







 本文介绍Kafka主题管理命令,包括创建、查看、修改、删除主题等操作,并讲解了Kafka的基本与高级API使用方法,如消息发布、订阅、自定义序列化与反序列化、消息拦截器、生产者与消费者的配置选项等。
本文介绍Kafka主题管理命令,包括创建、查看、修改、删除主题等操作,并讲解了Kafka的基本与高级API使用方法,如消息发布、订阅、自定义序列化与反序列化、消息拦截器、生产者与消费者的配置选项等。
文章目录
Topic管理(shell)
新增Topic
./kafka-topics.sh --bootstrap-server ip/hostname:9092,ip/hostname:9092,ip/hostname:9092 --create --topic topicname --partitions 4 --replication-factor 3
查看Topic
./kafka-topics.sh --bootstrap-server ip/hostname:9092,ip/hostname:9092,ip/hostname:9092 --list
查看Toptic详细信息
./kafka-topics.sh --bootstrap-server ip/hostname:9092,ip/hostname:9092,ip/hostname:9092 --describe --topic topicname
以第一行为例,topic_test_01的0号分区 的 leader为brokerid=2的服务实例,0号分区的follower为brokerid为2,1,4的服务实例,0号分区的备份在brokerid为2,1,4的服务器上

修改topic
./kafka-topics.sh --bootstrap-server ip/hostname:9092,ip/hostname:9092,ip/hostname:9092 --alert --topic topicname --修改项 修改值
注意
- 其中分区数不能从大往小改
删除topic
./kafka-topics.sh --bootstrap-server ip/hostname:9092,ip/hostname:9092,ip/hostname:9092 --delete --topic topicname
订阅topic
./kafka-console-consumer.sh --bootstrap-server ip/hostname:9092,ip/hostname:9092,ip/hostname:9092 --topic topicname --group groupname --property print.key=true --property print.value=true --property key.separator=:
- print.key:是否打印key
- print.value:是否打印值
- key.separator:key和value的分隔符
发布消息到topic
./kafka-console-producer.sh --broker-list ip/hostname:9092,ip/hostname:9092,ip/hostname:9092 --topic topicname
查看消费者组列表及组详细信息
./kafka-consumer-groups.sh --bootstrap-server ip/hostname:9092,ip/hostname:9092,ip/hostname:9092 --list
