




 本文详细探讨了CPU架构、内存缓存、运行队列等概念,教你如何通过时钟频率、指令执行和性能监控来洞悉系统性能。提升CPU使用率,避免优先级反转,利用多线程和进程绑定,以及使用工具和方法进行动态调优。
本文详细探讨了CPU架构、内存缓存、运行队列等概念,教你如何通过时钟频率、指令执行和性能监控来洞悉系统性能。提升CPU使用率,避免优先级反转,利用多线程和进程绑定,以及使用工具和方法进行动态调优。
CPU推动了所有软件的运行,因而通常是系统性能分析的首要目标。现代系统一般有多个CPU,通过内核调度器共享给所有运行软件。当需求的CPU资源超过了系统力所能及的范围时,进程里的线程(或者任务)将会排队,等待轮候自己运行的机会。等待给应用程序的运行带来严重延时,使得性能下降。
我们可以通过仔细检查CPU的用量,寻找性能改进的空间,还可以去除一些不需要的负载。从上层来说,可以按进程、线程或者任务来检查CPU的用量。从下层来看,可以剖析并研究应用程序和内核里的代码路径。在底层,可以研究CPU指令的执行和周期行为。
术语
- 处理器:插到系统插槽或者处理器板上的物理芯片,以核或者硬件线程的方式包含了一块或者多块CPU。
- 核:一个多核处理器上的一个独立CPU实例。核的使用是处理器扩展的一种方式,又称为芯片级多处理。
- 硬件线程:一种支持在一个核上同时执行多个线程的CPU架构,每个线程是一个独立的CPU实例。这种扩展的方法又称为多线程
- CPU指令:单个CPU操作,来源于它的指令集。指令用于算术操作、内存I/O,以及逻辑控制
- 逻辑CPU:又称为虚拟处理器,一个操作系统CPU的实例(一个可调度的CPU实体)。处理器可以通过硬件线程(这种情况下又称为虚拟核)、一个核,或者一个单核的处理器实现。
