




 该博客探讨了如何使用Python的heapq模块和collections.Counter来有效地找到列表中出现频率最高的K个元素。首先,通过Counter计算每个元素的频率,然后利用堆数据结构将元素及其频率转换为堆。通过heappop操作,可以按频率降序获取Top K的元素。此外,还提到了使用排序实现相同功能的方法,但堆在处理大数据集时更具优势。
该博客探讨了如何使用Python的heapq模块和collections.Counter来有效地找到列表中出现频率最高的K个元素。首先,通过Counter计算每个元素的频率,然后利用堆数据结构将元素及其频率转换为堆。通过heappop操作,可以按频率降序获取Top K的元素。此外,还提到了使用排序实现相同功能的方法,但堆在处理大数据集时更具优势。
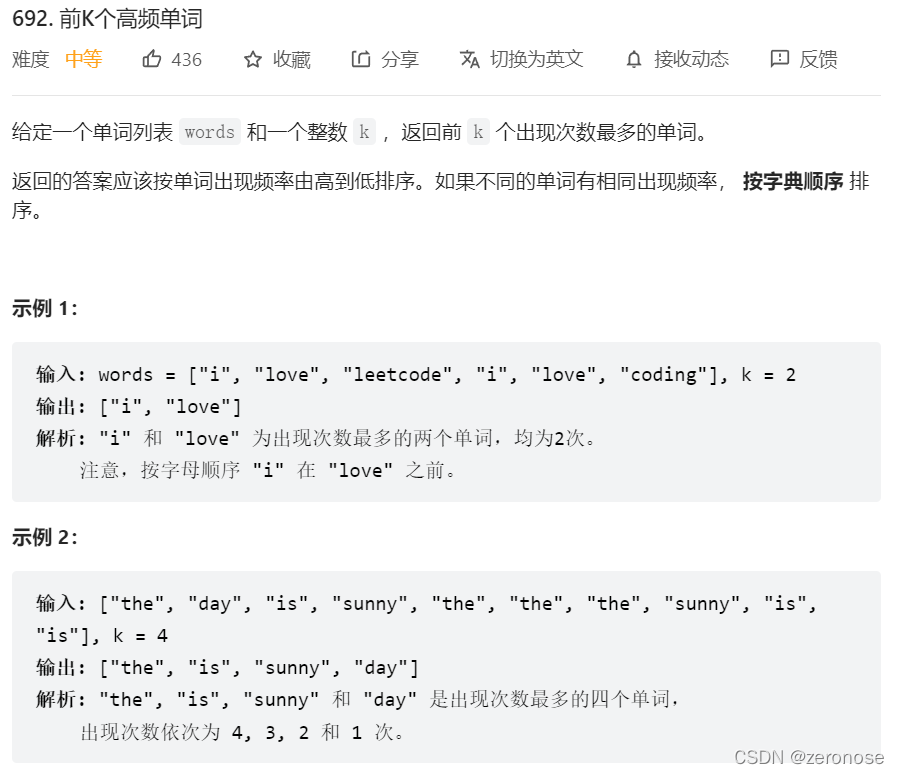
通常在问题中看到 前 K 大,前 KK小 或者 第 K 个, K 个最 等等类似字样,一般情况下我们都可以用堆来做。
class Solution(object):
def topKFrequent(self, words, k):
"""
:type words: List[str]
:type k: int
:rtype: List[str]
"""
# collections.Counter(words)为python自带的计数器
count = collections.Counter(words)
heap = [(-freq, word) for word, freq in count.items()]
heapq.heapify(heap)
return [heapq.heappop(heap)[1] for _ in range(k)]
# 普通排序
d = collections.Counter(words)
pairs = [(value, key) for key, value in d.items()]
res = sorted(pairs, key = lambda a:(-a[0], a[1]))
return [res[i][1] for i in range(k)]
Todo:这是API实现的,要自己写堆,自己写比较函数

















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









