







 本文详细介绍了布隆过滤器的工作原理及其应用场景,包括如何通过多个哈希函数来减少误判率,以及不支持删除操作的原因。此外,还深入探讨了一致性哈希算法,展示了其在分布式系统中如何进行节点分配,以减少节点变动带来的影响。
本文详细介绍了布隆过滤器的工作原理及其应用场景,包括如何通过多个哈希函数来减少误判率,以及不支持删除操作的原因。此外,还深入探讨了一致性哈希算法,展示了其在分布式系统中如何进行节点分配,以减少节点变动带来的影响。
(1)布隆过滤器 BloomFilter
算法:
1. 初始化一个长度为n比特的数组,每个比特位初始化为0
2. 首先需要k个hash函数,每个函数都把key散列成为m个整数
3. 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1
4. 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中
通过两个图简单的理解下:
红色线条表示hash1方法 黑色线条表示hash2方法
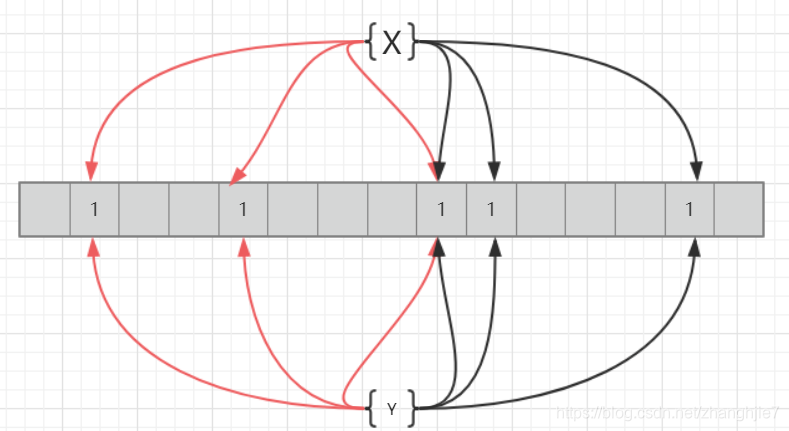
X和Y 在hash1和Hash2方法中获得了完全相同的值,则在忽略误判率的情况下 认为X和Y是相同值
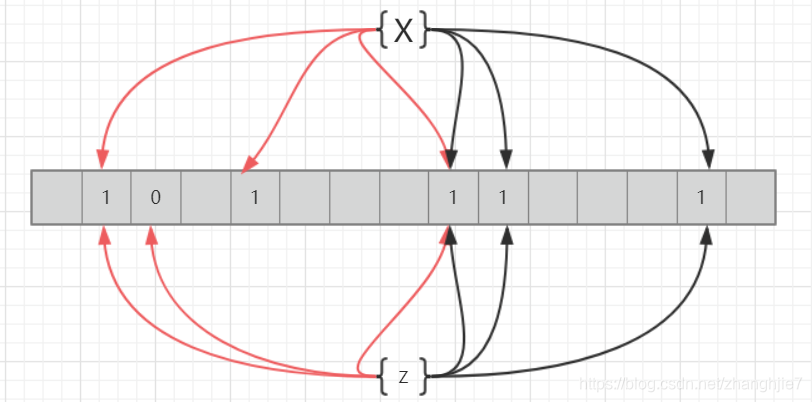
X和Z在hash1的方法时便不能完全重合 可以直接认为X和Z是两个不同值
Hash2方法中重合,是因为hash碰撞,所以理论上为了避免误判 降低误判率 hash方法越多越好,数组越长越好
缺点:
1)因为存在hash碰撞 所以一定会误判存在(脸黑点两个值也能判断错了) 但是如果判读为不存在 就必定不存在
2)普通过滤不支持删除操作(Couting BloomFilter 带计数器的布隆过滤器可以删除)
简单的使用:
public static void main(String[] args) {
BloomFilter<CharSequence> bloomFilter =
BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000000, 0.0001);
bloomFilter.put("121");
bloomFilter.put("122");
bloomFilter.put("123");
System.out.println(bloomFilter.mightContain("121"));
}当判断1000W的数据,能容忍的误判率万分之一时,布隆过滤器会构造 13个hash方法,3000W长度的数组 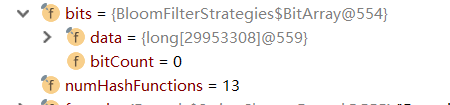
计算后将占3.57MB 内存
(2)计算一致性hash consistentHash()
话不多说 直接上代码
public static void main(String[] args) {
String newChar = "买橘子";
HashCode hashCode = HashCode.fromBytes(newChar.getBytes());
// buckets 集群中机器数量
int buckets = 70;
// bucket 的范围在 0 ~ buckets 之间
int bucket = consistentHash(hashCode.padToLong(), buckets);
System.out.println(bucket);
}
public static int consistentHash(long input, int buckets) {
// 检查机器的数量一定大于0
checkArgument(buckets > 0, "buckets must be positive: %s", buckets);
// 利用内部的LCG算法实现,产生伪随机数