- 调度器:把CPU分配给线程运行的内核子系统
- 运行队列:一个等待CPU服务的可运行线程队列。
模型
CPU架构
下图展示了一个CPU架构的示例,单个处理器内共有四个核和八个硬件线程。物理架构如下图右侧所示,而右侧图则展示了从操作系统角度看到的景象。
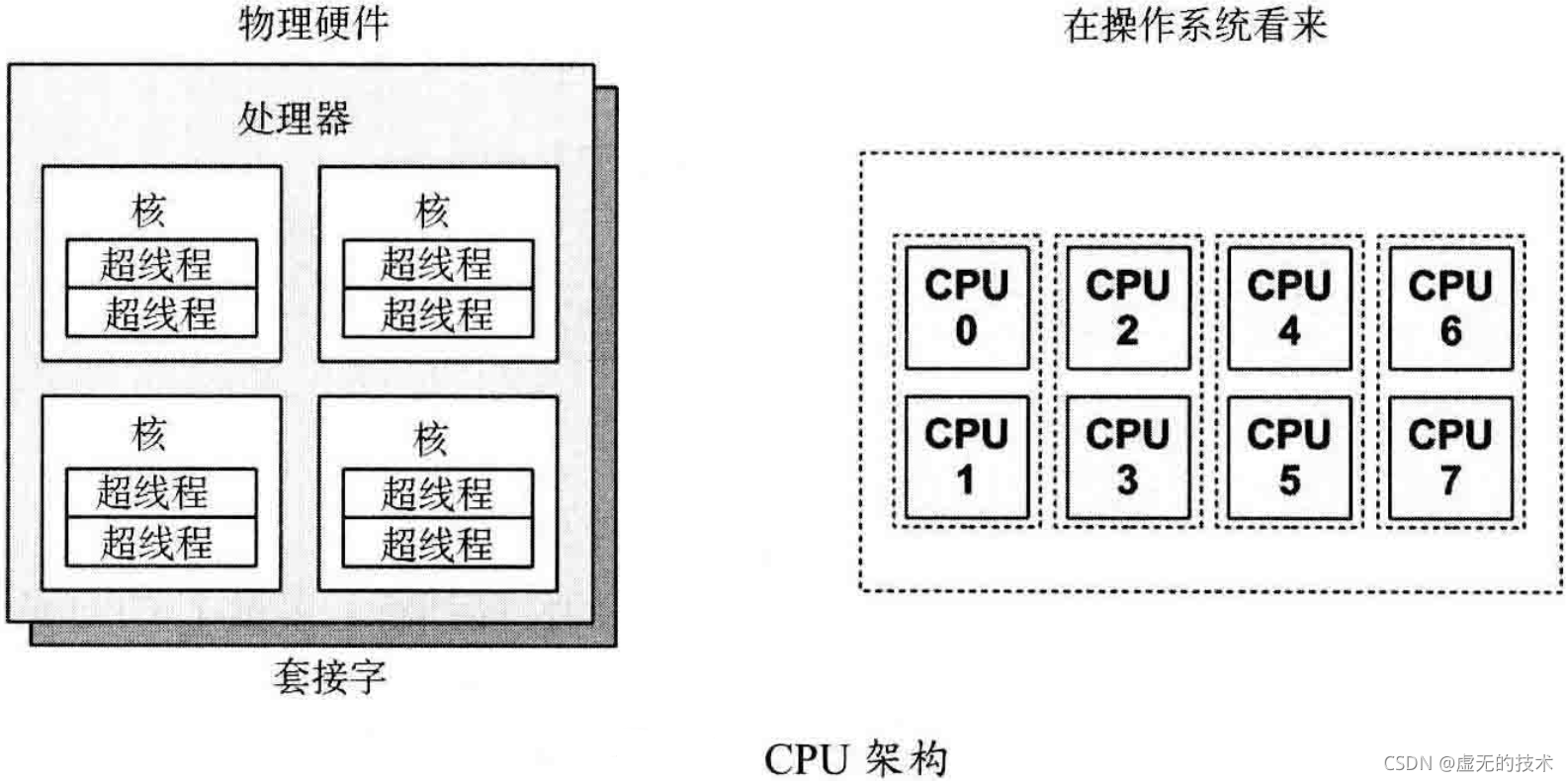
每个硬件线程都可以按逻辑CPU寻址,因此这个处理器看上去有八个CPU。对这种拓补结构,操作系统可能有一些额外信息,如哪些CPU在同一个核上,这样可以提高调度的质量。
CPU内存缓存
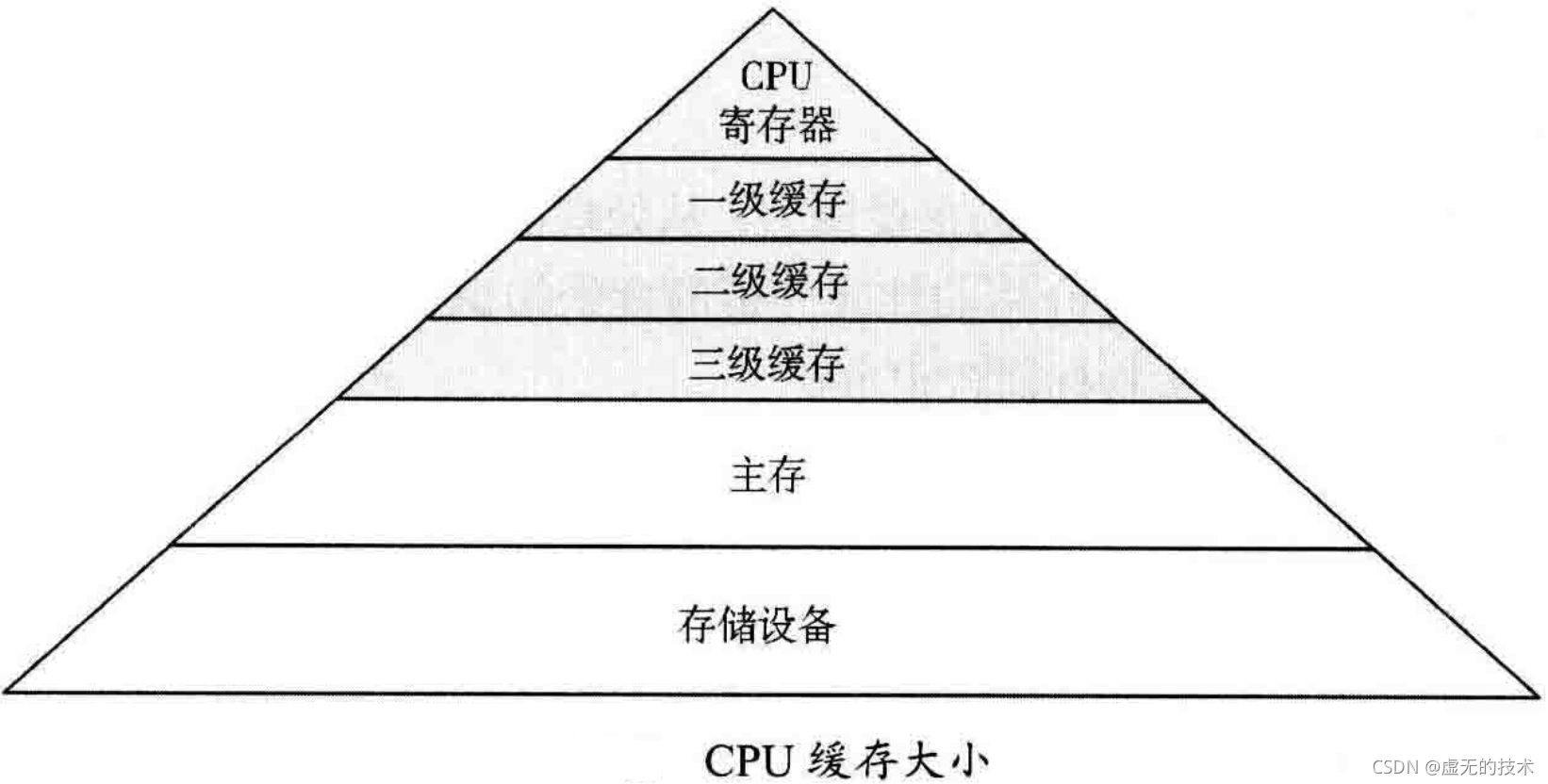
为了提高内存I/O性能,处理器提供了多种硬件缓存。下图展示了缓存大小的关系,越小则速度越快(一种权衡),并且越靠近CPU。
缓存存在与否,以及是在处理器里(集成)还是在处理器外,取决于处理器的类型。早期的处理器集成的缓存层次较少。
CPU运行队列
下图展示了一个由内核调度器管理的CPU运行队列
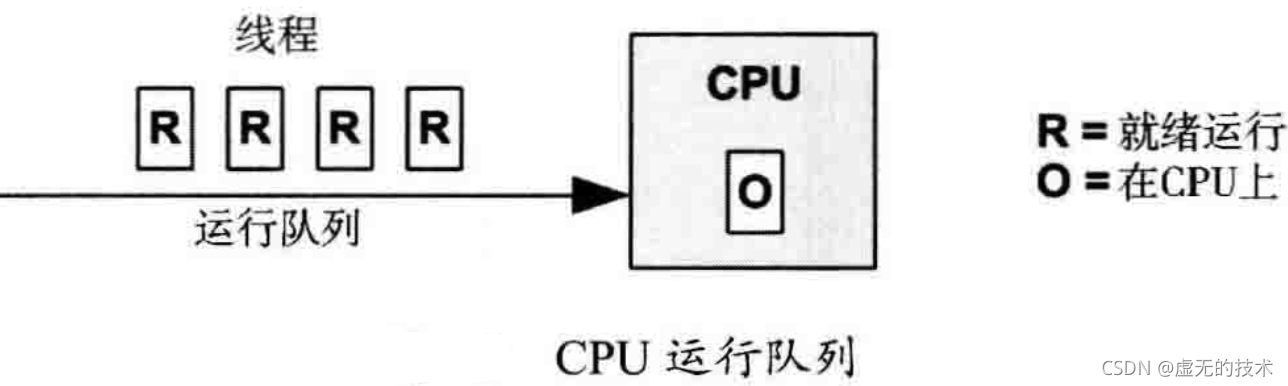
正在排队和就绪运行的软件线程数量是一个很重要的性能指标,表示了CPU的饱和度。在上图中(在这一瞬间)有四个排队线程,加上一个正在CPU上运行的线程。花在等待CPU运行上的时间又被称为运行队列延时或者分发器队列延时。
在于多处理器系统,内核通常为每个CPU提供了一个运行队列,并尽量使得线程每次都被放到同一队列之中。这意味着线程更有可能在同一个CPU上运行,因为CPU缓存里保存了它们的数据。(这些缓存被称为热度缓存,这种选择运行CPU的方法被称为CPU关联)。
概念
时钟频率