./kafka-consumer-groups.sh --bootstrap-server ip/hostname:9092,ip/hostname:9092,ip/hostname:9092 --describe --group groupname

基础API使用
topic增删改查
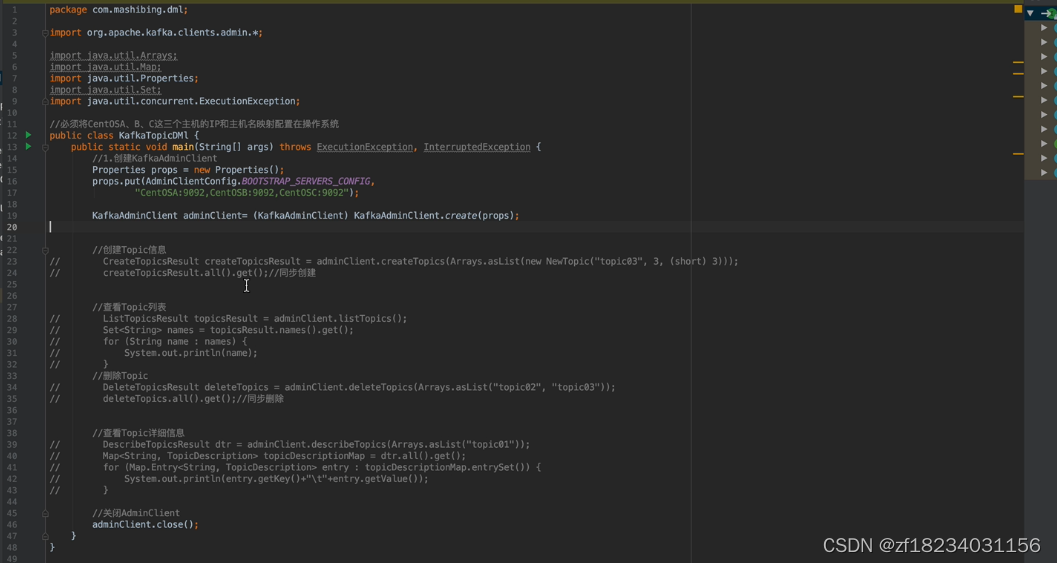
生产者-发送消息
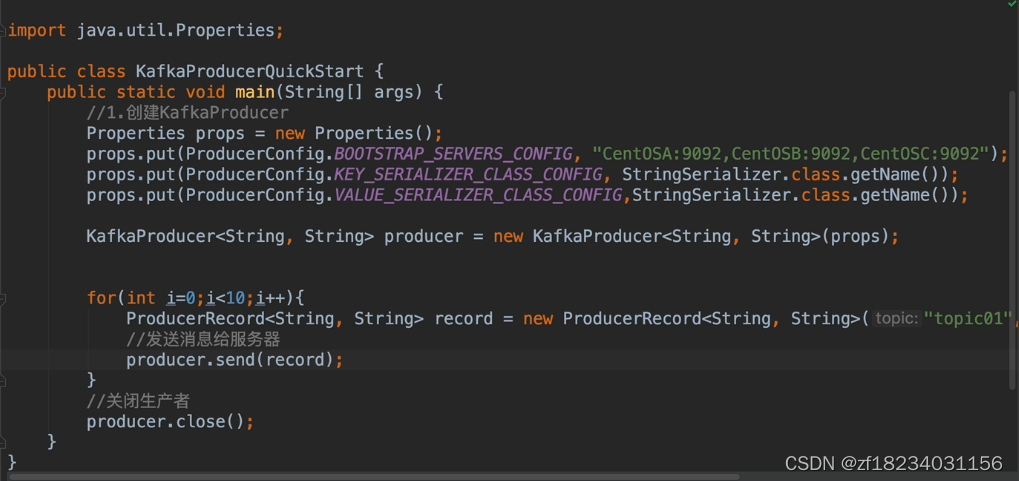
注释
- KEY_SERIALIZER_CLASS_CONFIG:key序列化配置
- VALUE_SERIALIZER_CLASS_CONFIG:值序列化配置
消费者-消费者组(subscribe)
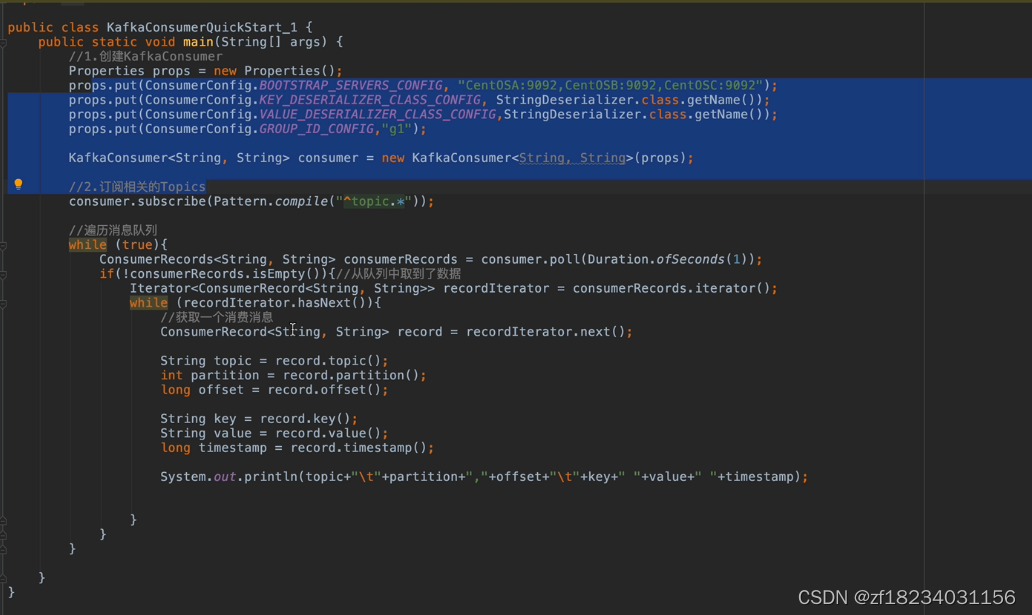
注释
- KEY_DESERIALIZER_CLASS_CONFIG:key反序列化配置
- VALUE_DESERIALIZER_CLASS_CONFIG:值反序列化配置
- GROUP_ID_CONFIG:组名,配置消费者属于那个消费者组
- subscribe方法会自动设置组中消费者与分区的绑定关系
消费者(assign)
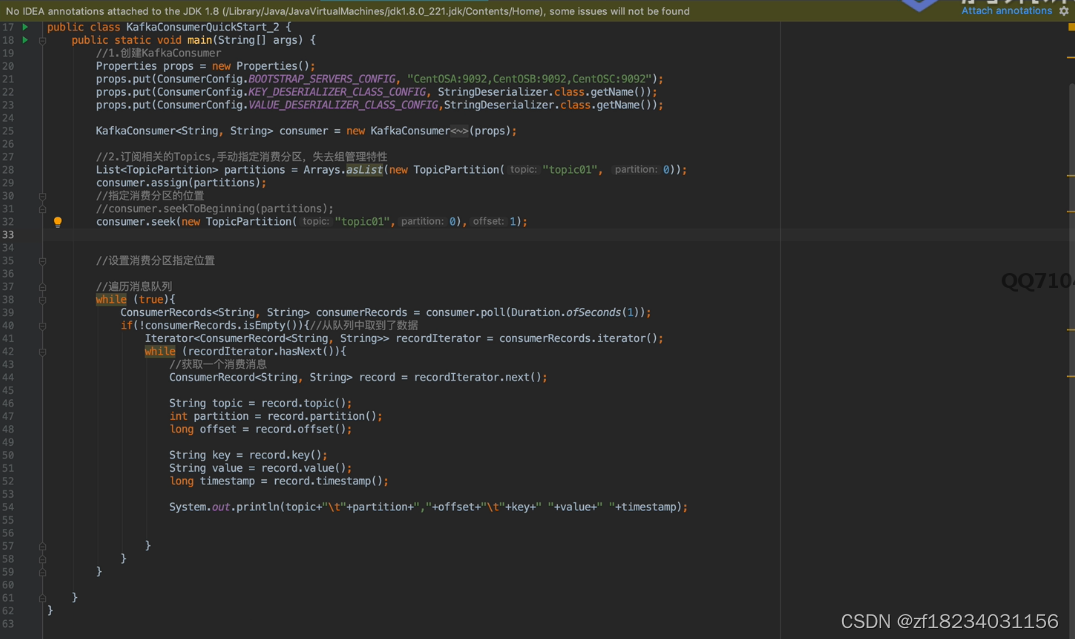
注释
- assign直接绑定某个topic的某个分区,不存在消费者组的概念。实现多个消费者同时消费一个分区
- seek指定某个topic的某个分区的offset
- seekToBeginning从头开始消费某个topic的某个分区
生产者自定义消息发送到某个分区
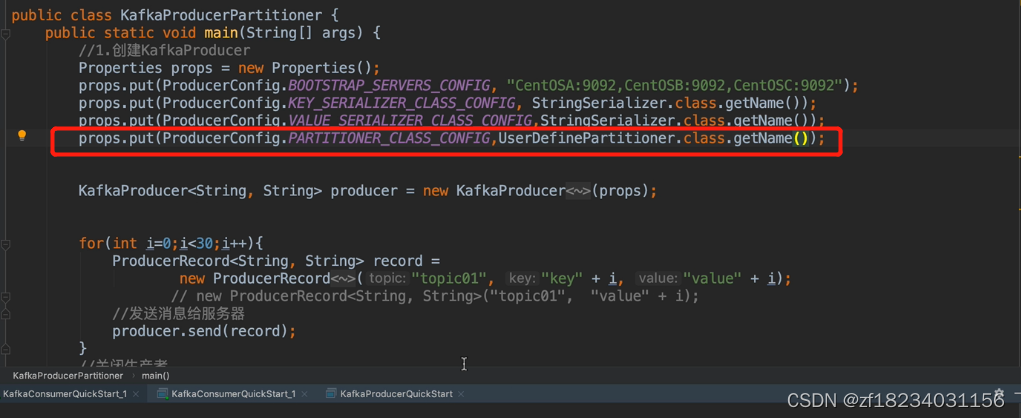
注释
