



研究动机
背景
:电力负荷预测对电网的安全和稳定至关重要,有助于避免电力过载和电压波动等问题。准确预测负荷有助于降低发电成本,
提高能源利用效率。
传统方法
:传统预测方法通常依赖数学模型,难以捕捉电力负荷的非线性、时序变化性和复杂性。在处理大规模、高维度数据时
精度有限,难以满足现代电力系统对负荷预测的高精度要求。而且容易受到多种因素的影响,如天气、节假日、政策等,导致预
测结果波动较大。
机器学习优势
:机器学习算法能够处理大规模、高维度的数据,挖掘数据中的隐藏规律和特征,提高预测精度。还能够自适应地
调整模型参数,适应电力负荷的变化特性,具备较好的泛化能力。而且还可以融合多种特征,如天气、时间、历史负荷等,进行 综合分析预测,提高预测准确性。
研究内容
:对比三种模型
•
随机森林:
处理非线性关系,对噪声具有较强的鲁棒性,适用于短期预测
•
支持向量回归
:适用于高维数据和小样本数据,能够捕捉复杂的非线性关系,适合处理季节性波动较大的数据
•
LSTM
:
专门处理时间序列数据,能够记住长期依赖信息,适用于长期预测,适合处理季节性和趋势线的时序数据
研究目标
:分析不同算法的预测精度、可解释性和泛化能力,为电力负荷预测提供更全面的参考
利益相关者:电力行业的决策者和管理人员、能源技术研究人员和数据科学家、电力系统工程师和运营团队、 政策制定者与政府部门、能源投资者与企业决策者
数据集介绍
(数据地址:https://www.kaggle.com/datasets/stefancomanita/hourly-electricity-consumption-and-production/data)
Dataset
基本信息
•
数据来源
Hourly Electricity Consumption and Production
(
Kaggle
公开数据)
•
数据时间范围:
5
年以上罗马尼亚每个整点电力数据,从
2019-2024
•
数据规模:共
46,012
条记录,文件名
electricityConsumptionAndProductioction.csv
•
预测目标:预测某天某个整点的电力消耗值
数据特征
•
时间序列数据(按小时记录),适用于时间序列建模
•
涵盖
5
年以上,可以分析长期趋势和季节性变化
•
包含多个能源来源,可用于研究不同能源的贡献率和依
赖程度
•
可计算电力进出口情况(生产
-
消耗)
数据质量
:数据集没有缺失值,但风力发电的最小值为负
值,可能是数据异常。
字段介绍
•
记录时间
:
TimeStamp(
格式为
YYYY-MM-DD HH:00)
•
每小时的总电力消耗量
:
Consumption (MW)
•
每小时的总电力生产量
:
Total Production (MW)
•
核能发电量
:
Nuclear (MW)
•
风力发电量
:
Wind (MW)
•
水力发电量
:
Hydroelectric (MW)
•
石油和天然气发电量
:
Oil and Gas (MW)
•
煤炭发电量
:
Coal (MW)
•
太阳能发电量
:
Solar (MW)
•
生物质能发电量
:
Biomass (MW)
2.2
基本描述性统计
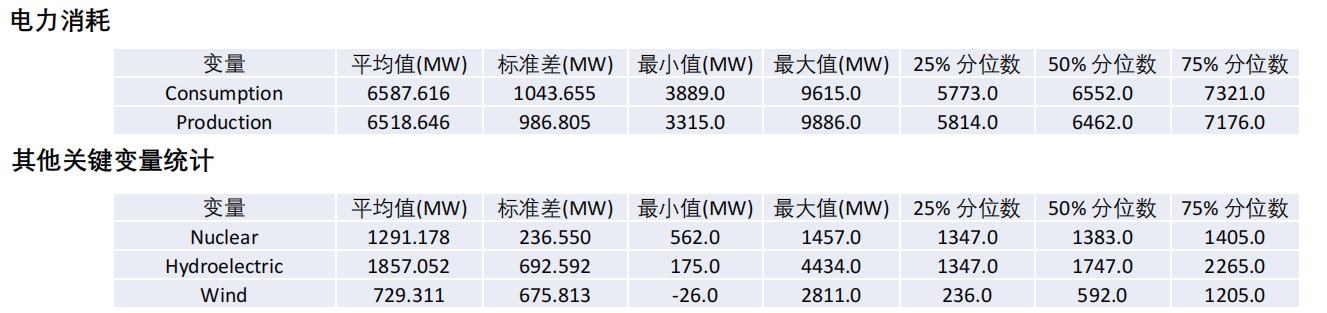
从统计数据来看:
•
电力消耗和电力生产相近,且波动性较高,表明电力供需存在较大的变化。
•
电力消耗和电力生产的极值差异显著,且两者均远高于平均值,表明在某些时段电力需求和生产可能达到峰值,对电网稳定性提出挑
战。
•
核能发电稳定但规模有限,且分位数变化较小。
•
水力发电波动性较大,且最大值远高于其他分位数,表明水力发电受季节性或其他因素影响较大。
•
风力发电波动性大,受自然条件影响显著,具有较高的潜力但稳定性较差。
Dataset
可视化结果
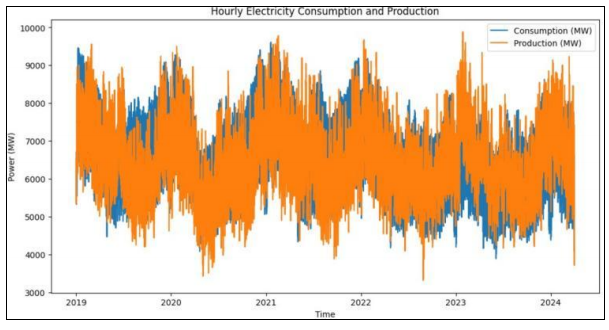
电力消耗和生产时间序列图
•
电力消耗和生产的波动具有明显的周期性
•
电力消耗和生产的变化趋势基本一致
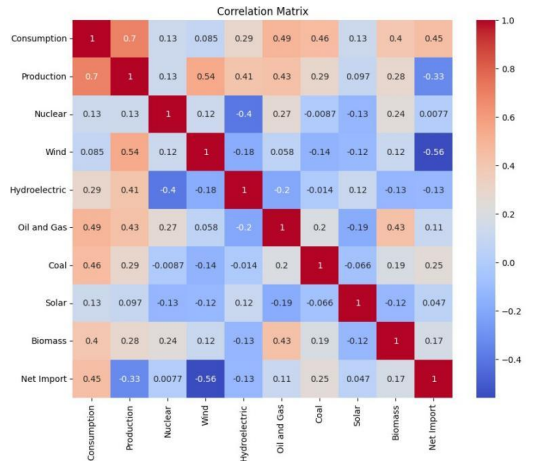
电力消耗与生产相关性矩阵
• 电力消耗与电力生产之间的相关性较高 (
0.7
),表明电力生产对电力消耗有直接影响。
•
电力消耗与石油和天然气发电(
0.49)、 煤炭发电(
0.46)的相关性也较高, 表明这些能源类型对电力负荷的贡献较大。
•
风力发电与电力生产的相关性为
0.54,表明风力发电对电力生产的贡献也较为显著。
• 风力发电与电力消耗的相关性较低 (
0.085
),可能是由于风力发电的波动性较大。
数据预处理
1.
异常值处理
•
数据集描述中风力发电最小值为负值,可能是数据异常。但无更多数据作为异常值处理上下文参考,先不处理。
该数据对目标值影响较小
2.
缺失值填充
•
数据集无缺失值
3.
数据读取与时间索引设置
•
将
DateTime
列转换为时间格式,设置为索引,便于时间序列分析
4.
特征与目标变量分离
•
使用
StandardScaler
对特征数据进行标准化处理,使得数据均值为
0
,方差为
1
,便于模型训练
5.
滚动窗口交叉验证
•
使用
TimeSeriesSplit
进行时间序列的滚动窗口交叉验证,确保训练集和测试集的划分符合时间顺序,避免数据泄露
•
第一次数据集划分,训练集前
25%
的数据,测试集接下来
25%
的数据
•
第二次数据集划分,训练集前
50%
的数据,测试集接下来
25%
的数据
•
第三次数据集划分,训练集前
75%
的数据,测试集接下来
25%
的数据
模型介绍
随机森林
随机森林(
Random Forest, RF
)是一种基于集成学习的机器学习方法,通过构建多棵决策树并集成其预测结果来提高模型的
准确性和鲁棒性。它属于
Bagging
(
Bootstrap Aggregating
)算法的一种,适用于分类和回归任务。
核心思想
1. Bootstrap
采样
•
从训练集中随机抽取样本(有放回),生成多个子数据集
•
对于训练集
D
中的
N
个样本,每次采样生成一个子集
D
i
,其中
D
i
包含
N
个样本(可能有重复)
2.