时钟是一个驱动所有处理器逻辑的数字信号。每个CPU指令都可能会花费一个或者多个时钟周期(称为CPU周期)来执行。CPU以一个特定的时钟频率执行,例如,一个5GHz的CPU每秒运行五十亿个时钟周期。
有些处理器可以改变时钟频率,升频以改进性能或者降频以减少能耗。频率可以根据操作系统请求变化,或者处理器自己进行动态调整。例如内核空闲线程,就可以请求CPU降低评率以节约能耗。
时钟频率经常被当作处理器营销的主要指标,但这有可能让人误入歧途。即使你系统里的CPU看上去已经完全利用(达到瓶颈),但更快的时钟评率并不一定会提供性能——它取决于快速CPU周期里到底在做些什么。如果它们大部分时间是停滞等待内存访问,那更快的执行实际上并不能提高CPU指令的执行效能或者负载吞吐量。
指令
CPU执行指令集中的指令。一个指令包括以下步骤,每个CPU的一个叫作功能单元的组件处理:
- 指令预取
- 指令解码
- 执行
- 内存访问
- 寄存器写回
这里每一步都至少需要一个时钟周期来执行。内存访问经常是最慢的,因为它通常需要几十个时钟周期读或写主存,在此期间指令执行陷入停滞(停滞期间的这些周期称为停滞周期)。这就是CPU缓存如此重要的原因:它可以极大地降低内存访问需要的周期数。
指令流水线
指令流水线是一种CPU架构,通过同时执行不同指令的不同部分,来达到同时执行多个指令的结果。这类似于工厂的组装线,生产的每个步骤都可以同时执行,提高了吞吐量。
指令宽度
我们还能更快。同一种类型的功能单元可以有好几个,这样每个时钟周期里就可以处理更多的指令。这种CPU架构被称为超标量,通常和流水线一起使用以达到高指令吞吐量。
指令宽度描述了同时处理的目标指令数量。现代处理器一般为宽度3或者宽度4,意味着它们可以在每个周期里最多完成3~4个指令。如何取得这个结果取决于处理器本身,每个环节都有不同数量的功能单元处理指令。
CPI,IPC
