



因为看到都是目标检测批量标注的帖子,但是最近一直在做带关键点的数据集,所以记录使用X-AnyLabeling进行姿态检测数据集的批量标注。
参考教程:
视频:https://www.bilibili.com/video/BV12c46eUE4o/?spm_id_from=333.337.search-card.all.click&vd_source=7d778d43a7af5bca30ce6c124550edfd
文字教程:
http://bbs.laoleng.vip/thread-1238-1-1.html
可以看下视频教程。
一、项目下载及环境安装
参考了这个教程:
https://blog.youkuaiyun.com/qq_63512036/article/details/135514440
1.下载源码
【GitHub 源码地址】:GitHub - CVHub520/X-AnyLabeling
2.环境配置
新建anaconda环境:
conda create -n anylabeling python=3.10
anylabeling是环境名称,我的python版本是3.10.4,新建环境后,cd进入源码根目录:
cd /home/Pycharm/Projects/X-AnyLabeling-main
切换环境:
conda activate anylabeling
下载需要的环境:
pip install -r requirements.txt
如果遇到超时的,或者下载过于慢的,可以终止,使用清华源进行下载,例如:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple PyQtWebEngine==5.15.7
最终我的环境内容如下:
# Name Version Build Channel
_libgcc_mutex 0.1 main
annotated-types 0.7.0 <pip>
anyio 4.11.0 <pip>
attrs 25.4.0 <pip>
bzip2 1.0.8 h7b6447c_0
ca-certificates 2025.11.4 h06a4308_0
certifi 2025.11.12 <pip>
charset-normalizer 3.4.4 <pip>
click 8.3.1 <pip>
coloredlogs 15.0.1 <pip>
Cython 3.2.1 <pip>
distro 1.9.0 <pip>
exceptiongroup 1.3.0 <pip>
filelock 3.20.0 <pip>
flatbuffers 25.9.23 <pip>
fsspec 2025.10.0 <pip>
h11 0.16.0 <pip>
hf-xet 1.2.0 <pip>
httpcore 1.0.9 <pip>
httpx 0.28.1 <pip>
huggingface_hub 1.1.5 <pip>
humanfriendly 10.0 <pip>
idna 3.11 <pip>
importlib_metadata 8.7.0 <pip>
jiter 0.12.0 <pip>
json_repair 0.54.1 <pip>
jsonlines 4.0.0 <pip>
lapx 0.5.5 <pip>
ld_impl_linux-64 2.40 h12ee557_0
libffi 3.3 he6710b0_2
libgcc-ng 9.1.0 hdf63c60_0
libstdcxx-ng 9.1.0 hdf63c60_0
libuuid 1.0.3 h7f8727e_2
Markdown 3.10 <pip>
ml_dtypes 0.5.4 <pip>
mpmath 1.3.0 <pip>
natsort 8.1.0 <pip>
ncurses 6.3 h7f8727e_2
numpy 1.26.4 <pip>
onnx 1.19.1 <pip>
onnxruntime 1.23.2 <pip>
openai 2.8.1 <pip>
opencv-contrib-python-headless 4.11.0.86 <pip>
openssl 1.1.1w h7f8727e_0
packaging 25.0 <pip>
pillow 12.0.0 <pip>
pip 25.3 pyhc872135_0
protobuf 6.33.1 <pip>
psutil 7.1.3 <pip>
pyclipper 1.3.0.post6 <pip>
pydantic 2.12.4 <pip>
pydantic_core 2.41.5 <pip>
PyQt5 5.15.7 <pip>
PyQt5-Qt5 5.15.18 <pip>
PyQt5_sip 12.17.1 <pip>
PyQtWebEngine 5.15.7 <pip>
PyQtWebEngine-Qt5 5.15.18 <pip>
python 3.10.4 h12debd9_0
PyYAML 6.0.3 <pip>
qimage2ndarray 1.10.0 <pip>
readline 8.1.2 h7f8727e_1
requests 2.32.5 <pip>
scipy 1.15.3 <pip>
setuptools 80.9.0 <pip>
setuptools 80.9.0 py310h06a4308_0
shapely 2.1.2 <pip>
shellingham 1.5.4 <pip>
six 1.17.0 <pip>
sniffio 1.3.1 <pip>
sqlite 3.38.5 hc218d9a_0
sympy 1.14.0 <pip>
termcolor 1.1.0 <pip>
tk 8.6.12 h1ccaba5_0
tokenizers 0.22.1 <pip>
tqdm 4.67.1 <pip>
typer-slim 0.20.0 <pip>
typing-inspection 0.4.2 <pip>
typing_extensions 4.15.0 <pip>
tzdata 2025b h04d1e81_0
urllib3 2.5.0 <pip>
wheel 0.45.1 py310h06a4308_0
wheel 0.45.1 <pip>
xz 5.2.5 h7f8727e_1
zipp 3.23.0 <pip>
zlib 1.2.12 h7f8727e_2
在项目控制台输入:
python anylabeling/app.py

弹出标注窗口。
二、模型准备
我使用的自定义的模型进行批量标注,所以先训练一个小模型,这里我手动标注了40张左右图像,使用初始权重yolov11n-pose进行训练,得到best.pt,这里需要将pt转换成onnx:
yolo export model=/home/YOLOV11/ultralytics/train3/weights/best.pt format=onnx
这里的model需要替换你自己的pt路径。
生成的onnx会自动保存在上述路径同级目录,在此文件夹下,新建一个yaml文件,名字随便:

内容如下:
type: yolo11_pose
name: yolo11s_pose-r20240930
provider: Ultralytics
display_name: test_pose
model_path: best.onnx
conf_threshold: 0.5
iou_threshold: 0.6
kpt_threshold: 0.25
has_visible: true
classes:
bbox1: # 目标框类别1
- kpt1 # 目标框1的关键点名称
- kpt2 # 目标框1的关键点名称
bbox2: # 目标框类别2
- kpt1 # 目标框2的关键点名称
前三行不动,display_name随便,model_path就是上面图片中的onnx路径(我是同级目录所以不写绝对路径),conf_threshold: 0.5、iou_threshold: 0.6、kpt_threshold: 0.25、has_visible: true是预测时候的参数,后续可以调整。
下面这个对应当时训练模型的目标框和关键点,需要自行修改:
classes:
bbox1: # 目标框类别1
- kpt1 # 目标框1的关键点名称
- kpt2 # 目标框1的关键点名称
bbox2: # 目标框类别2
- kpt1 # 目标框2的关键点名称
其他yaml文件可以在这里找到:https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/model_zoo.md
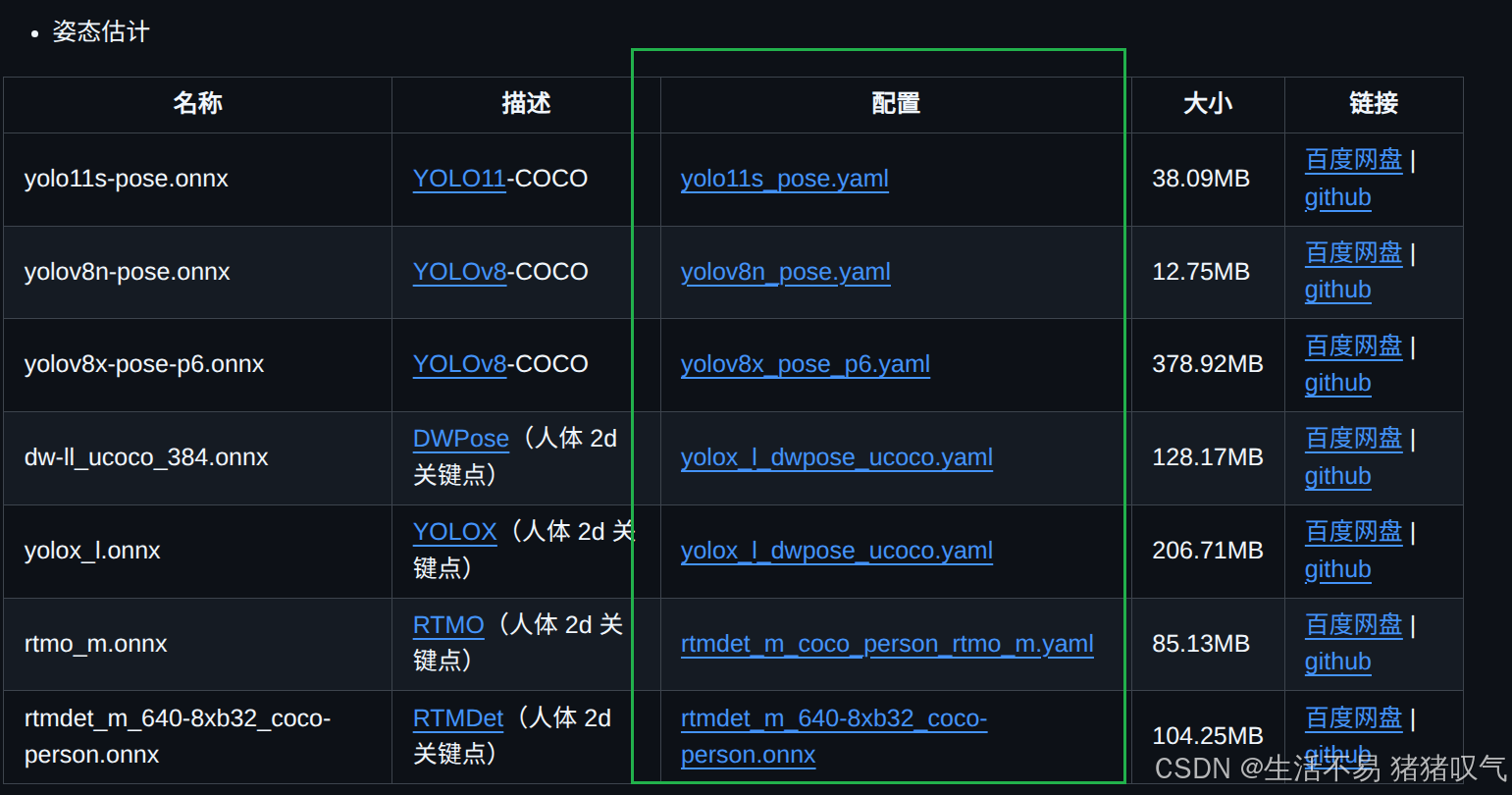
三、批量标注
1.语言部分可以切换中文

2.打开图像
3.配置定义好的yaml

选择这个AI图标,然后在顶部点击绿色框的部分:
选择Custom–Load Custom Model,然后选择刚才写好的yaml,点确定 就好了。
顶部的运行按钮是单张运行检测,想要批量检测可以在刚才的AI小按钮上面 点击播放按钮:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









