序列模型都仅对连续交互相邻item之间的序列过渡关系进行挖掘, 而忽略了未直接相连item之间复杂地转变, SR-GNN4通过引入GNN来对session graph进行建模, 以此发掘序列内item之间复杂的过渡模式.
一、GRU4REC
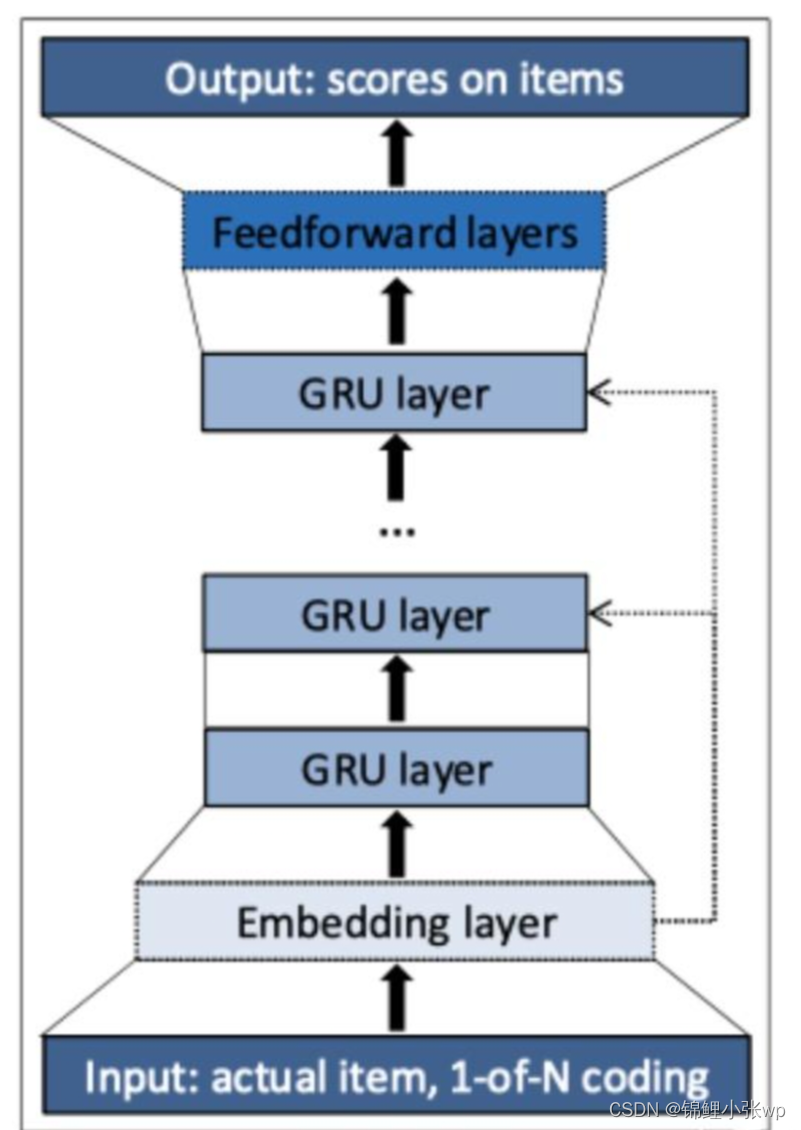
GRU4Rec网络结构比较简单, 输入是用户匿名session序列
. 首先, 对序列中item进行one-hot编码, 接着从Embedding层获得item向量表征, 经过堆叠的多层GRU更新, 最后经由全连接层计算下一个被点击item的概率. 本质上, GRU层相当于对session序列进行编码, 获得其向量表征, 在输出层计算与item向量的点积, softmax输出作为预测概率. 工程实现上有以下3个创新点, 也在后续的推荐算法落地中被大家所借鉴:
1.并行会话最小批训练(session-parallel mini-batches)
2.Batch内负采样(sampling on the output)
3.Pair-wise损失(rank loss)
二、NRAM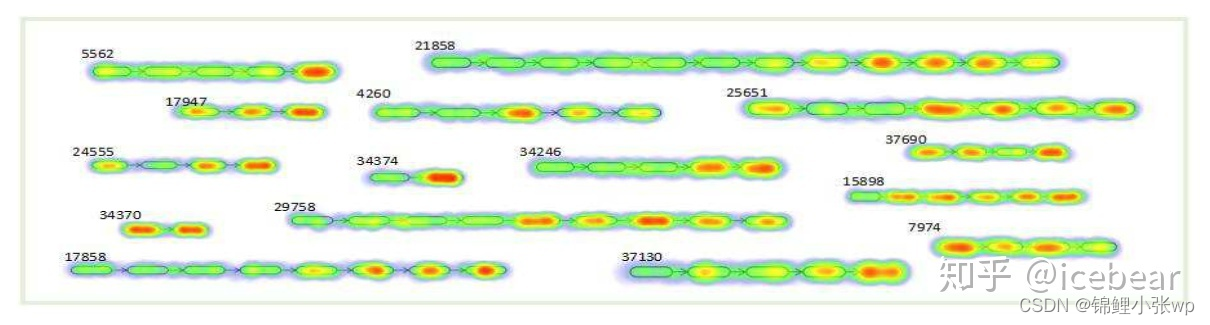