- 默认情况下,如果消息不存在key,在采用轮询的方式均匀的发送到分区中
- 如果key存在,则对key进行hash并对分区数取模后发送到对应分区
- 如果想自定义消息到分区的规则,需要实现Partitioner接口并配置PARTITIONER_CLASS_CONFIG,值为实现类.class.getName()
自定义序列化
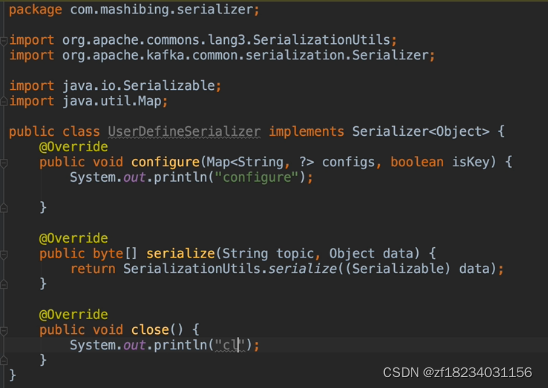
实现自定义序列化需要执行以下步骤
- 实现org.apache.kafka.common.serialization.Serializer接口的方法
- 在serialize方法中实现对对象的序列化(org.apache.commons.langs包有现成的序列化方法可用)
- VALUE_SERIALIZER_CLASS_CONFIG:值设置为 实现类.class.getName()
- 对象需要实现java.io.Serializable
自定义反序列化
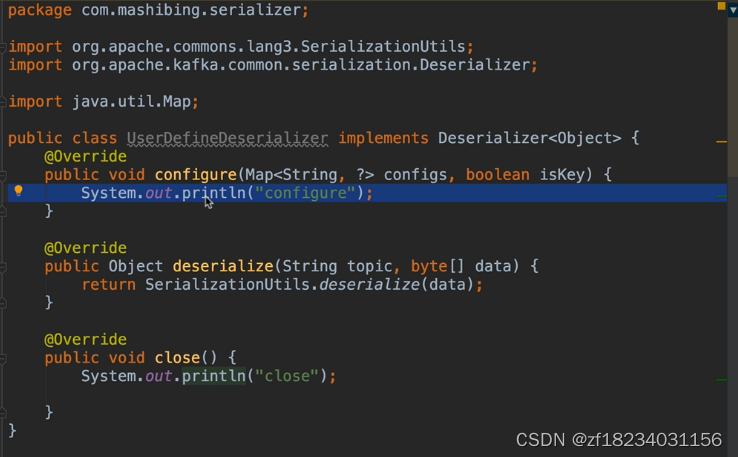
实现自定义反序列化需要执行以下步骤
- 实现org.apache.kafka.common.serialization.Deserializer接口
- 在deserialize方法中实现对对象的反序列化(org.apache.commons.langs包有现成的序列化方法可用)
- VALUE_DESERIALIZER_CLASS_CONFIG:值设置为 实现类.class.getName()
- 对象需要实现java.io.Serializable
消息发送拦截器
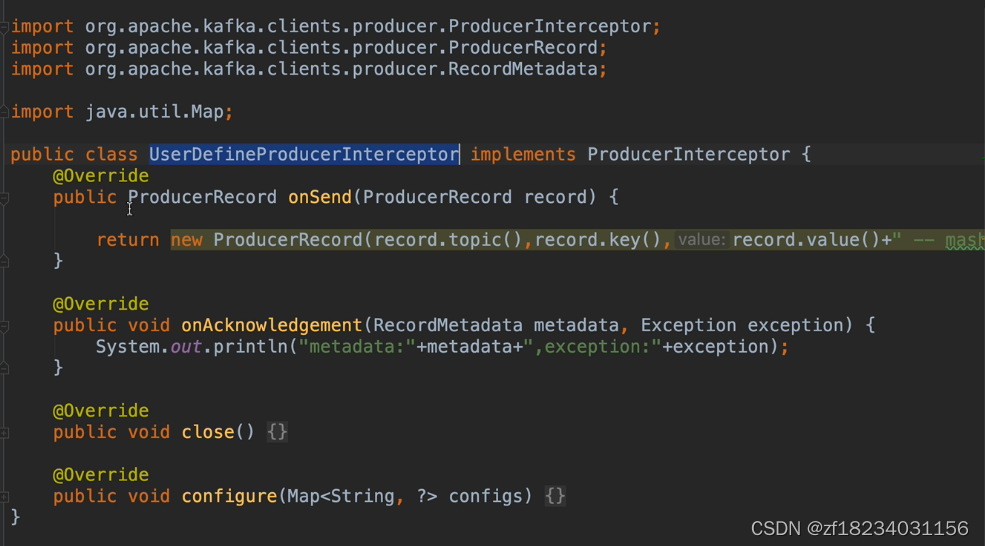
如何在发消息前对消息进行拦截?
