






包含编程资料、学习路线图、源代码、软件安装包等!【[点击这里]】!
JSON 基础三连击
1. 字符串 ↔ Python 对象
import json
# JSON字符串 → Python对象
data = json.loads('{"name": "小明", "age": 18}')
print(data["name"]) # → 小明
# Python对象 → JSON字符串
json_str = json.dumps({"name": "小红", "age": 16})
print(json_str) # → {"name": "小红", "age": 16}
- json.loads()的’s’代表string!这就好比在数据的 “翻译” 过程中,loads专门负责把JSON格式的字符串 “翻译” 成Python 能识别的对象;与之相对,dumps则把Python对象“翻译”成JSON字符串。
2. 文件 ↔ Python 对象
# 读取JSON文件
with open("data.json", encoding="utf-8") as f:
data = json.load(f)
# 写入JSON文件
with open("output.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
- 在 JSON 文件的处理过程中,json.load与json.dump就像一对默契的搬运工,前者将文件中的JSON 数据搬进Python 程序,后者则把Python对象数据搬运到文件中存储。
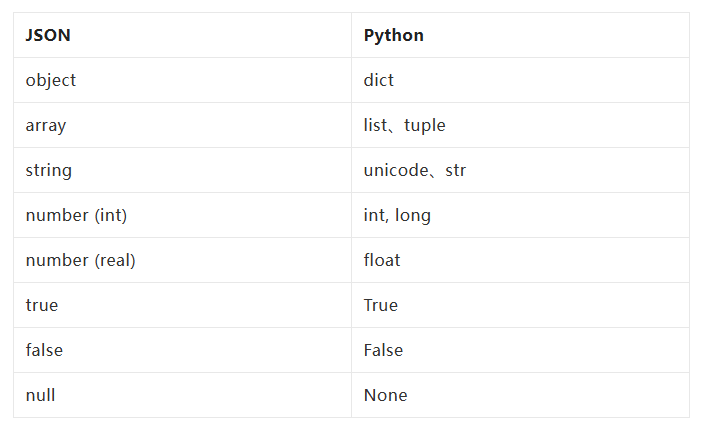
3.json数据和python数据类型对照表
- json字符串和python数据转换的对照表如下
六大实战案例
案例 1:处理 API 响应
import requests
response = requests.get("https://api.example.com/data")
data = response.json() # 直接获取Python对象
print(data["results"][0])
- 当我们从 API 获取数据时,response.json()就像一把万能钥匙,轻松将 API 返回的 JSON 数据转换成 Python 对象,方便我们进一步处理数据。
案例 2:自定义对象序列化
class User:
def __init__(self, name, age):
self.name = name
self.age = age
# 自定义编码器
def user_encoder(obj):
if isinstance(obj, User):
return {"name": obj.name, "age": obj.age}
raise TypeError
user = User("小明", 18)
json_str = json.dumps(user, default=user_encoder)
- 在处理自定义类对象时,默认的 JSON 序列化方法会 “不知所措”。
- 这时,我们自定义的user_encoder函数就像一位 “特殊翻译”,指导json.dumps如何将User对象转换成 JSON 格式,让数据能顺利在不同场景中流转。
案例 3:处理复杂数据类型
from datetime import datetime
from decimal import Decimal
import json
data = {
"time": datetime.now(),
"price": Decimal("99.99")
}
# 自定义序列化
def custom_encoder(obj):
if isinstance(obj, datetime):
return obj.isoformat()
if isinstance(obj, Decimal):
return float(obj)
raise TypeError
json_str = json.dumps(data, default=custom_encoder)
print(json_str)
- datetime和Decimal这类复杂数据类型,无法被 JSON 直接处理。
- 通过自定义的custom_encoder,我们将datetime对象转换成 ISO 格式字符串,将Decimal对象转换成float类型,从而突破 JSON 序列化的限制,让数据准确无误地进行转换和存储。
案例 4:多文件数据整合
import json
file_list = ["file1.json", "file2.json", "file3.json"]
combined_data = []
for file in file_list:
with open(file, encoding="utf-8") as f:
data = json.load(f)
combined_data.extend(data)
with open("combined.json", "w", encoding="utf-8") as f:
json.dump(combined_data, f, ensure_ascii=False, indent=2)
- 在项目开发中,常常需要整合多个 JSON 文件的数据。
- 这段代码通过循环读取多个文件,将数据合并到一个列表中,再将整合后的数据写入新的 JSON 文件,实现了数据的高效汇总与管理。
案例 5:数据过滤与清洗
with open("raw_data.json", encoding="utf-8") as f:
data = json.load(f)
filtered_data = [item for item in data if item["status"] == "active"]
with open("filtered_data.json", "w", encoding="utf-8") as f:
json.dump(filtered_data, f, ensure_ascii=False, indent=2)
- 当数据量庞大且包含无效或错误信息时,数据过滤与清洗至关重要。
- 此代码从原始 JSON 数据中筛选出状态为 “active” 的条目,去除无效数据,生成更精准、可用的数据集,为后续分析和应用提供保障。
案例 6:实时数据更新
with open("data.json", "r+", encoding="utf-8") as f:
data = json.load(f)
data["count"] = data.get("count", 0) + 1
f.seek(0)
json.dump(data, f, ensure_ascii=False, indent=2)
f.truncate()
- 在一些需要实时记录数据变化的场景,如计数器、日志记录等,这段代码实现了对 JSON 文件数据的实时更新。
- 通过读取文件数据、修改数据、再写回文件的操作,确保数据的时效性和准确性。
血泪陷阱
1.编码问题
# 错误示范
json.dumps({"name": "小明"}) # → {"name": "\u5c0f\u660e"}
# 正确做法
json.dumps({"name": "小明"}, ensure_ascii=False)
- 默认情况下,json.dumps会将非 ASCII 字符转义为 Unicode 编码。
- 添加ensure_ascii=False参数,就可以让中文字符正常显示,避免乱码问题,确保数据在传输和展示过程中的准确性。
2.循环引用
data = {"a": 1}