每指令周期数(CPI)是一个很重要的高级指标,用来描述CPU如何使用它的时钟周期,同时可以用来理解CPU使用率的本质。这个指标也可以被表示为每周期指令数(instructionsper cycle, IPC),即CPI的倒数。
CPI 较高代表CPU经常陷入停滞,通常都是在访问内存。而较低的CPI则代表CPU基本没有停滞,指令吞吐量较高。这些指标指明了性能调优的主要工作方向。
内存访问密集的负载,可以通过下面的方法提供性能,如使用更快的内存(DRAM)、提高内存本地性(软件配置),或者减少内存I/O数量。使用更高时钟频率的CPU并不能达到预期的性能目标,因为CPU还是需要为等待内存I/O完成而花费同样的时间。换句话说,更快的CPU意味更多的停滞周期,而指令完成速率不变。
CPI的高低与否实际上和处理器以及处理器功能有关,可以通过实验方法运行已知的负载得出。例如,你会发现高CPI的负载可以使CPI达到10或者更高,而在低CPI的负载下,CPI低于1(收益于前述的指令流水线和宽度技术,这是可以达到的)。
值得注意的是,CPI代表了指令处理的效率,但不代表指令本身的效率。假设有一个软件改动,加入了一个低效率的循环,这个循环主要在操作CPU寄存器(没有停滞周期):这种改动可能会降低总体CPI,但会提高CPU的使用和利用度。
使用率
CPU使用率通过测量一段时间内CPU实例忙于执行工作的时间比例获得,以百分比表示。它也可以通过测量CPU未运行内核空闲线程的时间得出,这段时间内CPU可能运行一些用户态应用线程,或者其他的内核线程,或者处理中断。
高CPU使用率并不一定代表着问题,仅仅表示系统正在工作。有些人认为这是ROI的指示器:高度利用的系统被认为有着较好ROI,而空闲的系统则是浪费。和其他类型的资源(磁盘)不同,在高使用率的情况下,性能并不会出现显著下降,因为内核支持优先级、抢占和分时共享。这些概念加起来让内核决定了什么线程的优先级更高,并保证它优先运行。