上图呈现了session内用户的兴趣分布, 可以发现, 的确大多数兴趣item集中于session尾部, 但并非所有item都与下一个点击的item相关, 并且用户在会话中的意图是local的. 特别图中4260和7974等类似的session, 上文提到的GRU4Rec就不能很好地处理. NARM则设计了两路多层GRU编码器并引入注意力机制, 分别建模user’s sequential behavior和user’s main purpose, 具体结构如下图:
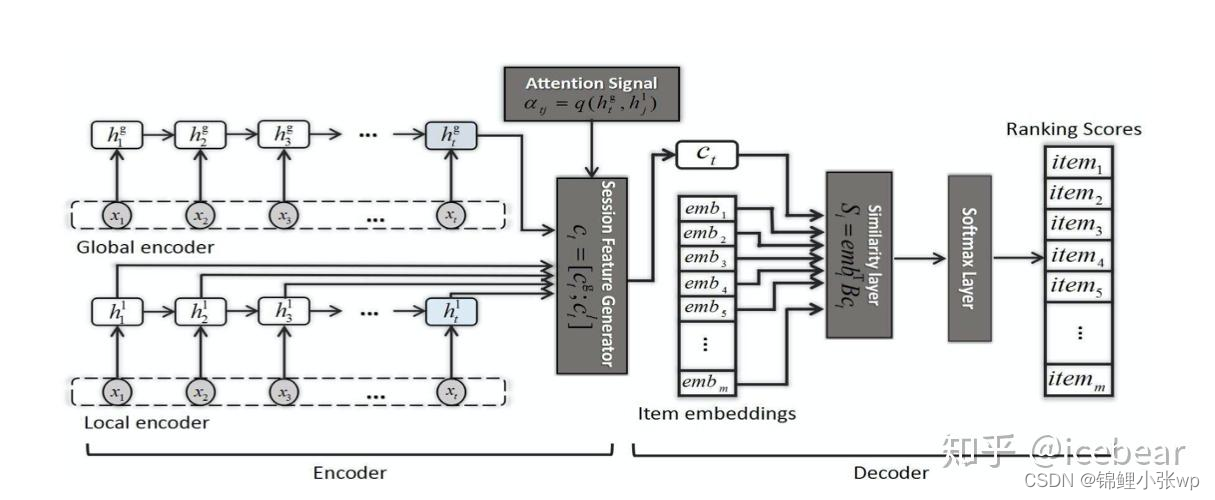
NARM设计为Encoder-decoder结构, 编码器部分包括Global encoder和Local encoder, 均由堆叠的多层GRU构成, 分别对用户序列行为Ctj和主要意图Ctl进行建模. 其中, 利用注意力机制进行主要意图学习:

Session Feature Generator模块将Ctj和Ctl拼接, 形成session的最终隐含表示, 其中既包含了用户序列行为, 又涵盖了用户主要意图. 后面的Top-N预测过程看做是解码器, 在NARM中, 没有采用更常见的点积运算作为相似度量, 而是提出了一种双线性(bi-linear)相似函数, 不仅能缓解网络参数量过大的问题, 还提升了模型的精度, 具体计算如下:

三、STAMP