data["b"] = data # 循环引用
# 错误示范
json.dumps(data) # ❌ ValueError
# 解决方案
from json import JSONEncoder
class MyEncoder(JSONEncoder):
def default(self, obj):
# 处理循环引用
return str(obj)
- 当数据结构中存在循环引1用时,json.dumps会抛出ValueError。
- 通过自定义JSONEncoder,我们可以对循环引用的对象进行特殊处理,如将其转换成字符串,从而避免程序崩溃。
3.日期时间处理
# 错误示范
json.dumps({"time": datetime.now()}) # ❌ TypeError
# 正确做法
json.dumps({"time": datetime.now().isoformat()})
- 由于 JSON 本身不支持datetime类型,直接对包含datetime对象的数据进行序列化会导致TypeError。
- 将datetime对象转换成 ISO 格式字符串,是一种简单有效的解决方案,确保日期时间数据能顺利进行 JSON 转换。
工具箱
json.dump和json.dumps函数的参数介绍
- 这两个函数的一些参数配置可使转换后的json数据更美观更容易阅读
默认的参数如下:
skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
default=None, sort_keys=False
①.sort_keys参数(排序)
- 如果传入sort_keys为True,转换为json时讲按照传入的字典进行排序。
python_dictinfo = { 'name': 'lili', 'age': 20}
json_data = json.dumps(python_dictinfo,sort_keys=True)
print(f'转换后的json数据: {json_data}')
#打印排序后的结果
转换后的json数据: {"age": 20, "name": "lili"}
②.indent参数(美化输出)
- indent传入的是非负整数,则JSON数组元素和对象成员将使用该缩进进行漂亮的打印
python_dictinfo = {"name":"lili","age":20.00,"address":["china","js","nj"],"man":True,"woman":False,"money":None}
json_data = json.dumps(python_dictinfo,indent=4)
print(f'转换后的json数据: {json_data}')
转换后的json数据:
{
"name": "lili",
"age": 20.0,
"address": [
"china",
"js",
"nj"
],
"man": true,
"woman": false,
"money": null
}
③.separators参数
- 表示“分隔符”,默认值为(‘,’,‘:’),如果指定为其他的元组,比如(‘a’,‘b’),意味着原来的逗号会被替换为a,原来的冒号会被替换为b,并去掉后面的空格。
python_dictinfo = python_dictinfo = { 'name': 'lili', 'age': 20}
json_data = json.dumps(python_dictinfo,separators=('a','b'))
print(f'转换后的json数据: {json_data}')
#打印结果
转换后的json数据: {"name"b"lili"a"age"b20}
④.skipkeys参数
- 默认值是False,如果“skipkeys”为True,则非python基本数据类型的“dict”键
(“str”、“int”、“float”、“bool”、“None”),将被跳过而不会引发“TypeError”。
#定义一个元组的键
python_dictinfo = {'name': 'lili', 'age': 20, ('china', 'js', 'nj'): None}
json_data = json.dumps(python_dictinfo)
print(f'转换后的json数据: {json_data}')
#执行后报错
TypeError: keys must be str, int, float, bool or None, not tuple
添加参数skipkeys=True
json_data = json.dumps(python_dictinfo,skipkeys=True)
print(f'转换后的json数据: {json_data}')
#打印结果 会忽略掉元组键值
转换后的json数据: {"name": "lili", "age": 20}
⑤.ensure_ascii参数(支持中文)
- 默认值True,输出ASCLL码,如果配置为False,可以输出中文。
python_dictinfo = {'name': '王磊', 'age': 20 }
json_data = json.dumps(python_dictinfo)
print(f'转换后的json数据: {json_data}')
#结果如下
转换后的json数据: {"name": "\u738b\u78ca", "age": 20}
- 配置为False后可打印中文
json_data = json.dumps(python_dictinfo,ensure_ascii=False)
print(f'转换后的json数据: {json_data}')
#结果如下
转换后的json数据: {"name": "王磊", "age":20}
⑥.check_circular参数
- 如果check_circular为false,则跳过对容器类型的循环引用检查,循环引用将导致溢出错误(或更糟的情况)。
⑦.allow_nan参数
- 默认为True,序列化超出范围的浮点值(nan、inf、-inf)转为json格式 (nan、Infinity、-Infinity)。如果为False,则执行时会报错。
python_dictinfo = {'name': 'lili', 'age': float('inf')}
json_data = json.dumps(python_dictinfo,allow_nan=False)
# allow_nan=False 则执行时会报错
ValueError: Out of range float values are not JSON compliant: inf

总结
- 最后希望你编程学习上不急不躁,按照计划有条不紊推进,把任何一件事做到极致,都是不容易的,加油,努力!相信自己!
文末福利
- 最后这里免费分享给大家一份Python全套学习资料,希望能帮到那些不满现状,想提升自己却又没有方向的朋友,也可以和我一起来学习交流呀。
包含编程资料、学习路线图、源代码、软件安装包等!【[点击这里]】领取!
- ① Python所有方向的学习路线图,清楚各个方向要学什么东西
- ② 100多节Python课程视频,涵盖必备基础、爬虫和数据分析
- ③ 100多个Python实战案例,学习不再是只会理论
- ④ 华为出品独家Python漫画教程,手机也能学习



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