- 实现ProducerInterceptor接口
- onSend:可以对消息进行处理
- onAcknowledgement:可以知道消息是否发送成功,消息的原信息以及异常信息
- 配置INTERCEPTOR_CLASS_CONFIG,值为实现类.class.getName()
高级API使用
消费者offset自动控制
AUTO_OFFSET_RESET_CONFIG:当系统没有消费者的offset时的执行策略
- earliest:从头开始处理
- latest:(默认)从最新的开始处理
- none:直接报错
消费者offset自动提交/手动提交
kafka消费者在消费数据的时候默认会定时的提交消费的偏移量,这样就可以保证所有消息至少能被消费一次,可以通过以下两个配置控制是否开启自动提交offset,以及定时提交的周期。
- enable.auto.commit = true 默认 (ENABLE_AUTO_COMMIT_CONFIG)
- auto.commit.interval.ms = 5000 默认(AUTO_COMMIT_INTERVAL_MS_CONFIG)
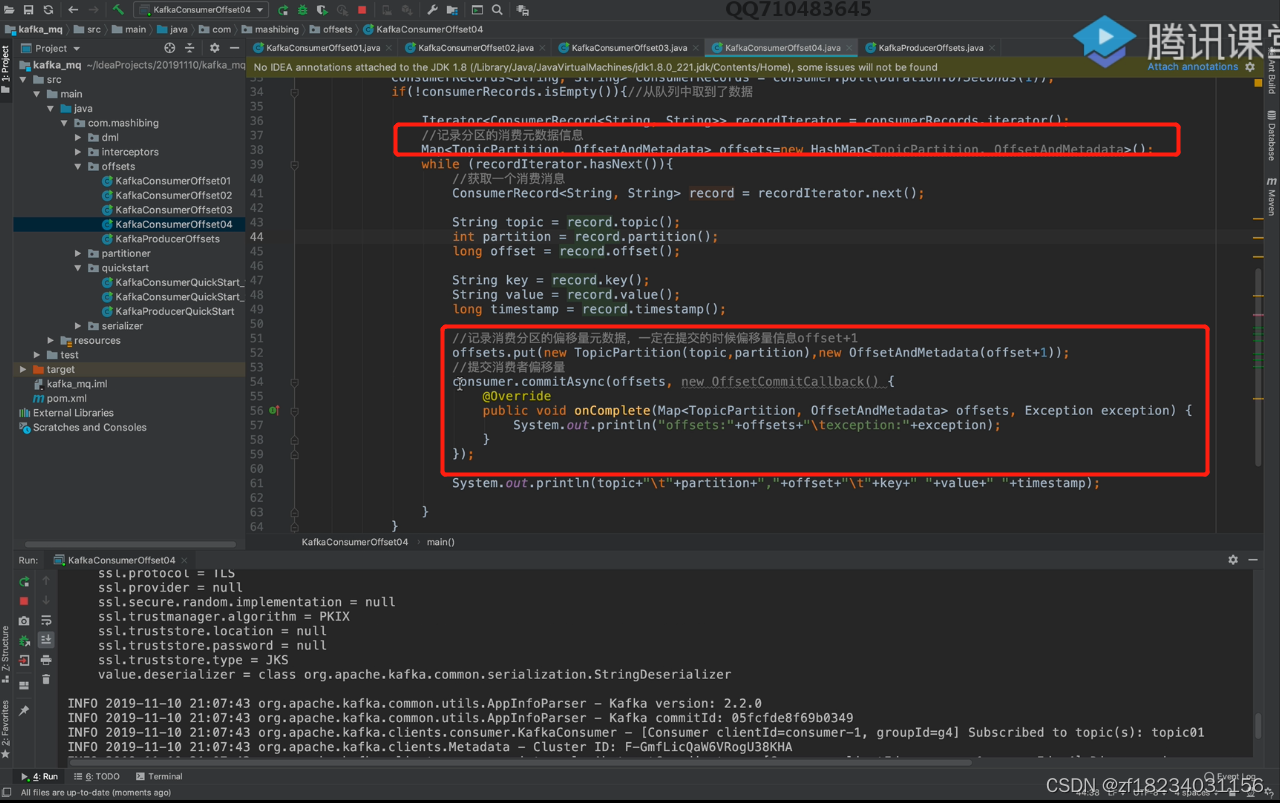
enable.auto.commit = false即可以关闭自动提交,但是需要手动提交offset。下图为手动控制
注意:
- 手动提交偏移量时,需要提交本次消费的offset+1,因为提交的偏移量为下次消费者读取的位置
生产者ACKS&Retries
kafka生产者在发送完消息后,要求broker在规定时间内进行ack应答,如果没有在规定的时间内应答,kafka生产者会尝试n次重新发送消息