LinearCongruentialGenerator generator = new LinearCongruentialGenerator(input);
int candidate = 0;
int next;
// Jump from bucket to bucket until we go out of range
while (true) {
// generator.nextDouble() 产生伪随机数
// 每次hash的循环中每一个的next的值总是会固定
next = (int) ((candidate + 1) / generator.nextDouble());
if (next >= 0 && next < buckets) {
// 如果在 0 到 bucket 范围之外, 将这个next值赋值给candidate,重新计算
candidate = next;
} else {
// 如果在 0 到 bucket 范围之内, 就返回这个 candidate 值,作为 input数据存储的槽
return candidate;
}
}
}
// LCG伪随机数的算法实现,关于LCG的解释可以参考 http://en.wikipedia.org/wiki/Linear_congruential_generator
private static final class LinearCongruentialGenerator {
private long state;
public LinearCongruentialGenerator(long seed) {
this.state = seed;
}
public double nextDouble() {
state = 2862933555777941757L * state + 1;
return ((double) ((int) (state >>> 34) + 1)) / (0x1.0p31);
}
}源码注解是从别的博客里抄的(https://www.jianshu.com/p/c49ed57cdae1) 理解也不算太难
这里有一个问题 随意造了一个值 只是修改了buckets 返回了两个不同的值,所以我重新写了一个调用方法
public static void main(String[] args) {
String newChar = "ZHANGHAOJIE";
// buckets 集群中机器数量
int buckets = 1;
// bucket 的范围在 0 ~ buckets 之间
//第一个for是递增机器的数量 Machine Number
// 第二个for是每一个机器数量下的hash分布情况 Random Number
for (int MN = 0; MN < 20; MN++) {
for (int RN = 0; RN < 10; RN++) {
HashCode hashCode = HashCode.fromBytes(String.valueOf(RN).getBytes());
int bucket = consistentHash(hashCode.padToLong(), buckets + MN);
System.out.print(bucket + "-");
}
System.out.println();
}
}结果如下
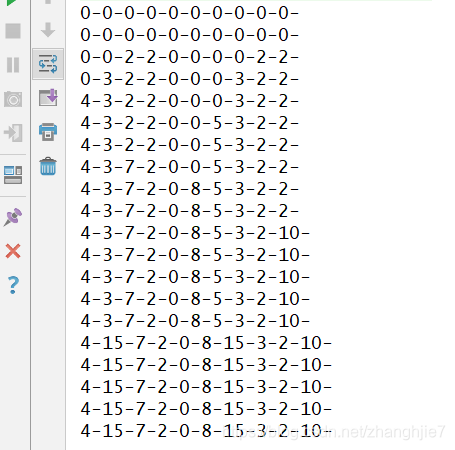
可以看出 随着机器数量的变化 bucket也一直在做着微调
但是想到一致性hash目的:
在服务器数量变更的情况下 尽可能的减少hash的分布的变化,从没有说能100%的规避;
从1到3 10个值变化率只有40%,普通的取模方法必定是全都挂了。

















 1863
1863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









