




一、为什么要有线程池?
如果说,每提交一个任务,就创建一个线程去执行任务,那线程呢?是一种系统资源,会占用栈内存,如果说线程不断的创建,就会造成内存的溢出,所以线程池就是来控制线程的一个数量,来体现一种池化的思想,复用线程去处理任务。
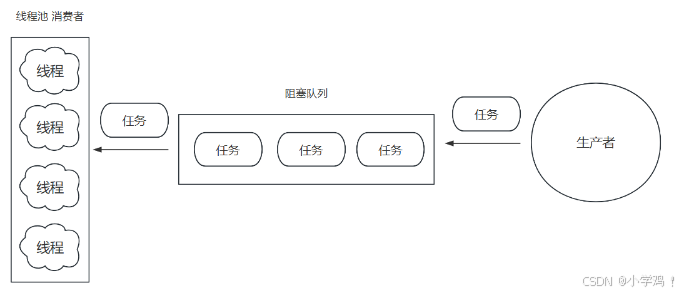
下面是手动实现一个简易线程池的示例,可以更好理解线程池:
二、手撕自定义线程池
2.1 定义阻塞队列
/**
* 定义一个阻塞队列
* T 代表任务类型
*/
@Slf4j
public class MyBlockQueue<T> {
// 创建一个队列:Deque有很多实现类,大多数情况下使用ArrayDeque
private Deque<T> deque = new ArrayDeque<>();
// 队列的容量
private int size;
/*
为什么定义锁?
生产者往阻塞队列去添加任务,消费者从队头拿任务
线程(生产者/消费者)可能有很多,任务(任务队列)只有一个,多线程去共享我们的一个资源,就会带来线程安全的问题
*/
private ReentrantLock lock = new ReentrantLock();
/*
有了锁之后,定义两个条件变量,干嘛?
当消费者去队列拿任务的时候,如果队列是空的,就让这个线程去休息室等待
当生产者往队列添加任务的时候,如果队列是满的,就让这个线程去休息室等待
*/
// 空的休息室
Condition emptyCondition = lock.newCondition();
// 满的休息室
Condition fullCondition = lock.newCondition();
public MyBlockQueue(int size) {
this.size = size;
}
/* 定义方法:从队列中拿任务、给队列里面放任务 */
// 添加任务
// 阻塞添加,假如队列一直是满的,就一直等待
public void put(T task) {
//添加的时候,生产者可能有多个,而队列只有一个,那多线程访问共享资源,可能会有线程安全的问题,所以需要加锁
lock.lock();
try {
//队列满了
while (deque.size() == size) {
log.debug("====== 队列已满,生产者正在等待...... ======");
try {
fullCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
deque.addLast(task);
log.debug("task 添加成功,{}", task);
//唤醒消费线程
emptyCondition.signal();
} finally {
lock.unlock();
}
}
//上面是阻塞添加,这个是带超时时间阻塞添加
public boolean offer(T task, long timeout, TimeUnit timeUnit) {
lock.lock();
try {
//把时间转为纳秒:以便后续使用awaitNanos方法
long nanos = timeUnit.toNanos(timeout);
//队列满了
while (deque.size() == size) {
try {
if (nanos <= 0) {
log.debug("====== 队列已满,生产者已等待" + timeUnit.toSeconds(timeout) + "秒,已超时...... ======");
return false;
}
log.debug("task 等待加入任务队列...");
nanos = fullCondition.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
deque.addLast(task);
log.debug("task 加入任务队列成功,{}", task);
emptyCondition.signal();
return true;
} finally {
lock.unlock();
}
}
// 获取任务
// 阻塞消费,假如队列一直是空的,就一直等待
public T take() {
//获取的时候,消费者可能有多个,而队列只有一个,那多线程访问共享资源,可能会有线程安全的问题,所以需要加锁
lock.lock();
try {
//队列为空
while (deque.isEmpty()) {
log.debug("====== 队列为空,消费者正在等待...... ======");
try {
emptyCondition.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = deque.removeFirst();
//唤醒生产者线程
fullCondition.signal();
log.debug("获取了任务 {}", t);
return t;
} finally {
lock.unlock();
}
}
//上面是阻塞获取,这个是带超时时间阻塞获取
public T poll(long timeout, TimeUnit timeUnit) {
lock.lock();
try {
//把时间转为纳秒:以便后续使用awaitNanos方法