CPU使用率的测量包括了所有符合条件活动的时钟周期,包括了内存停滞周期。虽然看上去有些违反直觉,但CPU有可能像前面描述的那样,会因为停滞等待I/O而导致高使用率,而不仅是在执行指令。
CPU使用率通常会被分成内核时间和用户时间两个指标。
用户时间/内核时间
CPU花在执行用户态应用程序代码的时间称为用户时间,而执行在内核代码的时间称为内核时间。内核时间包括系统调用、内核线程和中断的时间。当在整个系统范围内进行测量时,用户时间和内核时间之比揭示了运行的负载类型。
计算密集的应用程序几乎会把大量的时间用再用户态代码上,用户/内核时间之比接近99/1。这类例子有图像处理、基因组学和数据分析。
I/O密集的应用程序的系统调用频率较高,通过执行内核代码进行I/O操作。例如,一个进行网络I/O的Web服务器的用户/内核时间比大约为70/30.
饱和度
一个100%使用率的CPU被称为是饱和的,线程在这种情况下会碰上调度器延时,因为它们需要等待才能在CPU上运行,降低总体性能。这个延时是线程花在等待CPU运行队列或者其他管理线程的数据结构上的世界。
另一个CPU饱和度的形式则和CPU资源控制有关,这个控制会在云计算环境下发生。尽管CPU并没有100%地被使用,但已经达到了控制的上线,因此可运行的线程就必须等待轮到它们的机会。这个过程对用户的可见度取决于使用的虚拟化技术。
一个饱和运行的CPU不像其他类型资源那样问题重重,因为更高优先级的工作可以抢占当前线程。
抢占
允许更高优先级的线程抢占当前正在运行的线程,并开始执行自己。这样节省了更高优先级工作的队列延时时间,提供了性能。
