




目录
三- FlinkCDC采集mysql 到 mysql的demo
2- 创建一个用户,权限 SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT 。必须有reload
3- 将flink-cdc-connectors的 jar包放入 /lib 目录下。
4- 引入依赖 (注意 打包成 jar的时候,不要打包进去。不然会报错)
一 : 什么是CDC ?使用场景是什么?
CDC是(change data capture),翻译过来就是 捕获数据变更。通常数据处理上,我们说的 CDC 技术主要面向 数据库的变更,是一种用于捕获数据库中数据变更的技术。
它的使用场景(作用)主要有:
1- 数据同步,用于备份,容灾
2- 数据分发,一个数据源分发给多个下游
3- 数据采集(E),面向数据仓库/数据湖的 ETL 数据集成
二: 目前有哪些技术
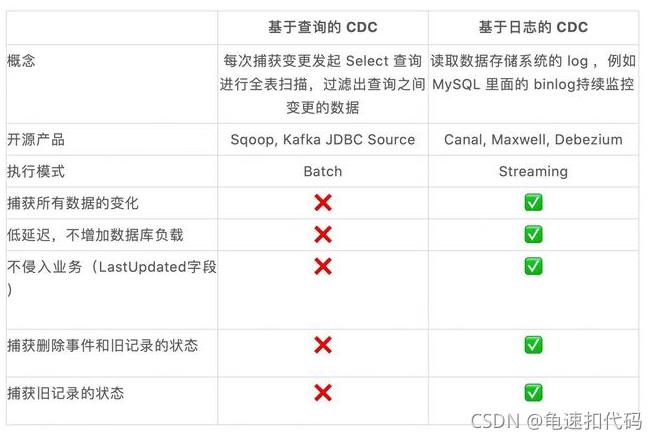
根据实现机制可以分为两个方向,基于查询和基于日志。
基于查询是就是select进行全表扫描过滤出变更的数据。
基于日志就是连续实时读取数据库的操作log,例如msyql的binlog
-
基于查询的 CDC:
-
离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
-
无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
-
无法保障实时性,基于离线调度存在天然的延迟。
-
影响数据库性能
-
-
基于日志的 CDC:
- 实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
- 保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
- 保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
因我们的业务场景是要求近实时(分钟级),所以必须采用基于binlog的技术,canal的demo可以参考我的另外文章。又因为 初始化时需要导入全量数据(msyql到kudu),canal得依赖其他的组件,需要保证数据完整一致性(数据不丢,不重复),且对数据库影响小(锁表先导入全量数据,在进行增量)。操作起来较为麻烦,此时FlinkCDC闪亮登场( 如何全量,增量和精准一次可参考)。

三- FlinkCDC采集mysql 到 mysql的demo
前置条件:Mysql 必须是 5.7 或 8.0.X
1- mysql必须开启binlog
server-id = <server-id> # 可以自定义,但必须唯一
log_bin = <mysql-bin> # 可以自定义,binlog文件的前缀名
binlog_format = ROW # 必须是row
binlog_row_image = FULL # 必须是full
2- 创建一个用户,权限 SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT 。必须有reload
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO '<flinkuser>'@'<mysqlADD>' identified by '<flinkuserPWD>';Flink必须是 1.12以上的,如果使用flinkCDC2.0且使用flinkSQL,必须是1.13,java 8
3- 将flink-cdc-connectors的 jar包放入 <FLINK_HOME>/lib 目录下。
下载网页flink-cdc-connector(包括了 mysql postgres和mongdb)
没放入可能会包找不到的错误
org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'mysql-cdc' that implements 'org.apache.flink.table.factories.DynamicTableFactory' in the classpath.
4- 引入依赖 (注意 打包成 jar的时候,不要打包进去。不然会报错)
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-mysql-cdc</artifactId>
<version>2.0.0</version>
<scope>provided</scope> <- 编译打包是不要打包进去,不然运行会报错->
</dependency> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2022
2022







 到【灌水乐园】发言
到【灌水乐园】发言







