







一 Hive基本概念
1.1 什么是Hive
Hive:由Facebook开源用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质是:将HQL/SQL转化成MapReduce程序
1:Hive处理的数据存储在HDFS
2:Hive分析数据底层的实现是MapReduce
3:执行程序运行在Yarn上
1.2 Hive的优缺点
优点
:1:操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
:2:避免了去写MapReduce,减少开发人员的学习成本。
:3:Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合;
:4:Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高。
:5:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
缺点
1:Hive的HQL表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长
2:Hive的效率比较低
(1)Hive自动生成的MapReduce作业,通常情况下不够智能化
(2)Hive调优比较困难,粒度较粗
1.3 Hive架构原理
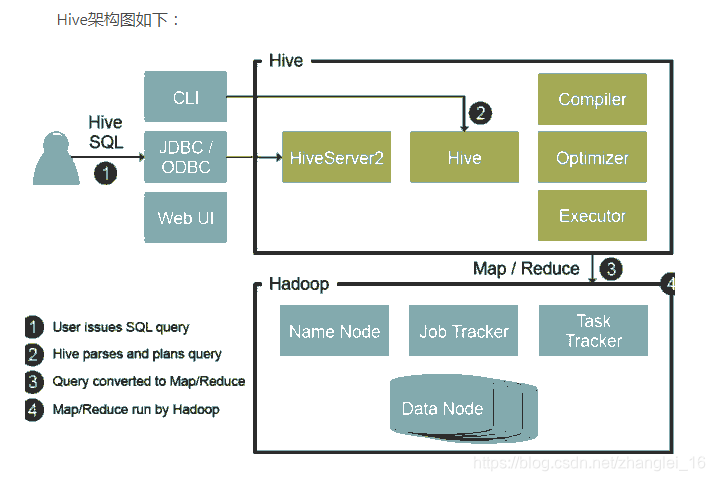
如图中所示,Hive通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的Driver,结合元数据(MetaStore),将这些指令翻译成MapReduce,提交到Hadoop中执行,最后,将执行返回的结果输出到用户交互接口。
1:用户接口:Client
CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问hive)
2:元数据:Metastore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据 所在目录等;
默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
3:Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
4:驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进 行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
1.4 Hive和数据库比较
由于 Hive 采用了类似SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
查询语言
由于SQL被广泛的应用在数据仓库中,因此,专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持对数据的改写和添加,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET修改数据。
索引
Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
执行
Hive中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce框架。由于MapReduce 本身具有较高的延迟,因此在利用MapReduce 执行Hive查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive的并行计算显然能体现出优势。
可扩展性
由于Hive是建立在Hadoop之上的,因此Hive的可扩展性是和Hadoop的可扩展性是一致的(世界上最大的Hadoop 集群在 Yahoo!,2009年的规模在4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有100台左右。
数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
二 Hive安装环境准备
2.1 Hive安装地址
1:Hive官网地址:http://hive.apache.org/
2:文档查看地址:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
3:下载地址:http://archive.apache.org/dist/hive/
4:github地址:https://github.com/apache/hive
2.2 Hive安装部署
1:Hive安装及配置
(1)把apache-hive-1.2.1-bin.tar.gz上传到linux的/opt:目录下
(2)解压apache-hive-1.2.1-bin.tar.gz到/opt/mod/目录下面
tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /opt/mod/
(3)修改apache-hive-1.2.1-bin.tar.gz的名称为hive
mv apache-hive-1.2.1-bin/ hive
(4)修改/opt/mod/hive/conf目录下的hive-env.sh.template名称为hive-env.sh
cp hive-env.sh.template hive-env.sh
(5)配置hive-env.sh文件
(a)配置HADOOP_HOME路径
export HADOOP_HOME=/opt/mod/hadoop-2.8.4
(b)配置HIVE_CONF_DIR路径
export HIVE_CONF_DIR=/opt/mod/hive/conf
注:Hive的log默认存放在/tmp/itstar/hive.log目录下(当前用户名下)。
(1)修改hive的log存放日志到/opt/mod/hive/logs
(2)修改conf/hive-log4j.properties.template文件名称为hive-log4j.properties
pwd
/opt/mod/hive/conf
cp hive-log4j.properties.template hive-log4j.properties
(3)在hive-log4j.properties文件中修改log存放位置
hive.log.dir=/opt/mod/hive/logs
2:Hadoop集群配置
(1)必须启动hdfs和yarn
/opt/mod/hadoop-2.8.4/sbin/start-dfs.sh
/opt/mod/hadoop-2.8.4/sbin/start-yarn.sh
(2)在HDFS上创建/tmp和/user/hive/warehouse两个目录并修改他们的同组权限可写
/opt/mod/hadoop-2.8.4/bin/hadoop fs -mkdir /tmp
/opt/mod/hadoop-2.8.4/bin/hadoop fs -mkdir /user/hive/warehouse
/opt/mod/hadoop-2.8.4/bin/hadoop fs -chmod g+w /tmp