long nanos = timeUnit.toNanos(timeout);
//队列为空
while (deque.isEmpty()) {
try {
if (nanos <= 0) {
log.debug("====== 队列为空,消费者已等待" + timeUnit.toSeconds(timeout) + "秒,已超时...... ======");
return null;
}
log.debug("等待获取任务 task...");
nanos = emptyCondition.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = deque.removeFirst();
//唤醒生产者线程
fullCondition.signal();
log.debug("获取了任务 {}", t);
return t;
} finally {
lock.unlock();
}
}
// 拒绝策略
public void tryPut(MyRejectPolicy<T> myRejectPolicy, T task) {
lock.lock();
try {
// 任务队列满了
if (deque.size() == size) {
// 队列满了,执行拒绝策略
// this 指当前类的实例化对象
myRejectPolicy.reject(this, task);
} else {
deque.addLast(task);
log.debug("task 加入任务队列成功,{}", task);
// 唤醒消费者线程
emptyCondition.signal();
}
} finally {
lock.unlock();
}
}
}
关于上面代码中难点: ReentrantLock 中的 Condition ,可以学习这两篇文章:
2.2 定义线程池
/**
* 定义线程池
*/
public class MyThreadPool {
// 引入阻塞队列
MyBlockQueue<Runnable> blockQueue;
// 线程池里面肯定有很多个线程,定义线程集合:动态增加或移除线程
// Set<Thread> set = new HashSet<>();
// 为了更好的扩展性,我们对Thread进行一个包装
final Set<MyThread> set = new HashSet<>();
// 核心线程数
int corePoolSize;
long timeOut;
TimeUnit timeUnit;
// 引入拒绝策略
MyRejectPolicy<Runnable> myRejectPolicy;
public MyThreadPool(MyBlockQueue<Runnable> blockQueue, int corePoolSize, long timeOut, TimeUnit timeUnit, MyRejectPolicy<Runnable> myRejectPolicy) {
this.blockQueue = blockQueue;
this.corePoolSize = corePoolSize;
this.timeOut = timeOut;
this.timeUnit = timeUnit;
this.myRejectPolicy = myRejectPolicy;
}
// 处理任务:把任务传进去
// 这个方法后期可能有很多的线程执行(也就是有很多线程去访问这个方法),而且操作的还是同一个集合,所以最好加锁
public void execute(Runnable task) {
synchronized (set) {
// 当前线程池中的线程数小于核心线程数时,就直接创建新线程执行任务
if (set.size() < corePoolSize) {
// 创建新的线程
MyThread myThread = new MyThread(task);
// 添加到线程集合
set.add(myThread);
// 启动线程
myThread.start();
}
// 超过核心线程数时,任务会被放入阻塞队列,等待线程执行
else {
//将任务放到阻塞队列
// blockQueue.put(task);
//最后定义:决绝策略
//当任务队列满了,还可以执行很多的方案
//比如:可以阻塞等待
//让调用者抛异常
//让调用者来执行这个任务
/*
上面每一个方案其实就是一个if条件,如果说有很多很多个方案,
这边就需要写很多个if else,直接将这个权利交给调用者:调用者
想实现什么样的逻辑,就调用者自己实现这个接口,所以需要创建一个
拒绝策略的接口
*/
blockQueue.tryPut(this.myRejectPolicy, task);
}
}
}
//定义线程类
public class MyThread extends Thread {
//线程要处理任务,所以要接收任务
private Runnable task;
public MyThread(Runnable task) {
this.task = task;
}
//处理任务的逻辑
@Override
public void run() {
/*
* task!=null 说明是新创建的线程,执行任务
* task = blockQueue.take() != null 从阻塞队列里拿任务 没带超时时间