- acks
- acks=1:Leader会将消息写到其本地日志中,但不等待所有Follower完全确认后做出响应,这种情况下,如果Leader在做出响应后Follower复制消息之前失败,则消息将丢失。
- acks=0:生产者根本不会等待服务器的任何确认,该消息将立即添加到套接字缓冲区中并视为已发送。这种情况下不能保证服务器已收到消息,存在消息丢失的问题。
- acks=all/-1:Leader将等待所有Follower同步副本后做出响应,这样保证了只要有一个Follower处于活跃状态,记录就不会丢失。
- retries
- request.timeout.ms = 3000(默认):等待响应的时长,超过该时长未收到响应将进行重试
- retries = 2117483647(默认):重试次数
问题:
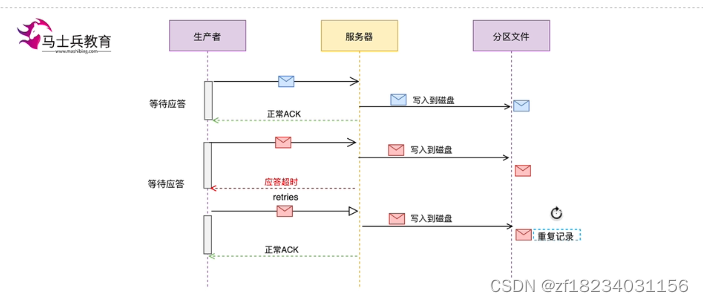
- 重复写
为了保证消息不丢失,所以我们需要设置acks=all,并且开启重试,但是开启重试后可能会引起重复发送一条消息的问题,比如生产者发送一条消息后,broker已经保存成功,但是响应给发送者的ack因为某些原因(网络不稳定)发送者一直未收到,超过了等待时长后,生产者又将该条消息发送了一遍,这样就会导致一条消息重复写入分区。
生产者幂等性(解决写重复)
当开启重试机制时,会导致写重复的问题,幂等性(exactly once)便解决了该问题。kafka在0.11.0.0版本增加了对幂等的支持,而kafka的幂等性是针对生产者的特性。当生产者开启幂等性,可以保证发送的消息不会丢失且不会重复。
- 如何保证幂等性
