







 超级会员免费看
超级会员免费看
 本文介绍了缓存在高并发系统中的重要作用,从缓存定义、分类和不足三个方面进行探讨。通过案例说明缓存在内存、Linux 内存管理和网络播放器中的应用,指出缓存可以显著提高系统性能,减少数据库压力。同时,文中提到了缓存的分类,包括静态缓存、分布式缓存和热点本地缓存,并分析了它们在不同场景下的适用性。最后,讨论了缓存的不足,如数据一致性风险和运维复杂度,强调在设计缓存方案时需要综合考虑。
本文介绍了缓存在高并发系统中的重要作用,从缓存定义、分类和不足三个方面进行探讨。通过案例说明缓存在内存、Linux 内存管理和网络播放器中的应用,指出缓存可以显著提高系统性能,减少数据库压力。同时,文中提到了缓存的分类,包括静态缓存、分布式缓存和热点本地缓存,并分析了它们在不同场景下的适用性。最后,讨论了缓存的不足,如数据一致性风险和运维复杂度,强调在设计缓存方案时需要综合考虑。
引言
前面我们已经学了数据库篇,你已经了解了在高并发大流量下,数据库层的演进过程以及库表设计上的考虑点。你的垂直电商系统在完成了对数据库的主从分离和分库分表之后,已经可以支撑十几万 DAU 了,整体系统的架构也变成了下面这样:
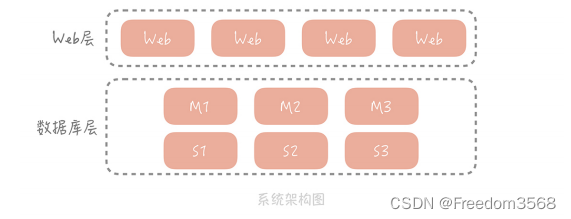
从整体上看,数据库分了主库和从库,数据也被切分到多个数据库节点上。但随着并发的增加,存储数据量的增多,数据库的磁盘 IO 逐渐成了系统的瓶颈,我们需要一种访问更快的组件来降低请求响应时间,提升整体系统性能。这时我们就会使用缓存。那么什么是缓存,我们又该如何将它的优势最大化呢?
本节课是缓存篇的总纲,我将从缓存定义、缓存分类和缓存优势劣势三个方面全方位带你掌握缓存的设计思想和理念,再用剩下 4 节课的时间,带你针对性地掌握使用缓存的正确姿势,以便让你在实际工作中能够更好地使用缓存提升整体系统的性能。
一、缓存
缓存,是一种存储数据的组件,它的作用是让对数据的请求更快地返回。我们经常会把缓存放在内存中来存储, 所以有人就把内存和缓存画上了等号,这完全是外行人的见解。作为业内人士,你要知道在某些场景下我们可能还会使用 SSD 作为冷数据的缓存。比如说 360 开源的 Pika 就是使用 SSD 存储数据解决 Redis 的容量瓶颈的。
实际上,凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存。那

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











