




- Introduction
一种高效无监督的生成对抗网络,称为EnlightenGAN,可以在没有低/正常光图像对的情况下进行训练 - Difficulties
1)同步捕获损坏和地面实况图像相同的视觉场景是非常困难甚至不切实际的(例如,光线和普通光照图像对在同一时间)
2)从干净的图像中合成损坏的图像有时会有帮助,但这种合成的结果通常不够逼真,当训练后的模型应用于真实的低光图像时,会产生各种伪影
3)特别对于低光增强问题,在低光图像中可能没有唯一的或定义良好的高光真实图像。例如,任何从黎明到黄昏拍摄的照片都可以被看作是在同一场景拍摄的午夜照片的高亮版本。
考虑到上述问题,我们的首要目标是增强低光照片与空间变化的光照条件和过度/不足的曝光伪影,而配对的训练数据是不可用的。 - Contribution
1)EnlightenGAN是第一个成功地将非配对训练引入低光图像增强的作品。这种训练策略消除了对成对训练数据的依赖,使我们能够使用来自不同领域的更大种类的图像进行训练。它还避免了以前的工作[15,5,16]隐式依赖的任何特定数据生成协议或成像设备的过度拟合,从而显著改进了现实世界的泛化。
2)EnlightenGAN通过引入下列两个操作,获得了显著的性能。(i)一个处理输入图像中空间变化光照条件的全局-局部鉴别器结构;(ii)自正则化思想,通过自特征保留损失和自正则注意机制来实现。自正则化对于我们的模型的成功是至关重要的,因为在不配对的情况下,没有强有力的外部监督形式可用。
3)通过综合实验,将EnlightenGAN与几种先进的方法进行了比较。测量结果包括视觉质量、无参考图像质量评估和人的主观调查。所有的结果都一致认可EnlightenGAN的优越性。此外,与现有的配对训练增强方法相比,EnlightenGAN被证明特别容易和灵活地用于增强不同领域的真实低光图像。 - Architecture
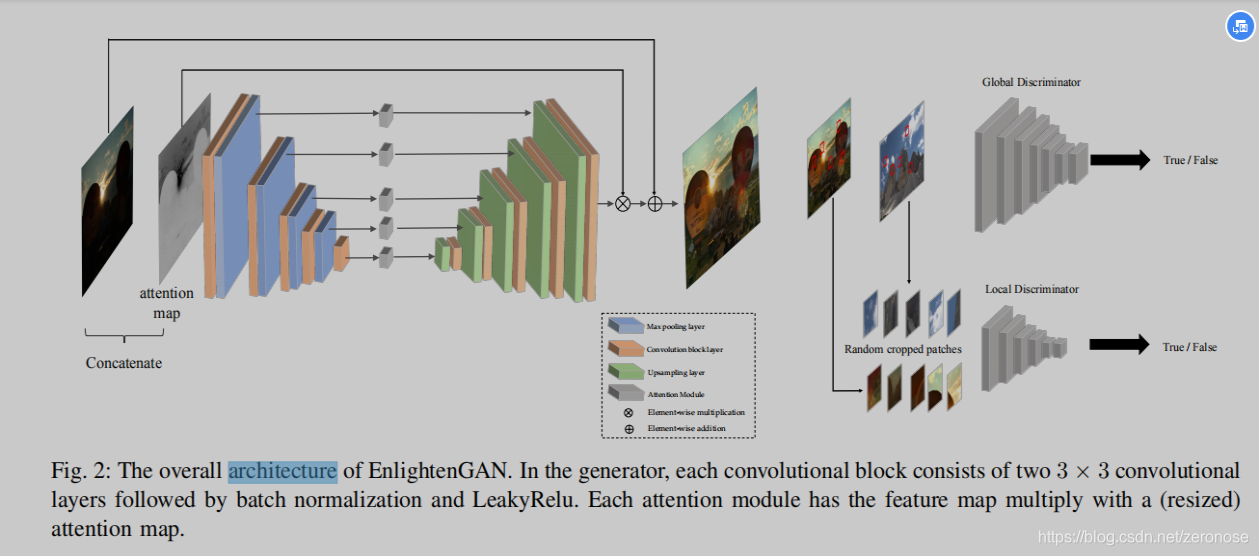
- Method
A. Global-Local Discriminators
为了自适应地增强局部区域,在提高全局光照的同时,我们提出了一种新的全局-局部鉴别器结构,该结构使用PatchGAN进行真假鉴别。除了图像级全局鉴别器,我们还添加了一个局部鉴别器,通过从输出和真实的正常光照图像中随机裁剪局部小块,并学习区分它们是真实的(与真实图像)还是虚假的(与增强的输出)。这种全局-局部结构保证了增强图像的所有局部区域看起来都像真实的自然光,这对于避免局部过曝或低曝至关重要,我们的实验稍后将揭示这一点。
此外,对于全局判别器,我们利用最近提出的相对判别器结构[35]估计真实数据比虚假数据更真实的概率,并指导生成器合成比真实图像更真实的伪图像。相对论判别器的标准函数是: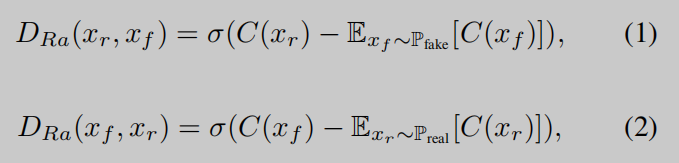
其中C表示判别器网络,xrx_rxr 和xfx_fxf分别表示真实数据和虚假数据的分布,σ\sigmaσ表示sigmoid激活函数。我们稍微修改了相对论判别器,用最小二乘GAN(LSGAN)损失代替了sigmoid函数最后全局判别器D和生成器G的损失函数为: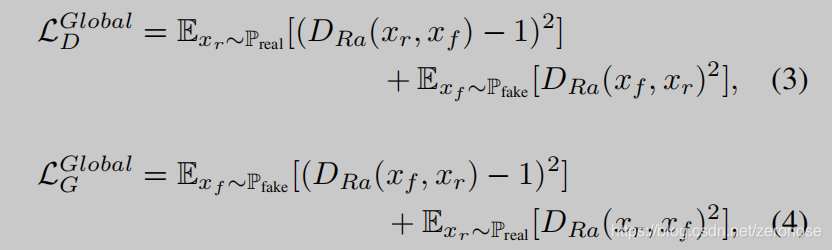
对于局部判别器,我们每次从输出图像和真实图像中随机裁剪5个patch。这里我们采用原LSGAN作为对抗性损失,如下:
EnlightenGAN: Deep Light Enhancement without Paired Supervision--论文阅读笔记
最新推荐文章于 2024-01-09 21:56:59 发布
 本文介绍了一种无监督的生成对抗网络EnlightenGAN,它能在没有低光-正常光配对的情况下提升图像质量,通过全局-局部鉴别器、自特征保留损失和注意力机制克服训练难题。实验结果表明,EnlightenGAN在视觉质量、主观评价和实际应用中超越现有方法,且适用于不同领域的低光图像增强。
本文介绍了一种无监督的生成对抗网络EnlightenGAN,它能在没有低光-正常光配对的情况下提升图像质量,通过全局-局部鉴别器、自特征保留损失和注意力机制克服训练难题。实验结果表明,EnlightenGAN在视觉质量、主观评价和实际应用中超越现有方法,且适用于不同领域的低光图像增强。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









