




 本文介绍如何使用JMeter从接口响应中提取特定数据,重点演示了两种方法:通过正则表达式提取器及BeanShell断言提取Authorization字段。
本文介绍如何使用JMeter从接口响应中提取特定数据,重点演示了两种方法:通过正则表达式提取器及BeanShell断言提取Authorization字段。
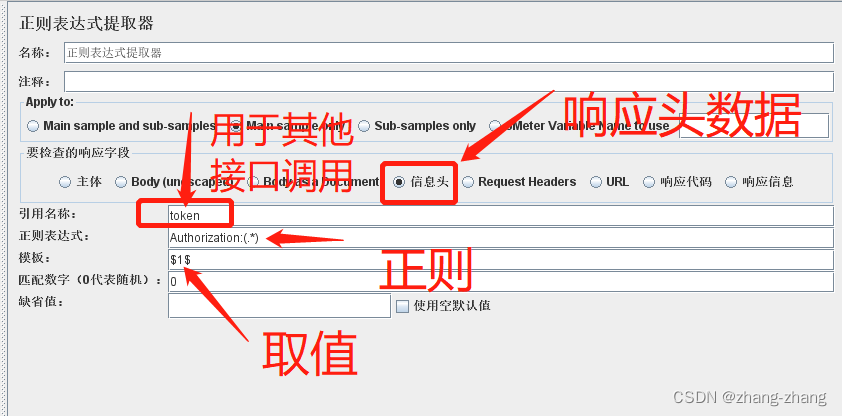
jmeter进行接口测试时,需要依赖前一个接口中的响应数据。我们将以获取响应头的数据进行示例,介绍获取响应数据的方法,其他方法类似。
Response Header中的数据格式如下,接下来将提取Authorization字段的数据。
HTTP/1.1 200
Access-Control-Allow-Methods: GET,POST,OPTIONS,PUT,DELETE
Vary: Origin
Vary: Access-Control-Request-Method
Vary: Access-Control-Request-Headers
Set-Cookie: rememberMe=deleteMe; Path=/summer; Max-Age=0; Expires=Thu, 25-Aug-2022 06:02:13 GMT; SameSite=lax
Authorization: eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJwYXNzd29yZCI6IllXUnRhVzR4TWpNPSIsImV4cCI6MTY2MTUwMDkzMiwidXNlcm5hbWUiOiJhZG1pbiJ9.E2y2HPuYueJ0VSVY440qzqiQHHlhCDz1xT048_MCaUk
Content-Type: application/json;charset=UTF-8
Transfer-Encoding: chunked
Date: Fri, 26 Aug 2022 06:02:13 GMT
Keep-Alive: timeout=60
Connection: keep-alive
- 正则表达式提取器

2. Beanshell 断言
beanshell断言为脚本如下变量,脚本可直接调用,脚本如下:

import java.util.HashMap;
import java.util.Map;
//将字符串用换行符 截取为adc数组
String [] headersList = ResponseHeaders.split("\n");
Map headersMap = new HashMap(); //创建HashMap来从新组装headers
for(int i=1;i<headersList.length;i++){
String [] itemList=headersList[i].split(": "); // 将每一条Headerr项按冒号分割
headersMap.put((itemList[0]), itemList[1]); // 分键值放入HashMap
}
String token1 = headersMap.get("Authorization"); // 提取相应项
vars.put("token1",token1);
log.info("############ Authorization ############" + token1);
- BeanShell后置处理器

import org.apache.jmeter.samplers.SampleResult;
import java.util.regex.*;
//指定模式在字符串中查找
String headers= prev.getResponseHeaders(); //获取headers内容,需要导入org.apache.jmeter.samplers.SampleResult 包
String pattern="Authorization:(.*)";
//创建Pattern对象
Pattern r=Pattern.compile(pattern);
String token;
//创建matcher对象
Matcher m = r.matcher(headers);
if (m.find()){
token=m.group(1).trim();
log.info(token);
}else{
log.info("No Match!");
}
注:若数据支持转化为json格式,可直接转化为json格式并取值
import org.apache.jmeter.samplers.SampleResult;
import com.alibaba.fastjson.*;
String headers= prev.getResponseHeaders(); //获取请求内容
log.info("###################"+headers); //jmeter console界面输出该信息
#将string类型转化为json对象
JSONObject responseJson =JSON.parseObject(headers);
#从json对象中提取Authorization的值
String data=responseJson.getString("Authorization");

















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}