# encoding: utf-8
"""
@version: 0.1
@author:
@site:
@software: PyCharm
@file: dpubanYizhouKoubei.py
@time: 2020-06-01 8:47
"""
from lxml import etree
import requests
urls = ['https://movie.douban.com/']
ua = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18362'
session = requests.Session()
with session:
for url in urls:
response = session.get(url, headers={'User-Agent': ua})
content = response.text.encode('utf-8')
# print(content)
# xpath //div[@class='billboard']//tr//td/a/text()
html = etree.HTML(content)
# titles = html.xpath("//div[@class='billboard-bd']//tr//td/a/text()")
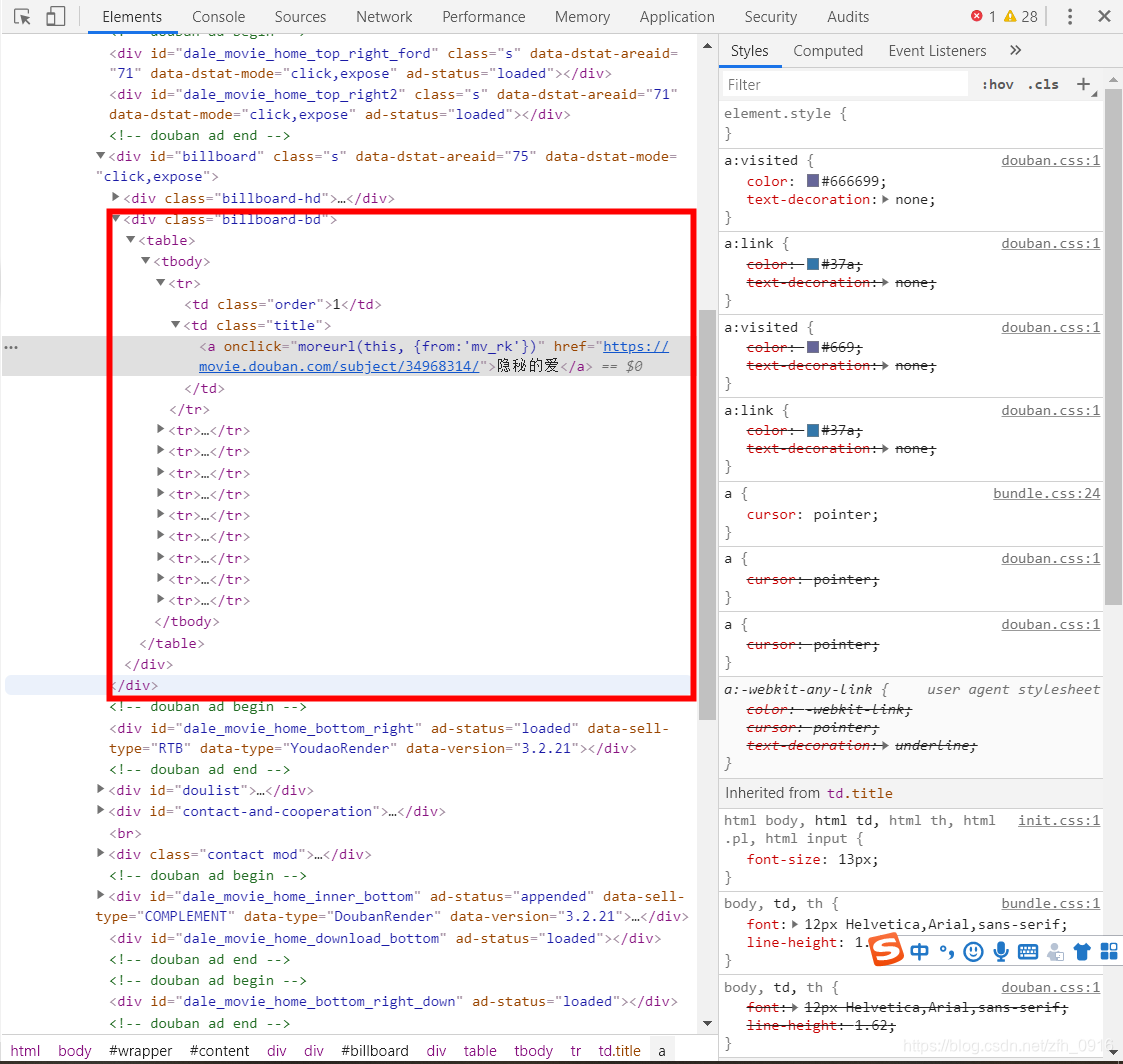
titles = html.xpath("//div[@class='billboard-bd']//tr")
for title in titles:
txt = title.xpath('.//text()')
