




sanity check(合理性检查)
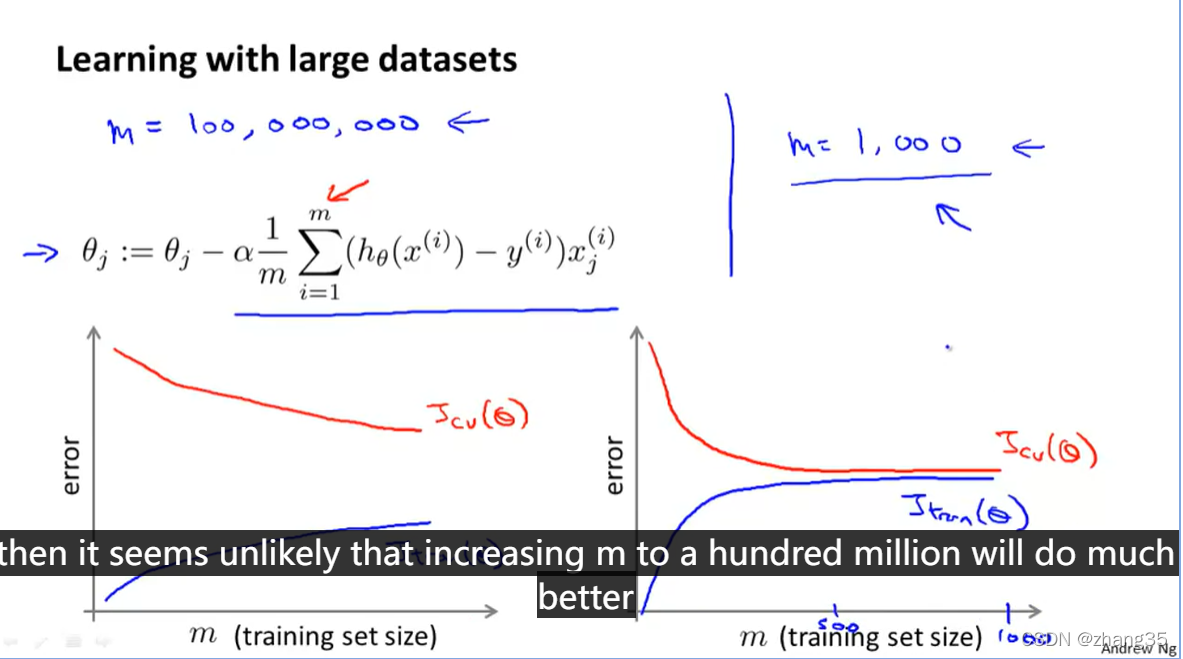
大数据量带来高计算代价,所以首先得确定,是不是大数据量有帮助?
检查Jcv 和 Jtrain 的学习曲线。
如果如左图,有高方差,则说明过拟合了,增加数据量有帮助;
如果如右图,增加数据量没有太大帮助。
随机梯度下降法(Stochastic Gradient Descent)
普通的梯度下降,当m很大时,下面蓝色方框的计算会耗时很高。
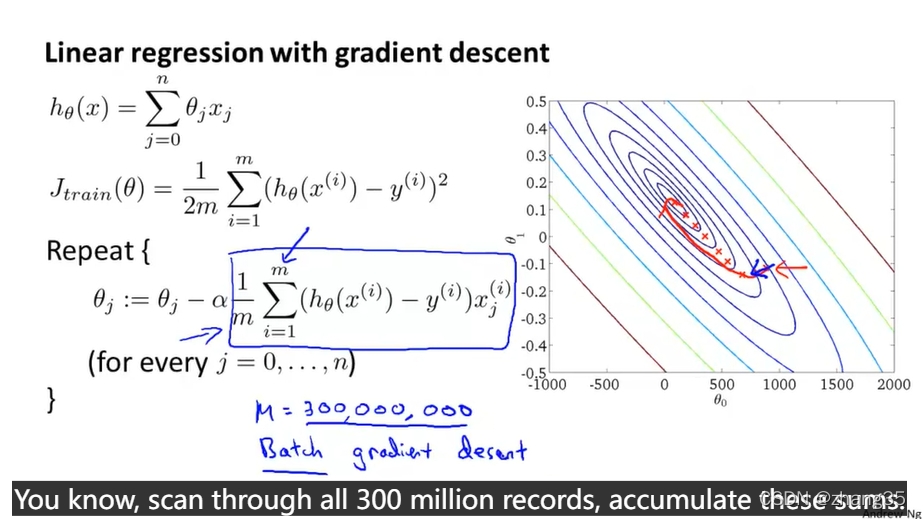
普通的梯度下降,又称为batch gradient descent,每次都需要读取所有数据。
这里就引出了随机梯度下降法。
- 随机shuffle数据集
- 每次考虑一条数据,向着这个数据进行一点梯度下降,来更好地fit它。
批量梯度下降每次都考虑全部数据集,相比之下,随机梯度下降少了一次求和操作(左侧红色方框),它随机地慢慢地改善。进一寸有一寸的欢喜。

梯度下降的方向,每次都没那么完美,但在曲折中前进,最终还是朝着全局最优解的方向去(虽然最终可能达不到全局最优):
通常这个过程(外部循环)重复1到10次。当m足够大时,1次就够了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