/opt/mod/hadoop-2.8.4/bin/hadoop fs -chmod g+w /user/hive/warehouse
3:Hive基本操作
(1)启动hive
/opt/mod/hive/bin/hive
(2)查看数据库
hive>show databases;
(3)打开默认数据库
hive>use default;
(4)显示default数据库中的表
hive>show tables;
(5)创建一张表
hive> create table student(id int, name string) ;
(6)显示数据库中有几张表
hive>show tables;
(7)查看表的结构
hive>desc student;
(8)向表中插入数据
hive> insert into student values(1001,"ss1");
(9)查询表中数据
hive> select * from student;
(10)退出hive
hive> quit;
2.4 MySql安装
wget http://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz
tar -zxvf mysql-5.7.20-linux-glibc2.12-x86_64.tar.gz
mv mysql-5.7.20-linux-glibc2.12-x86_64 /usr/local/
cd /usr/local
ln -s mysql-5.7.20-linux-glibc2.12-x86_64 mysql
cp /usr/local/mysql/support-files/mysql.server /etc/init.d/mysql
mkdir -p /mysql/data
mkdir -p /mysql/logs
mkdir -p /mysql/temp
groupadd mysql
useradd -r -g mysql -s /bin/false mysql
chown -R mysql:mysql /usr/local/mysql
chown -R mysql:mysql /mysql
vi /etc/profile
export PATH=/usr/local/mysql/bin:$PATH
vi /etc/my.conf
[client]
#prompt = [\\u@\\h][\\d]>\\_
#default-character-set = utf8
port = 3306
socket = /tmp/mysql.sock
[mysqld]
# GENERAL #
user = mysql
port = 3306
default-storage-engine = InnoDB
#collation_server = utf8_unicode_ci
character_set_server = utf8
socket = /tmp/mysql.sock
pid-file = /mysql/data/mysql.pid
# MyISAM #
key-buffer-size = 32M
myisam-recover-options = FORCE,BACKUP
#skip-grant-tables
# SAFETY #
max-allowed-packet = 16M
max-connect-errors = 1000000
skip-name-resolve
sysdate-is-now = 1
lower_case_table_names = 1
explicit_defaults_for_timestamp = 1
# DATA STORAGE #
datadir = /mysql/data/
# BINARY LOGGING #
server-id = 104
log-bin = /mysql/logs/mysql-bin
expire-logs-days = 7
sync-binlog = 1
log_bin_trust_function_creators = 1
# GITD MODE #
gtid_mode = ON
enforce-gtid-consistency = 1
binlog_cache_size = 4M
max_binlog_size = 1G
max_binlog_cache_size = 5G
# REPLICATION #
skip-slave-start = 1
relay-log = /mysql/logs/relay-bin
slave-net-timeout = 60
sync-master-info = 1
sync-relay-log = 1
sync-relay-log-info = 1
slave-parallel-type = LOGICAL_CLOCK
slave-parallel-workers = 8
master_info_repository = TABLE
relay_log_info_repository = TABLE
relay_log_recovery = ON
# CACHES AND LIMITS #
tmp-table-size = 32M
max-heap-table-size = 32M
query-cache-type = 0
query-cache-size = 0
max-connections = 5000
thread-cache-size = 100
open-files-limit = 65535
table-definition-cache = 4096
table-open-cache = 4096
# INNODB #
innodb-flush-method = O_DIRECT
innodb-log-files-in-group = 3
innodb-log-file-size = 1024M
innodb-flush-log-at-trx-commit = 1
innodb-file-per-table = 1
innodb-buffer-pool-size = 4G
sql_mode = STRICT_TRANS_TABLES,NO_ENGINE_SUBSTITUTION
# LOGGING #
log-error = /mysql/logs/mysql_error.log
log-queries-not-using-indexes = 1
slow-query-log = 1
slow-query-log-file = /mysql/logs/mysql_slow.log
log_timestamps = SYSTEM
# UNDO #
innodb_max_undo_log_size = 1024M
innodb_undo_log_truncate = 1
innodb_undo_logs = 128
innodb_undo_tablespaces = 4
innodb_undo_directory = /mysql/data
innodb_purge_rseg_truncate_frequency
[mysqldump]
quick
#max_allow_packet = 64M
[mysqladmin]
port = 3306
socket = /tmp/mysql.sock
#timewait#
wait_timeout=3600
interactive_timeout=3600
[xtrabackup]
port = 3306
socket = /tmp/mysql.sock