随机特征选择
•
在每棵决策树的节点分裂时,随机选择部分特征(通常为
?
或
log2(m)
,
?
为总特征数)进行分裂,增加模型的多样性。
3.
集成预测:
•
对于分类任务,采用投票法(多数表决)确定最终结果。
•
对于回归任务,采用平均法计算最终结果。
• 公式(回归任务):
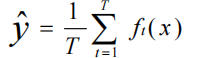 其中,
T
为树的数量,
f
t
(x)
为第
t
棵树的预测结果。
其中,
T
为树的数量,
f
t
(x)
为第
t
棵树的预测结果。
其中,
T
为树的数量,
f
t
(x)
为第
t
棵树的预测结果。
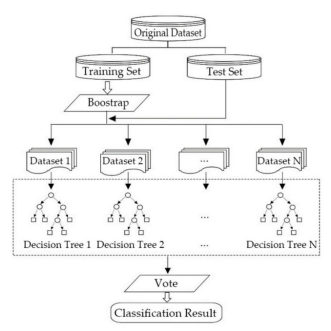 随机森林原理图来源:https://www.researchgate.net/figure/Architecture-of-the-Random-Forest-algorithm_fig1_337407116
随机森林原理图来源:https://www.researchgate.net/figure/Architecture-of-the-Random-Forest-algorithm_fig1_337407116
支持向量回归
核心思想
•
找到超平面,使数据点落在
ε-
不敏感带内
•
使曲线尽可能平坦,避免过拟合和噪声
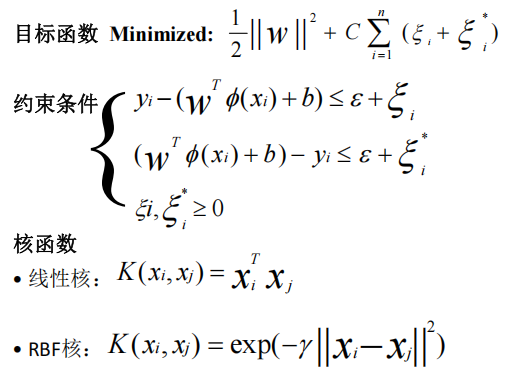
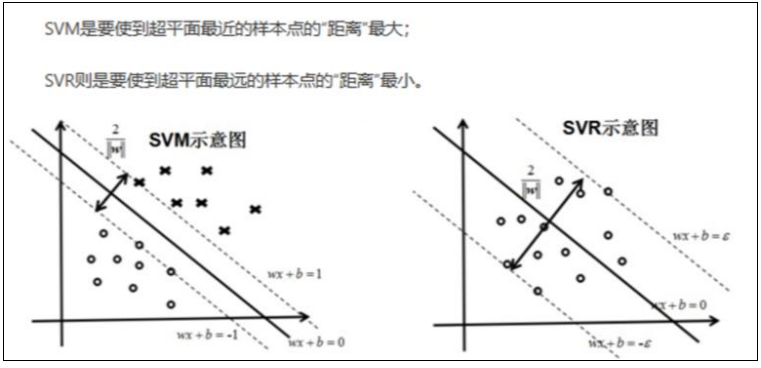
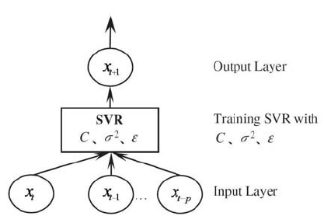 svr原理图来源:https://www.researchgate.net/figure/Basic-architecture-of-SVR-model_fig3_228677761
svr原理图来源:https://www.researchgate.net/figure/Basic-architecture-of-SVR-model_fig3_228677761
LSTM
核心思想
•
引入门控机制,解决
RNN
梯度消失问题
•
捕捉时间序列中的长期依赖关系
LSTM
单元结构
•
细胞状态(长期记忆)
•
隐藏状态(短期记忆)
•
三个门控机制(输入门、遗忘门、输出门)
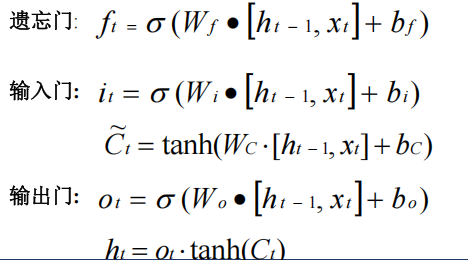
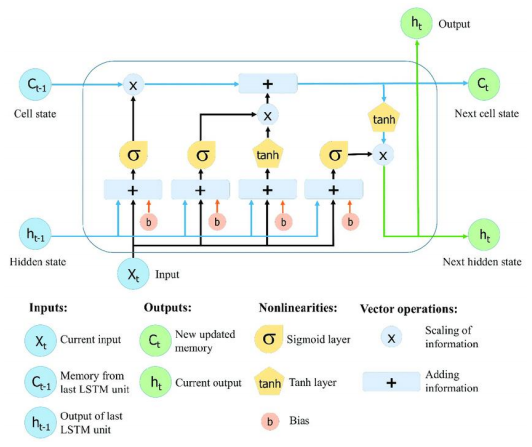