优先级反转
优先级反转指的是一个低优先级线程拥有了一项资源,从而阻塞了高优先级线程运行的情况。这降低了高优先级工作的性能,因为它被迫阻塞等待。
多进程,多线程
大多数处理器都以某种形式提供多个CPU。对于想使用这个功能的应用程序来说,需要开启不同的执行线程以并发运行。对于一个64个CPU的系统来说,这意味着一个应用程序如果同时满所有CPU,可以达到最快64倍的速度,或者处理64倍的负载。应用程序可以根据CPU数目进行有效放大的能力又称为扩展性。
应用程序在多CPU上扩展的技术分为多进程和多线程,如下图所示:
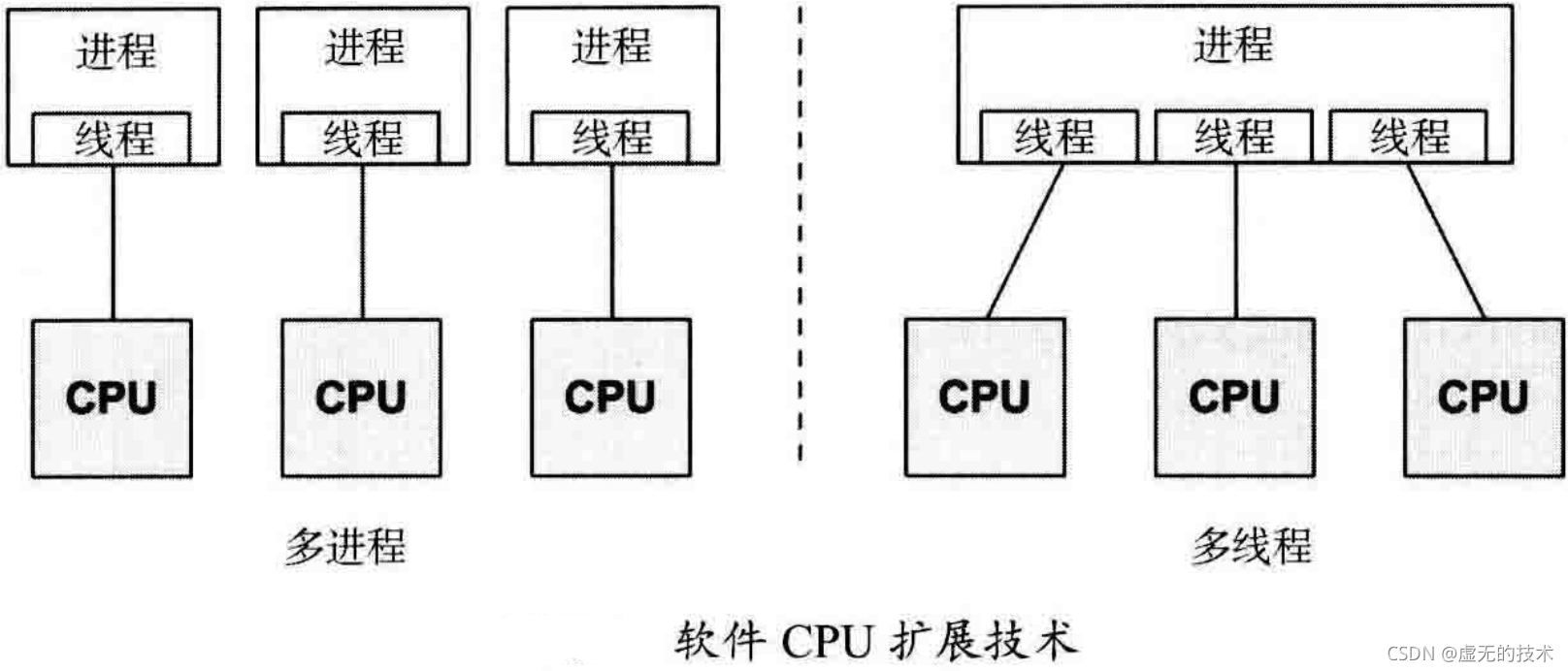
在Linux上可以使用多进程和多线程模型,而这两种技术都是由任务实现的。
多进程和多线程的差异如下表所示:
| 属性 | 多进程 | 多线程 |
|---|---|---|
| 开发 | 较简单。使用fork() | 使用线程API |
| 内存开销 | 每个进程不同的地址空间消耗了一些内存资源 | 小。只需要额外的栈和寄存器空间 |
| CPU开销 | forl() / exit()的开销,另外MMU还需要管理地址空间 | 小。API调用 |
| 通信 | 通过IPC。导致了CPU开销,包括为了在不同地址空间之间移动数据而导致的上下文切换,除非使用共享内存区域 | 最快。直接存储共享内存。通过同步原语保证数据一致性(例如,mutex锁) |
| 内存使用< |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2196
2196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