* task = blockQueue.poll(timeOut, timeUnit) != null 从阻塞队列里拿任务 带超时时间
*/
// 每个线程不断从任务队列获取任务,直到队列为空且无超时任务。
while (task != null || (task = blockQueue.poll(timeOut, timeUnit)) != null) {
try {
// 调Runnable任务(也就是自己任务)中的run方法,执行任务
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 当这个任务执行完之后,置为null,不然的话,循环是死循环
task = null;
}
}
// 循环执行完后,说明队列中没有任务,且也没有新任务
// 任务已经全部执行完了,移除执行该任务的线程
// 所以:在任务完成后,将线程从线程池中移除,避免资源浪费。
// this 指当前类的实例化对象,也就是 new MyThread()
// 由于到时候有多个线程,也操作这个set集合,所以也需要锁
synchronized (set) {
set.remove(this);
}
}
}
}
2.3 拒绝策略
是一个接口,允许用户自定义队列满时的自定义行为
/**
* 自定义拒绝策略
* @param <T> 任务类型
*/
public interface MyRejectPolicy<T> {
/**
* 提供一个方法
* @param myBlockQueue 阻塞队列
* @param t 任务
*/
void reject(MyBlockQueue<T> myBlockQueue, T t);
}
2.4 调用自定义线程池
/**
* 入口
*/
@Slf4j
public class Main {
public static void main(String[] args) {
// 创建自定义的线程池(也就是实例化类)
/**
* new MyBlockQueue<>(5) 实例化阻塞队列,队列长度为5
* 2 核心线程数
* 5 超时时间
* TimeUnit.SECONDS 超时时间单位
* 实现拒绝策略的接口
*/
MyThreadPool myThreadPool = new MyThreadPool(new MyBlockQueue<>(5), 2, 5, TimeUnit.SECONDS, new MyRejectPolicy<Runnable>() {
@Override
public void reject(MyBlockQueue<Runnable> myBlockQueue, Runnable task) {
// 拒绝策略:
// 一直等(阻塞等待)
// myBlockQueue.put(task);
// 调用者直接执行任务
// task.run();
// 直接抛出异常
// throw new RuntimeException("zfp");
// 丢弃这个任务
log.debug("丢弃这个任务{}", task);
}
});
myThreadPool.execute(new Runnable() {
// 提交一个简单的任务:张三去打水......
@Override
public void run() {
System.out.println("张三去打水......");
}
});
}
}
实现代码的运行结果:

结果分析:
第一行:张三去打水......
- 这是因为
myThreadPool.execute提交了一个任务,线程池创建了一个核心线程Thread-0,并立即执行了这个任务。
第二行:等待获取任务 task...
- 任务执行完成后,
Thread-0的run方法继续运行。由于线程池的核心线程不会立即终止,它进入了循环并尝试从阻塞队列中获取新的任务。 - 因为队列是空的,线程调用了
poll方法,进入等待状态(等待 5 秒的超时时间)
第三行:队列为空,消费者已等待5秒,已超时......
- 等待时间达到 5 秒后,队列仍然没有新任务,线程池的
poll方法返回null,线程退出循环,最终终止。
- 核心线程数为
2,但只提交了一个任务,且队列为空。- 线程池不会立即销毁核心线程,而是让它们继续运行以等待新任务。
- 如果队列一直为空且任务获取超时,线程会自然退出。
1、添加更多任务:main方法中加入
// 更多任务
for (int i = 0; i < 10; i++) {
final int taskId = i;
myThreadPool.execute(() -> {
System.out.println("任务 " + taskId + " 执行中...");
});
}
2、运行结果:
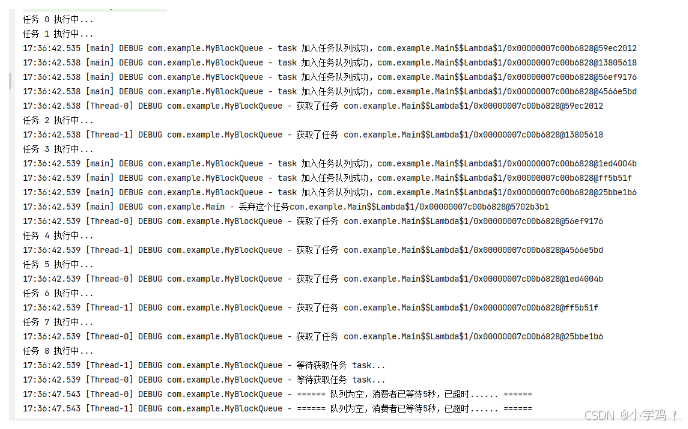
分析:
-
核心线程池大小为 2,线程池首先启动两个核心线程
Thread-0和Thread-1,立即开始处理任务。 -
阻塞队列用于存储多余的任务。
-
核心线程
Thread-0和Thread-1完成任务后,从队列中取出任务继续执行。队列为空时,核心线程阻塞等待 5 秒,无新任务后超时退出。队列任务
2 ~ 8被依次处理,任务执行输出顺序可能与提交顺序不同,取决于线程调度。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