实现幂等的关键点在于服务端可以区分请求是否重复,过滤掉重复的写入请求,要区分是否重复有两点比较重要:
- 唯一标识:
- 唯一标识的处理状态:光有唯一标识还不够,还需要记录下唯一标识的处理状态,这样当收到新的请求时,用新请求中的唯一标识和处理记录进行比较,如果已经处理过,说明是重复记录。
- kafka实现幂等的原理
在初始化阶段,kafka会给生产者生成一个唯一的ID(Producer ID/PID),PID和序列号与消息捆绑在一起发送broker,由于序列号从0开始且单调递增,因此仅当消息的序列号比该Topic 中最后提交的消息的序列号正好大1时,broker才会接受该消息,否则broker认为是生产者重新发送的消息不写入分区中。
- 如何开启幂等性
enable.idempotence=true(默认为false,ENABLE_IDEMPOTENCE_CONFIG)
注意事项
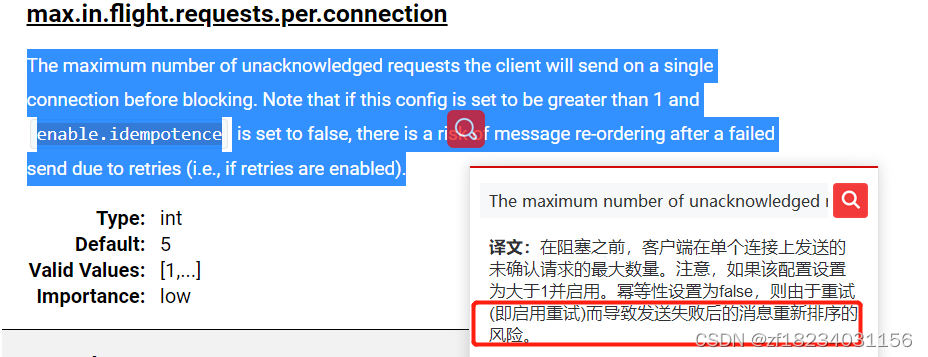
- 在使用幂等性的时候,必须要求acks=all,retries=true
- max.in.flight.requests.per.connection=1:(MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION)
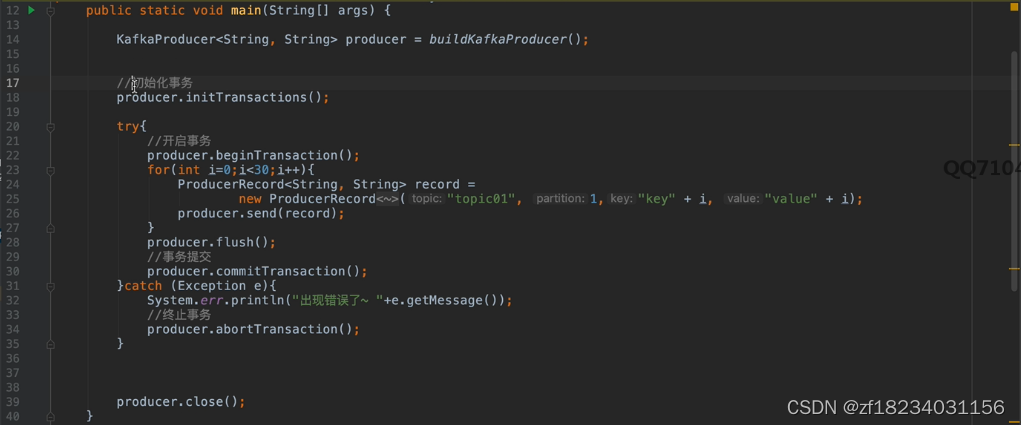
事务
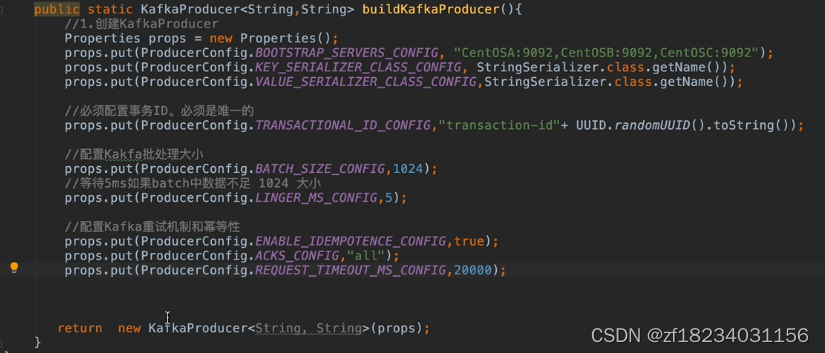
kafka发送消息时是一批一批发送的,幂等性只能保证一条记录发送成功,但是如果要保证对条记录的原子性(同时成功/失败)就需要开启kafka的事务操作。kafka在0.11.0.0也引入了事务的概念,