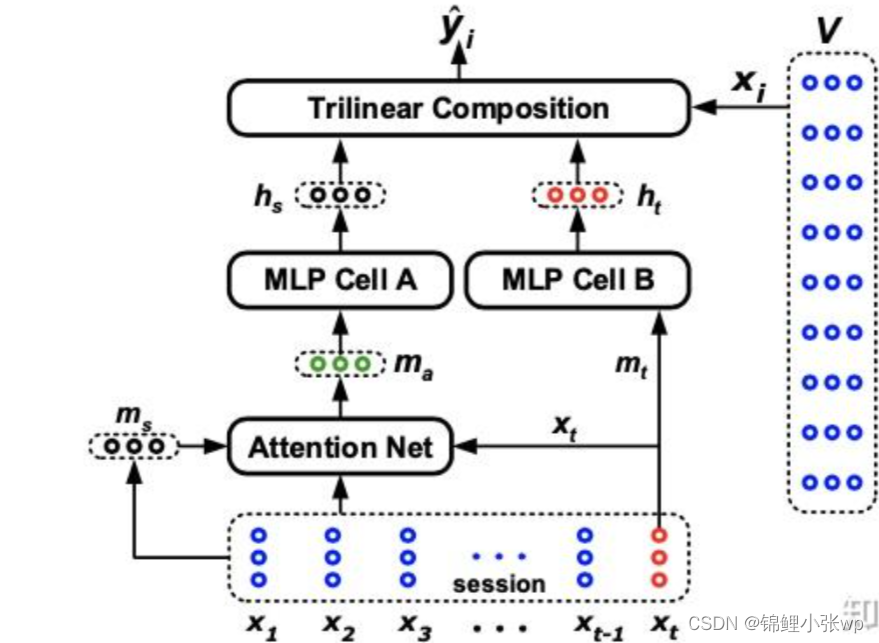
对比NARM结构看, STAMP同样设计了不同结构分别对session内长期兴趣和短期兴趣建模, 也同样是取序列中最后一个交互的item表征短期兴趣. 不同的是, STAMP的网络设计地更加简单, 序列s=[x1,x2,x3,…,xt-1,xt], 取最后item的embedding经过MLP后得到短期兴趣表征ht. 同时设计了注意力网络(Attention Net)对session内长期兴趣进行提取, 该模块也比较好理解, 具体计算如下:
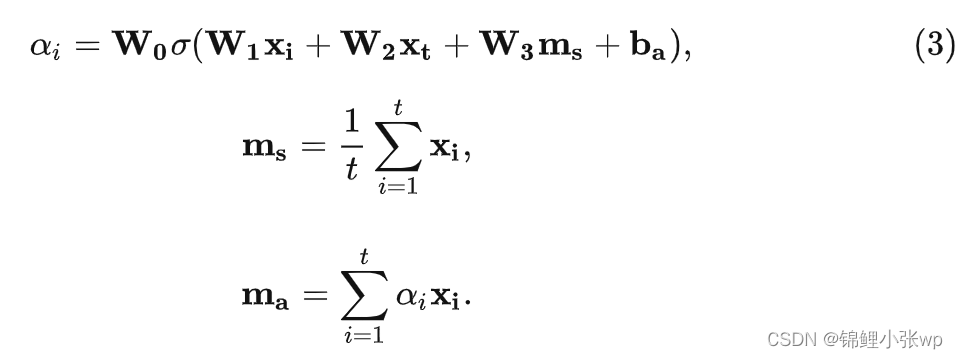
ma同样经过MLP, 结构与MLP Cell B相同, 只是参数独立, 得到长期兴趣表征hs. 最后, 在Trilinear Composition模块中进行兴趣拼接和预测, 通过Hadamard积把长短期兴趣进行组合, 再与候选item向量点积:

四、SR-GNN
上述算法充分考虑了session的序列特性, 并拆分出长短期兴趣表征, 取得了很好的效果, 但是忽略了顺序上不直接相邻的item间是如何过渡的(complex transitions of items). SR-GNN将单个session序列构造为session图结构, 同时引入GGNN(Gated Graph Neural Network), 在此基础上进行建模, 以下是该算法主要流程:
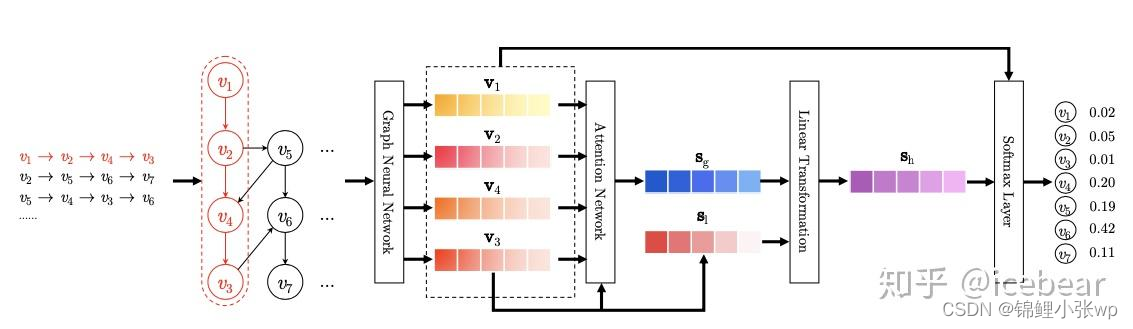
从左至右, 依次包含四个步骤, 分别为: Constructing session graphs、Node representation learning、Session representation generating和Making recommendation:
(1) 首先, 每个session序列s都可以构建为一个有向图Gs=(Vs,Es), 对图中边的权重按照起始结点出度进行归一化. 例如, 某一session序列为si=[v1,v2,v3,v2,v4], 其session图结构及连接矩阵如下:
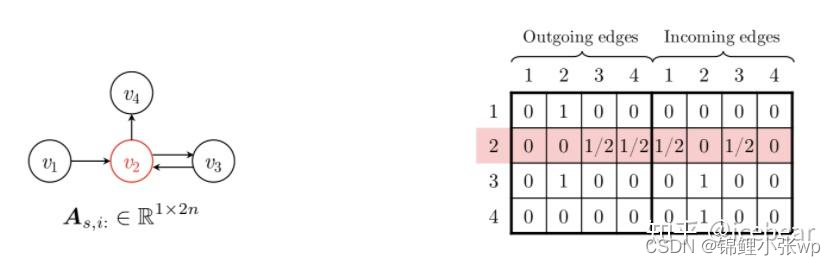
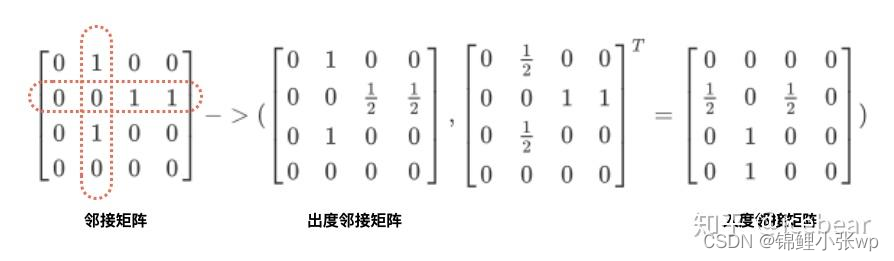
解释一下算法中有向图的连接矩阵是如何构建的. 假设下图左侧是某一Session graph的邻接矩阵表示, 行表示源结点, 列表示目标结点. 可以看到, 结点v2的出度、入度均为2. 接着分别对结点按照出度、入度进行归一化, 可以得到出度邻接矩阵和入度邻接矩阵, 拼接构成上图右侧的连通矩阵.