chown mysql:mysql /etc/my.cnf
初始化mysql
/usr/local/mysql/bin/mysqld --initialize --user=mysql --basedir=/usr/local/mysql/ --datadir=/mysql/data
错误日志中,查看root初始化密码
grep "root" /mysql/logs/error.log
service mysql start;
service mysql status;
mysql -uroot -pJi0wLtgDWv.V
mysql>set password=password('oracle');
mysql>use mysql;
mysql>update user set host = '%' where user = 'root';
mysql>grant all privileges on *.* to root@'%' identified by 'oracle';
mysql>flush privileges;
2.5 Hive元数据配置到MySql
2.5.1 驱动拷贝
1:上传mysql-connector-java-5.1.27-bin.jar到/opt/module/hive/lib/
cp mysql-connector-java-5.1.27-bin.jar /opt/module/hive/lib/
2.5.2 配置Metastore到MySql
1:在/opt/module/hive/conf目录下创建一个
vi hive-site.xml
2:根据官方文档配置参数,拷贝数据到hive-site.xml文件 https://cwiki.apache.org/confluence/display/Hive/AdminManual+MetastoreAdmin
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.104:3306/metastore?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>oracle</value>
<description>password to use against metastore database</description>
</property>
</configuration>
3: 配置完毕后,如果启动hive异常,可以重新启动虚拟机。(重启后,别忘了启动hadoop集群)
:4: 在hive的bin目录下执行
/opt/mod/hive/bin/schematool -dbType mysql -initSchema
2.5.3 Hive常见属性配置
2.5.3.1 Hive数据仓库位置配置
1:Default数据仓库的最原始位置是在hdfs上的:/user/hive/warehouse路径下
:2:在仓库目录下,没有对默认的数据库default创建文件夹。如果某张表属于default数据库,直接在数据仓库目录下创建一个文件夹。
:3:修改default数据仓库原始位置(将hive-default.xml.template如下配置信息拷贝到hive-site.xml文件中)
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>
配置同组用户有执行权限
/opt/mod/hadoop-2.8.4/bin/hdfs dfs -chmod g+w /user/hive/warehouse
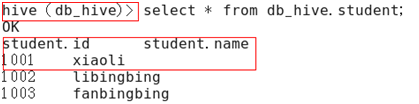
2.5.3.2 查询后信息显示配置
1)在hive-site.xml文件中添加如下配置信息,就可以实现显示当前数据库,以及查询表的头信息配置。
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
2)重新启动hive,对比配置前后差异
(1)配置前

(2)配置后
2.5.3.3 Hive运行日志信息配置
1:Hive的log默认存放在/tmp/itstar/hive.log目录下(当前用户名下)。
2:修改hive的log存放日志到/opt/mod/hive/logs
(1)修改/opt/mod/hive/conf/hive-log4j.properties.template文件名称为
hive-log4j.properties
pwd
/opt/mod/hive/conf
cp hive-log4j.properties.template hive-log4j.properties
(2)在hive-log4j.properties文件中修改log存放位置
hive.log.dir=/opt/mod/hive/logs
2.5.3.4 多窗口启动Hive测试
1:先启动MySQL
mysql -uroot -poracle
查看有几个数据库
mysql> show databases;
+-----------------------------+
| Database |
+-----------------------------+
| information_schema |
| mysql |
| performance_schema |
| test |
+-----------------------------+
2:再次打开多个窗口,分别启动hive
/opt/mod/hive/bin/hive
3)启动hive后,回到MySQL窗口查看数据库,显示增加了metastore数据库
mysql> show databases;
+-----------------------------+
| Database |
+-----------------------------+
| information_schema |
| metastore |
| mysql |
| performance_schema |
| test |
+-----------------------------+
2.6 将本地文件导入Hive案例
需求:将本地/opt/mod/datas/student.txt这个目录下的数据导入到hive的student(id int, name string)表中。
1:数据准备:在/opt/mod/datas/student.txt这个目录下准备数据
(1)在/opt/mod/目录下创建datas
mkdir datas
(2)在/opt/datas/目录下创建student.txt文件并添加数据
vi student.txt
1001 zhangshan
1002 lishi
1003 wangwu
1004 zhangshan1
1005 lishi1
1006 wangwu1
注意以tab键间隔。
2:Hive实际操作
(1)启动hive
/opt/mod/hive/bin/hive
(2)显示数据库
hive>show databases;
(3)使用default数据库
hive>use default;
(4)显示default数据库中的表
hive>show tables;
(5)删除已创建的student表
hive (default)> drop table student;
OK
Time taken: 0.336 seconds
(6)创建student表, 并声明文件分隔符’\t’
