




 本文介绍了基于Java爬虫框架webMagic进行爬虫开发的过程。内容涵盖webMagic的组件结构,包括Downloader、PageProcessor、Pipeline和Scheduler,并通过实例讲述了如何定制PageProcessor和Pipeline,爬取马蜂窝旅游网站的热门城市和景点信息。
本文介绍了基于Java爬虫框架webMagic进行爬虫开发的过程。内容涵盖webMagic的组件结构,包括Downloader、PageProcessor、Pipeline和Scheduler,并通过实例讲述了如何定制PageProcessor和Pipeline,爬取马蜂窝旅游网站的热门城市和景点信息。
最近由于毕设一定的数据源,故需要进行爬虫方面的开发,网上的爬虫框架很多,包括scrapy(基于python),PySpider(基于python),webMagic(基于Java)等等。在网上查找了一番资料后选定webMagic,一方面它可以基于Java进行爬虫的开发,更重要的还是它的学习成本很低,官方文档简单易懂(国人开发,中文文档)。作者提供了一组高效而简洁的api,使得我们能用少量的代码就能实现爬虫的开发。
什么是webMagic?

webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
作者的说法:
WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。
特性:
- 简单的API,可快速上手
- 模块化的结构,可轻松扩展
- 提供多线程和分布式支持
webMagic组件结构
主要有四个组件:Downloader,PageProcessor,Pipeline,Scheduler。通过Spider则将这几个组件组织起来,让它们可以互相交互,流程化的执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
附官方提供的webMagic结构图:
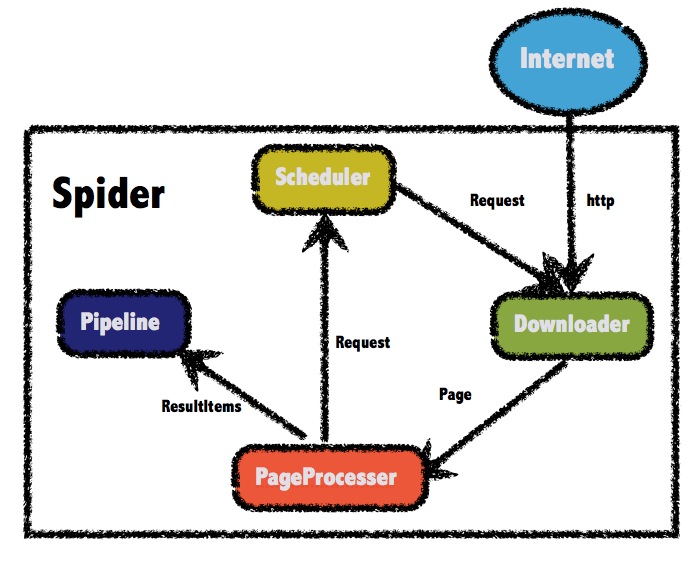
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
基于webMagic进行爬虫开发
本次实践案例是爬取马蜂窝的热门旅游城市及对应城市下的所有旅游景点信息
不得不说马蜂窝旅游网的UI设计还是蛮赞的,相对于其他旅游网站很清新简洁,首页的大轮播图还提供了一种强烈的视觉冲击,给人很舒服的观感。
1.爬虫开发的步骤:
- 数据爬取:实现PageProcessor(PageProcessor的定制)
- 爬虫的配置
- 页面元素的抽取
- 链接的发现
- 数据持久化:使用Pipeline保存结果(定制Pipeline)
- 保存结果到文件、数据库等一系列功能
- 数据整理(利用SQL脚本将数据进行规范整理)
2. 爬取目标信息
1. 链接发现
爬取马蜂窝旅游网热门旅游城市及该城市的介绍信息(暂定国内);
爬取该城市下的所有旅游景点详细信息;

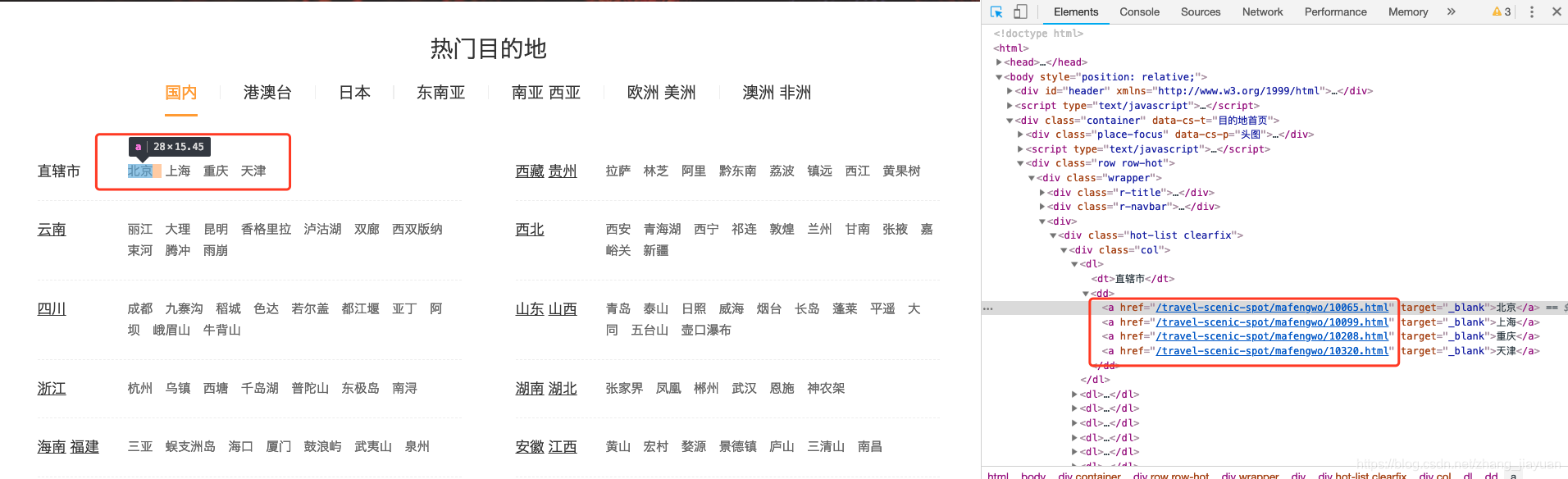
2. 在页面打开链接:https://www.mafengwo.cn/mdd/,按f12,可以看到,每个城市对应的详情链接大致一样"/travel-scenic-spot/mafengwo/10065.html",只有在.html前面的数字串不一样,这应该是马蜂窝网内部定义的城市编号信息,用于作为不同城市的标识。
3. 点开一个北京链接的页面,可以发现本页并没有关于北京市的详细介绍,其实具体介绍在深入另一个页面,即下图 "景点",是一个新的链接“/jd/10065/gonglve.html”,同样带了一个标识城市的数字串,与上面的是一致的10065。点击进去。

4. 是的,我们要的信息找到了,城市名,城市介绍,图片等信息(该城市下的图片在本页有,不做过多截图)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1610
1610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