print(''.join(map(lambda x: x.strip(), txt)))
print('-'*30)
爬取结果:
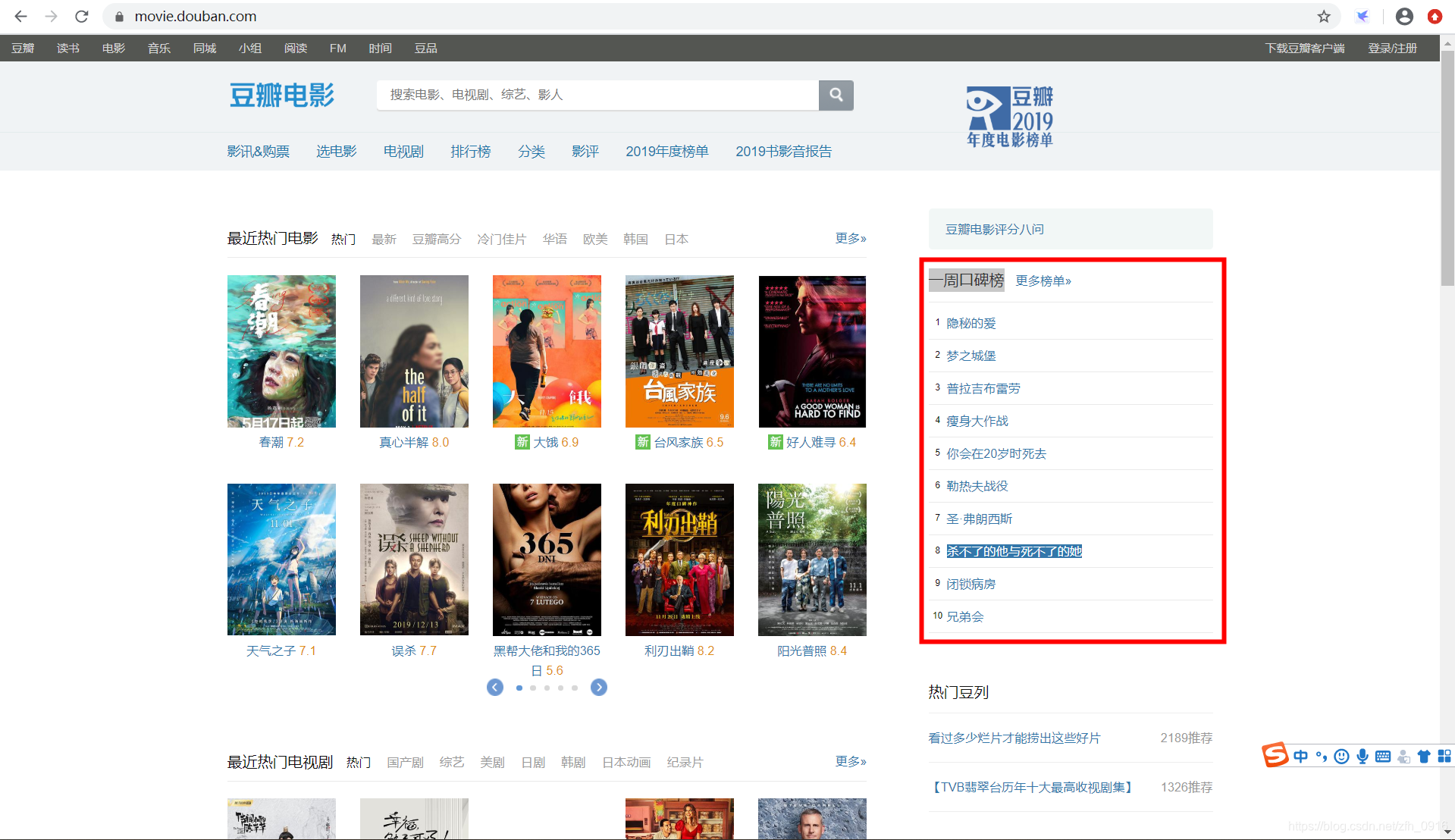
1隐秘的爱
------------------------------
2梦之城堡
------------------------------
3普拉吉布雷劳
------------------------------
4瘦身大作战
------------------------------
5你会在20岁时死去
------------------------------
6勒热夫战役
------------------------------
7圣·弗朗西斯
------------------------------
8杀不了的他与死不了的她
------------------------------
9闭锁病房
------------------------------
10兄弟会
------------------------------
需爬取内容截图:
路径分析:








 本文介绍了一种使用Python和lxml库抓取豆瓣电影口碑排行榜数据的方法,通过分析网页结构并应用XPath表达式,成功获取了榜单上的电影名称。
本文介绍了一种使用Python和lxml库抓取豆瓣电影口碑排行榜数据的方法,通过分析网页结构并应用XPath表达式,成功获取了榜单上的电影名称。

















 940
940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