BATCH_SIZE_CONFIG:设置发送消息批处理大小,达到个数才进行发送 LINGER_MS_CONFIG:逗留时长,超过这个时长即使未达到批处理大小也发送消息
- kafka事务简述
kafka的事务不同于数据库的事务,它是通过生产者发送一批数据到broker,假如一批数据发送成功一批数据发送失败,broker会将为成功的那批数据标记特殊的状态,而kafka的事务主要由消费者设置的隔离级别控制,默认的消费者消费消息的级别是read_uncommited,就能读取到被标记特殊状态的那批数据,所以在开启生产者事务之后需要设置消费者的事务隔离级别为read_commited,这样消费者将读不到被标记特殊状态的那批数据。
- 如何开启事务
设置生产者: 指定transactional.id,值必须唯一。例如(TRANSACTIONAL_ID_CONFIG="XXXXX"+UUID)。 一旦开启事务,默认生产者就开启了幂等性 设置消费者 指定ConsumerConfig.ISOLATION_LEVEL_CONFIG,"read_committed"
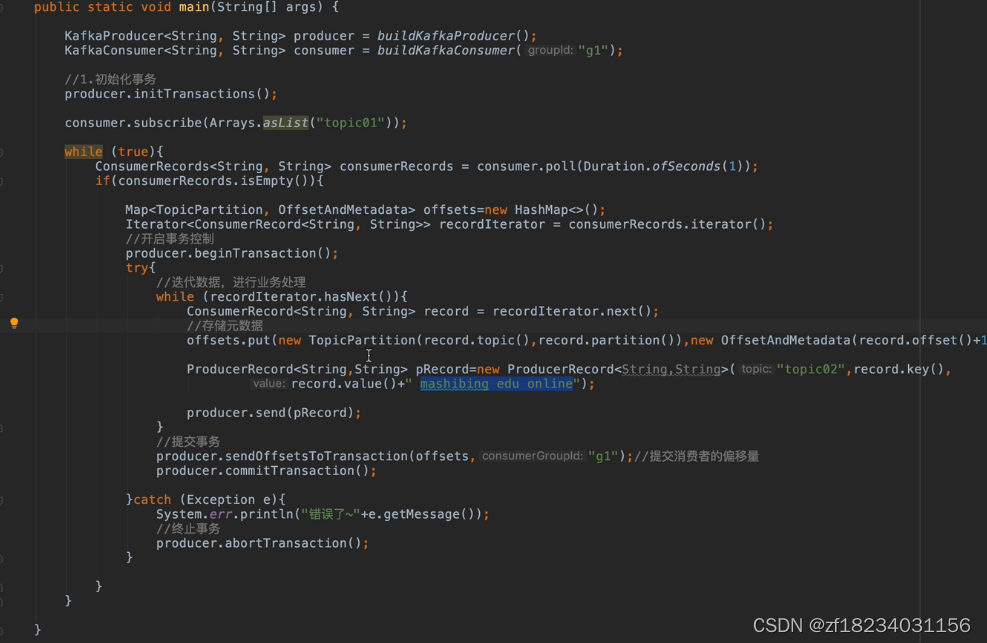
- kafka的事务又分为两种情况
- Producer Only:即事务只涉及生产者发送消息失败
- Producer& Consumer:即事务既涉及消费者同时涉及生产者
注意:- 必须关闭自动offset,改为手动

















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









