







 超级会员免费看
超级会员免费看
 本文介绍了高并发系统中如何通过主从读写分离来应对查询量增加的问题。主从分离主要解决读多写少的场景,通过数据的主从复制实现读写分离,缓解数据库压力。文章详细讲解了主从复制的技术关键点,包括MySQL的异步复制过程,并探讨了主从延迟、数据库访问方式的改变以及如何选择合适的数据库中间件。最后,强调了主从一致性与写入性能的权衡以及主从延迟问题在排查问题中的重要性。
本文介绍了高并发系统中如何通过主从读写分离来应对查询量增加的问题。主从分离主要解决读多写少的场景,通过数据的主从复制实现读写分离,缓解数据库压力。文章详细讲解了主从复制的技术关键点,包括MySQL的异步复制过程,并探讨了主从延迟、数据库访问方式的改变以及如何选择合适的数据库中间件。最后,强调了主从一致性与写入性能的权衡以及主从延迟问题在排查问题中的重要性。
引言
上节课我们用池化技术解决了数据库连接复用的问题,你的垂直电商系统虽然整体架构上没有变化,但是和数据库交互的过程有了变化,在你的 Web 工程和数据库之间增加了数据库连接池,减少了频繁创建连接的成本,从上节课的测试来看性能上可以提升80%。现在的架构图如下所示:
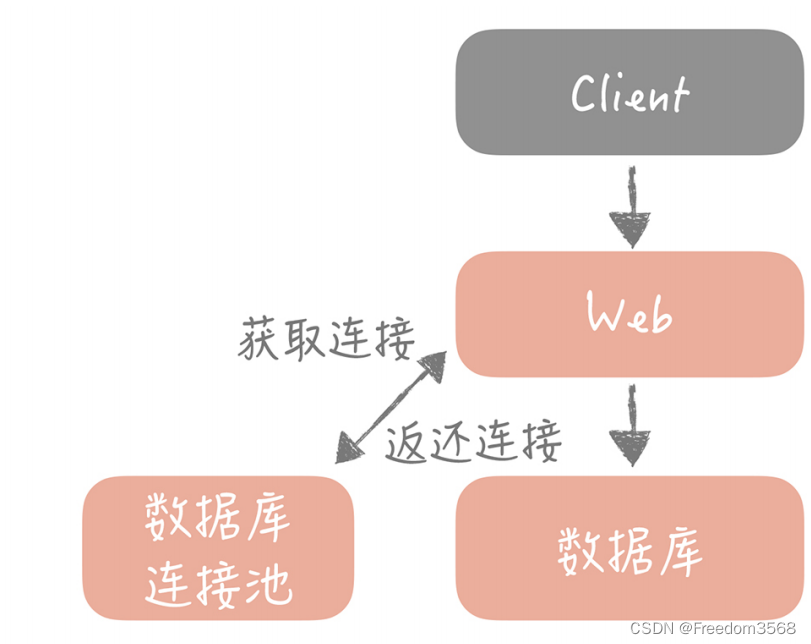
此时,你的数据库还是单机部署,依据一些云厂商的 Benchmark 的结果,在 4 核 8G 的机器上运 MySQL 5.7 时,大概可以支撑 500 的 TPS 和 10000 的 QPS。这时,运营负责人说正在准备双十一活动,并且公司层面会继续投入资金在全渠道进行推广,这无疑会引发查询量骤然增加的问题。那么我们就一起来看看当查询请求增加时,应该如何做主从分离来解决问题。
一、主从读写分离
其实,大部分系统的访问模型是读多写少,读写请求量的差距可能达到几个数量级。这很好理解,刷朋友圈的请求量肯定比发朋友圈的量大,淘宝上一个商品的浏览量也肯定远大于它的下单量。因此,我们优先考虑数据库如何抗住更高的查询请求,那么首先你需要把读写流量区分开,因为这样才方便针对读流量做单独的扩展,这就是我们所说的主从读写分离
它其实是个流量分离的问题,就好比道路交通管制一样,一个四车道的大马路划出三个车道给领导外宾通过,另外一个车道给我们使用,优先保证领导先行,就是这个道理。这个方法本身是一种常规的做法,即使在一个大

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