LSTM结构图来源:https://www.researchgate.net/figure/The-structure-of-the-Long-Short-Term-Memory-LSTM-neural-network-Reproduced-from-Yan_fig8_334268507
实验设置
采用时间序列交叉验证,通过手动遍历给定的超参数组合进行超参数调优。
超参数搜索范围
LSTM
• units(
神经元数量
)
:
[32,64,128]
• learning_rate(
学习率):
[0.001,0.01]
随机森林
• n_estimators(
树的数量
)
:
[100,200,300]
• max_depth(
最大深度
)
:
[None,10,20,30]
• max_features(
最大特征数
)
:
[‘sqrt’,’log2’]
实验结果(最优超参数)
•
随机森林:
n_estimators=300,max_depth=None,max_features=sqrt
•
支持向量回归:
kernel=linear,C=10,epsilon=0.01
• LSTM
:
units=128,learning_rate = 0.01
支持向量回归
• kernel(
核函数
)
:
[‘linear’,’poly’,’rbf’]
• C(
正则化参数
)
:
[0.1,1,10]
• epsilon(
误差容忍度
)
:
[0.01,0.1,0.2]
这些值是哪里来的呢?是我们翻阅论文和各个炼金师论坛,找到的推荐的默认值。超参数调优是需要算力和时间的,现有条件限制,我们先试用这些推荐的参数看看模型怎么样。
模型评估

实验结果
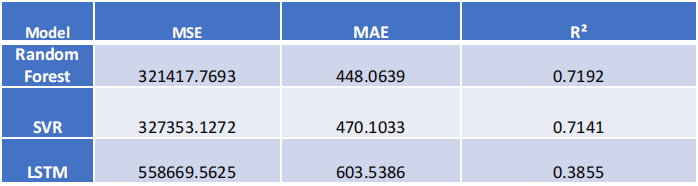
LSTM
:预测误差较大且不稳定,未能有效捕捉数据的内在规律。
表现:误差最大,稳定性最差
• MSE
波动较大,预测误差大,高于随机森林和
SVR
• MAE
波动较大,高于随机森林和
SVR
• R²
波动大,交叉验证前两次出现负值
原因分析:
•
数据量不足。
LSTM
是一种深度学习模型,通常需要大量数据才能有效训练。如果数据量不足,模型可能
无法学习到有效的时间序列模式。
•
超参数选择不佳。虽然选择了
`units=128`
和
`learning_rate=0.01`,但这些超参数可能并不适合当前数据集。 可能需要进一步调整超参数(如增加
`units`
、调整
`learning_rate`
或增加训练轮数)。
•
训练时间不足。
LSTM
的训练时间较长,如果训练轮数(
epochs