(2) 采用GGNNs对session graph中的所有结点进行统一表征学习,主要传播规则如下, 公式第一行通过连接矩阵聚合邻居结点信息(包含了入和出两个方向), 剩余过程类似GRU参数更新 :
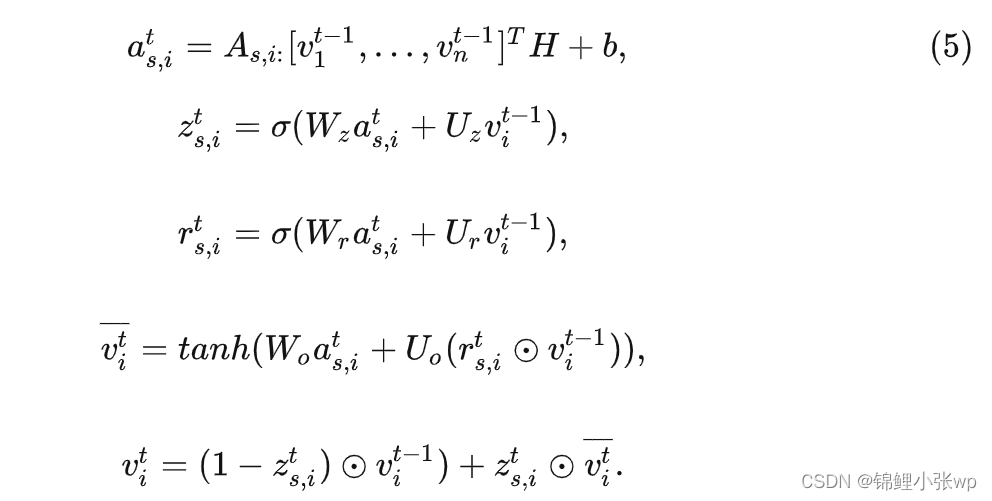
(3) 获得item embedding向量后, 接着生成session embedding. 取session内最后一个交互的结点向量作为用户当前兴趣向量(local embedding), 以凸显最后交互item的重要性. 接着, 通过soft-attention网络获得global embedding以表征session长期兴趣. 最后, 通过一个简单线性函数做融合, 得到session的hybird embedding.
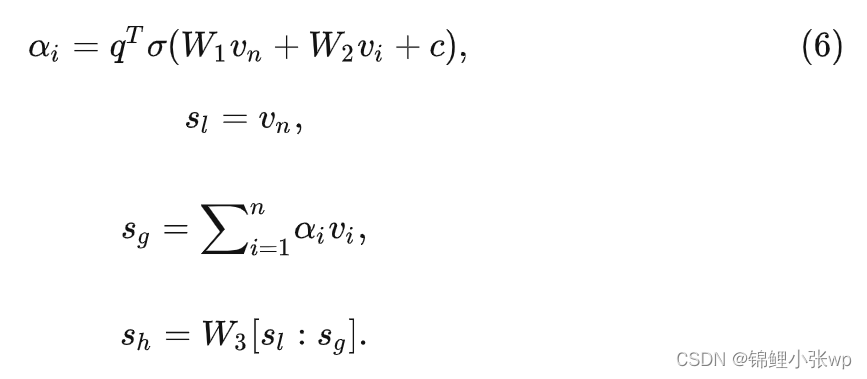
(4) session embedding与候选item embedding点积作为预测值, 进行TopN推荐.
总结
Session-based推荐本质上是一个Next-Item-Prediction任务, 根据日志里sessionID按照时间顺序聚合为序列, 最后一个item作为label. 由于用户兴趣会发生转移, 训练数据集时间跨度并不是越大越好. 比如, 利用近一个月的数据去训练模型可能要比用近三个月的, 在验证集上的指标更好. 而在实时兴趣推断时, 也存在类似情况, 当session长度超过20后, Recall、NDCG等离线指标也都发生了明显下降. 我们在SR-GNN基础上进行了一些改进(数据增强、N ormalize embedding、position embedding等), 作为线上多路召回中一路实时召回队列使用.

















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









