




LLaMA-Factory是一个微调框架。
1环境配置
1.1安装CUDA
这个就比较繁琐了,可以参考其他教程,验证是否安装成功可以用以下代码
import torch
torch.cuda.is_available()
torch.cuda.current_device()出现以下输出就说明GPU环境准备好了。

有一个小坑, 如果ubuntu执行nvcc -V时系统可能无法识别nvcc的命令。这时可以看一下 /usr/local/cuda/bin下面是否存在nvcc,如果存在就在.bashrc的最后加上
export PATH="/usr/local/cuda/bin:$PATH"nano ~/.bashrc
source ~/.bashrc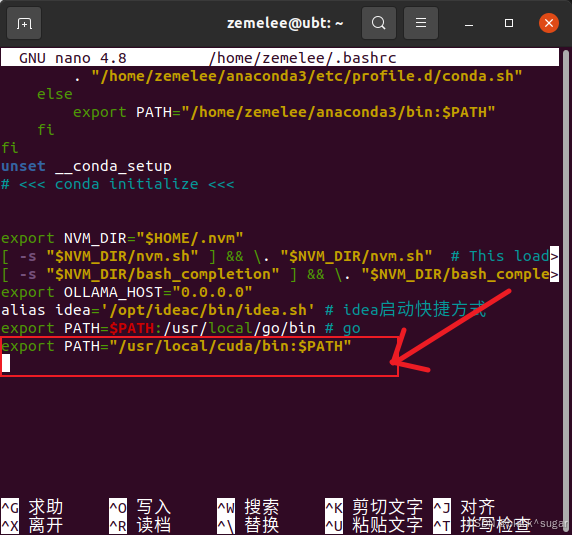
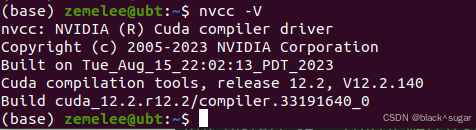
再次执行就能正常运行了
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