hive (default)> create table student(id int, name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
OK
Time taken: 0.313 seconds
(7)加载/opt/datas/student.txt 文件到student数据库表中。
hive (default)> load data local inpath '/opt/datas/student.txt' into table student;
Loading data to table default.student
Table default.student stats: [numFiles=1, totalSize=79]
OK
Time taken: 0.773 seconds
(8)Hive查询结果
hive (default)> select * from student;
OK
student.id student.name
1001 zhangshan
1002 lishi
1003 wangwu
1004 zhangshan1
1005 lishi1
1006 wangwu1
Time taken: 0.18 seconds, Fetched: 6 row(s)
3:遇到的问题
再打开一个客户端窗口启动hive,会产生java.sql.SQLException异常。
Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:677)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:621)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1523)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:86)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:132)
at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:104)
at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:3005)
at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:3024)
at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:503)
... 8 more
原因是,Metastore默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore;
2.7 Hive常用交互命令
/opt/mod/hive/bin/hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the console)
1:"-e"不进入hive的交互窗口执行sql语句
/opt/mod/hive/bin/hive -e "select id from student;"
OK
id
1001
1002
1003
1004
1005
1006
Time taken: 4.308 seconds, Fetched: 6 row(s)
2:"-f"执行脚本中sql语句
(1)在/opt/datas目录下创建hivef.sql文件
vi hivef.sql
文件中写入正确的sql语句
select *from student;
(2)执行文件中的sql语句
/opt/mod/hive/bin/hive -f /opt/datas/hivef.sql
OK
student.id student.name
1001 zhangshan
1002 lishi
1003 wangwu
1004 zhangshan1
1005 lishi1
1006 wangwu1
Time taken: 4.043 seconds, Fetched: 6 row(s)
You have new mail in /var/spool/mail/root
(3)执行文件中的sql语句并将结果写入文件中(注:可能含有其他的表信息,如表头)
/opt/mod/hive/bin/hive -f /opt/datas/hivef.sql > /opt/datas/hive_result.txt
cat /opt/datas/hive_result.txt
student.id student.name
1001 zhangshan
1002 lishi
1003 wangwu
1004 zhangshan1
1005 lishi1
1006 wangwu1
2.9 Hive其他命令操作
1:退出hive窗口:
hive(default)>exit;
hive(default)>quit;
在新版的oracle中没区别了,在以前的版本是有的:
exit:先隐性提交数据,再退出;
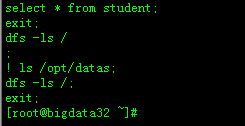
quit:不提交数据,退出;
:2:在hive cli命令窗口中如何查看hdfs文件系统
hive(default)>dfs -ls /; 
3:在hive cli命令窗口中如何查看hdfs本地系统
hive(default)>! ls /opt/datas;
4:查看在hive中输入的所有历史命令
(1)进入到当前用户的根目录/root或/home/$username
(2)查看. hivehistory文件
cat .hivehistory
2.10 参数配置方式
1:查看当前所有的配置信息
hive>set;
2:参数的配置三种方式
(1)配置文件方式
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
注意:用户自定义配置会覆盖默认配置。另外,Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本机启动的所有Hive进程都有效。
(2)命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
例如:
/opt/mod/hive/bin/hive -hiveconf mapred.reduce.tasks=10;
注意:仅对本次hive启动有效
查看参数设置:
hive (default)> set mapred.reduce.tasks;
显示为:mapred.reduce.tasks=10
默认mapred.reduce.tasks=-1
(3)参数声明方式
可以在HQL中使用SET关键字设定参数
例如:
hive (default)> set mapred.reduce.tasks=10;
注意:仅对本次hive启动有效。
查看参数设置
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,
必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。

















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









