







 超级会员免费看
超级会员免费看
文章目录
一.系统简介
Kyuubi 的中文译名是“九尾狐”,狐会喷火,用来致敬 Apache Spark,九代表多租户能力,最后的BI揭示我们最初面向的是大数据的BI场景。所以我们的图标是一只狐狸。
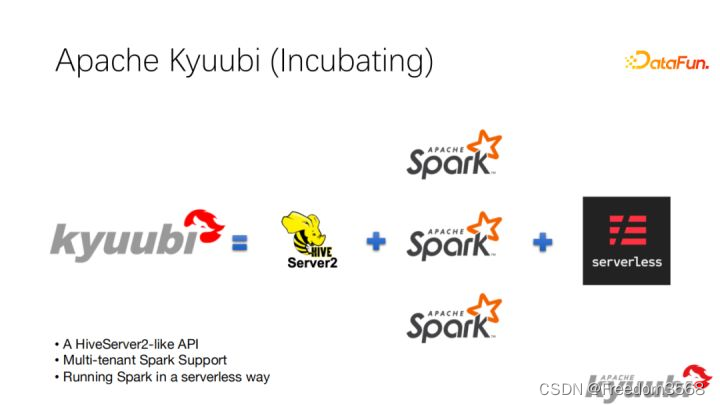
Kyuubi 是一个 Thrift JDBC/ODBC 服务,目前对接了 Apache Spark 计算框架,支持多租户和分布式等特性,可以满足企业内诸如 ETL、BI 报表等多种大数据场景的应用。
Kyuubi 的服务层提供JDBC等标准化的接口,隐藏底层计算框架、存储系统,开箱即用,用户无需编写和配置 Spark 程序,大大降低用户使用门槛。
我们通过 Kyuubi 的引擎层封装完整的 Spark SQL 能力,提供高性能的大数据分析处理能力。首先,它可以Run anywhere,既可以支持跑在传统的 YARN 集群上,也支持 K8s 集群;其次,通过 Spark SQL DataSource API 的强大能力,可以让我们轻松的将传统大数据数仓和数据湖框架串联起来,构建湖仓一体。最后,通过服务化,SQL 化的方式提供大数据处理能力,也可以大大提升底层开发运维同学的工作效率。一方面可以更加方便的去诊断和调优,另一方面可以做充分的鉴权认证,保证数据安全,也可以简化部署、升级等日常运维工作。
所以,从现阶段的核心能力来说,Kyuubi 提供了一个兼容 HiveServer2 协议的接口,加上在Spark

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