)不足,模型可能未能充分收敛。
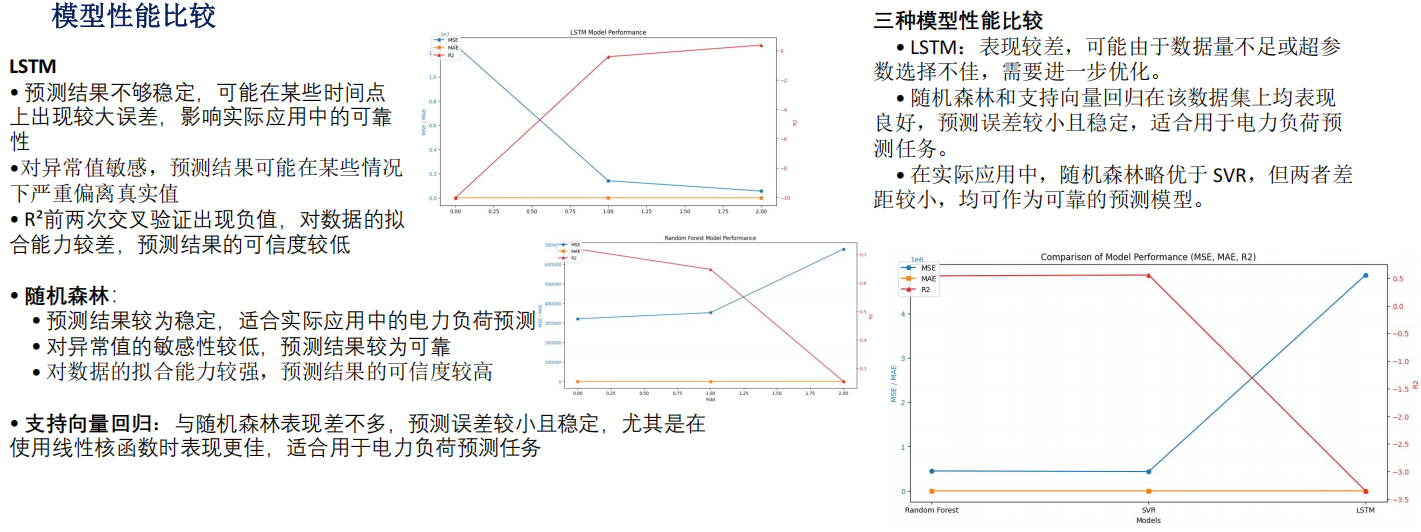
结论
:
LSTM 模型在该数据集上表现较差,主要原因可能是数据量不足、超参数选择不佳、模型训练时间不足等原因。

结论
研究总结
•
本研究基于电力负荷预测数据集,对随机森林、支持向量回归
(SVR)
和
LSTM
进行了对比实验,以评估不同机器学习方
法在电力负荷预测任务中的表现。
•
采用
MSE
、
MAE
和
R²
作为主要评估指标,分析模型的预测误差、稳定性和拟合能力。
实验结论
•
随机森林预测效果最佳。通过集成学习和非线性关系捕捉,能够有效建模电力负荷的复杂模式,预测结果稳定且可靠
•
支持向量回归
(SVR)
表现良好
。
SVR
通过线性核函数和正则化参数,能够平衡模型的复杂度和泛化能力,适合线性可
分数据,预测结果较为稳定
• LSTM
表现较差可能由于数据量不足、超参数选择不佳或模型复杂度较高,未能有效捕捉时间序列模式,预测结果不
稳定。
研究局限性
•
数据量不足
。
LSTM
作为深度学习模型,需要大量数据才能有效训练,当前数据量可能不足以支持其充分学习时间序
列模式。
•
超参数选择有限
。
实验中超参数搜索范围较窄,可能未能找到最优的超参数组合,尤其是对
LSTM
模型的优化不足。
•
模型扩展方向
。
未来可尝试更多时间序列模型(如
GRU
、
Transformer
),或引入外部特征(如天气数据、节假日信息)
以提升预测精度。对于
LSTM
模型,可以增加数据量、调整超参数范围或使用更复杂的网络结构来改进性能。
其它需要可优化方面
随机森林(RF)模型,如何提高可解释性?
稳定模型:
RF模型在训练前需要设置固定的随机种子(如random_state参数),确保每次运行的子数据集划分和特征选择一致。通过网格搜索或贝叶斯优化确定稳定的超参数组合(如n_estimators、max_depth),避免参数敏感性问题。
SVR模型:选择稳定的核函数(如RBF),并通过交叉验证固定惩罚因子C和核参数γ。对输入特征进行标准化(如Z-score),避免尺度差异影响模型收敛。
LSTM模型:设置initializer='glorot_uniform'等确定性初始化方法,避免训练初期的随机性。
在LSTM层后加入BatchNormalization层,减少内部协变量偏移带来的波动。

















 307
307

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









