




 本文深入探讨Home Credit Default Risk问题,通过加载和预览数据,分析了不同目标变量的风险分布,检查了缺失值情况,并讨论了非数值特征的编码策略,包括LabelEncoder和one-hot Encoder的应用及其可能带来的维数问题。
本文深入探讨Home Credit Default Risk问题,通过加载和预览数据,分析了不同目标变量的风险分布,检查了缺失值情况,并讨论了非数值特征的编码策略,包括LabelEncoder和one-hot Encoder的应用及其可能带来的维数问题。
上篇中已经给出了application_{train|test}.csv数据表字段的基本含义,本篇对其进行基本的数据分析,包活异常数据处理,特征变换等,最后给出仅考虑此数据文件,应用logistic回归和random forest两种模型分别训练模型的方式。
加载数据并初步预览
# 导入需要的依赖包
import os
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
import numpy as np
from sklearn.preprocessing import LabelEncoder, MinMaxScaler, Imputer
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
dir_path = 'XXX/dataset'#替换为数据文件所在目录
print(os.listdir(dir_path))
结果如下:
[‘application_test.csv’, ‘application_train.csv’, ‘bureau.csv’, ‘bureau_balance.csv’, ‘credit_card_balance.csv’, ‘HomeCredit_columns_description.csv’, ‘installments_payments.csv’, ‘POS_CASH_balance.csv’, ‘previous_application.csv’, ‘sample_submission.csv’]
# 加载训练数据和测试数据
application_train_file = dir_path + '/application_train.csv'
application_test_file = dir_path + '/application_test.csv'
app_train = pd.read_csv(application_train_file)
app_test = pd.read_csv(application_test_file)
# 初步预览
print('Training data shape: ', app_train.shape)
app_train.head()
结果如下:
Training data shape: (307511, 122)
| SK_ID_CURR | TARGET | NAME_CONTRACT_TYPE | CODE_GENDER | FLAG_OWN_CAR | FLAG_OWN_REALTY | CNT_CHILDREN | AMT_INCOME_TOTAL | AMT_CREDIT | AMT_ANNUITY | ... | FLAG_DOCUMENT_18 | FLAG_DOCUMENT_19 | FLAG_DOCUMENT_20 | FLAG_DOCUMENT_21 | AMT_REQ_CREDIT_BUREAU_HOUR | AMT_REQ_CREDIT_BUREAU_DAY | AMT_REQ_CREDIT_BUREAU_WEEK | AMT_REQ_CREDIT_BUREAU_MON | AMT_REQ_CREDIT_BUREAU_QRT | AMT_REQ_CREDIT_BUREAU_YEAR | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 100002 | 1 | Cash loans | M | N | Y | 0 | 202500.0 | 406597.5 | 24700.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 100003 | 0 | Cash loans | F | N | N | 0 | 270000.0 | 1293502.5 | 35698.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 100004 | 0 | Revolving loans | M | Y | Y | 0 | 67500.0 | 135000.0 | 6750.0 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 100006 | 0 | Cash loans | F | N | Y | 0 | 135000.0 | 312682.5 | 29686.5 | ... | 0 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 100007 | 0 | Cash loans | M | N | Y | 0 | 121500.0 | 513000.0 | 21865.5 | ... | 0 | 0 | 0 | 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5 rows × 122 columns
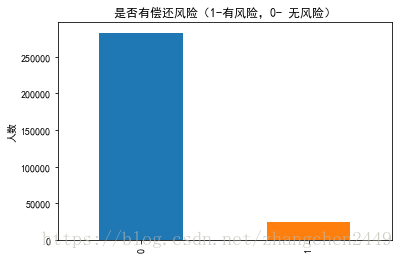
1.根据TARGET在不同分类下的数量绘制整体风险直方图
# 1.根据TARGET在不同分类下的数量绘制整体风险直方图
app_train.TARGET.value_counts().plot(kind='bar')
plt.title("是否有偿还风险(1-有风险,0- 无风险)")
plt.ylabel("人数")
plt.show()
2.检查缺失数据整体情况(对于缺失值的处理可以舍弃,补中位数,补均值,RF预测,XGBoost预测等)
# 2.检查缺失数据整体情况
def examine_missing_data(df):
missing = df.isnull().sum().sort_values(ascending=False)
missing_percent = (100 * df.isnull().sum() / len(df)).sort_values(ascending=False)
missing_table = pd.concat([missing, missing_percent], axis=1)
missing_table = missing_table.rename(columns={
0: '缺失值数量', 1: '缺失值占比(%)'})
missing_table = missing_table[missing_table.iloc[:, 1] != 0]
print("数据总共有%d个特征,其中存在缺失值的特征数为%d" % (df.shape[1], missing_table.shape[0]))
return missing_table
missing_values = examine_missing_data(app_train)
missing_values.head(10)
结果如下:
数据总共有122个特征,其中存在缺失值的特征数为67
| 缺失值数量 | 缺失值占比(%) | |
|---|---|---|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2737
2737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









