




 本文介绍了单纯形迭代搜索在线性规划中的应用,从初始可行解的人工变量引入,到迭代步骤的确定,以及终止准则的探讨,详细展示了如何通过下降算法逐步逼近最优解的过程。
本文介绍了单纯形迭代搜索在线性规划中的应用,从初始可行解的人工变量引入,到迭代步骤的确定,以及终止准则的探讨,详细展示了如何通过下降算法逐步逼近最优解的过程。
2.3.4 向最佳顶点出发 ! ! ! --单纯形迭代搜索
把基可行解都枚举出来是比较笨的——那样子不够"数学".
我们更希望的是 , , , 能向登山一样 , , , 设计出一条爬山路线 , , , 不断逼近"山顶"——而具有这种性质的数学算法应该是迭代的: 一步步搜索顶点 , , , 每搜索到的一个顶点 x n \boldsymbol{x}_n xn 都要比上一次搜索到的顶点 x n − 1 \boldsymbol{x}_{n-1} xn−1 要"好" , , , 由于我们求解的是最小值 , , , 这样的算法统称为下降算法
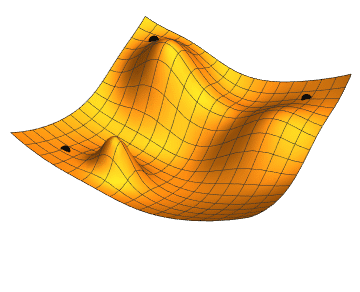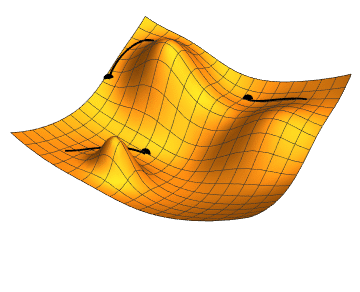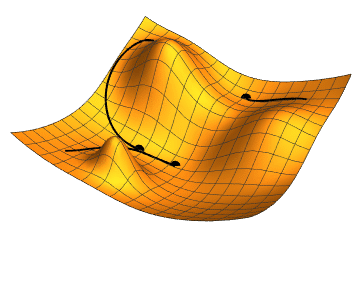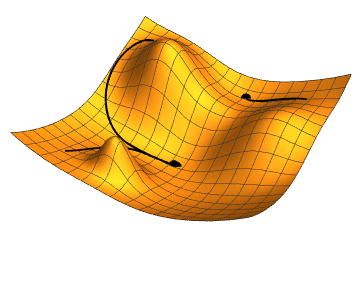
下降算法由以下几步构成:
-
确定初始的迭代点 x 0 \boldsymbol{x}_0 x0.
-
确定迭代步骤 , , , 即 x n − 1 \boldsymbol{x}_{n-1} xn−1 与 x n \boldsymbol{x}_{n} xn 之间的递推关系 x n = F ( x n − 1 ) \boldsymbol{x}_n=F(\boldsymbol{x}_{n-1}) xn=F(xn−1) 且保证"下降" f ( x n ) − f ( x n − 1 ) ⩽ 0 f(\boldsymbol{x}_n)-f(\boldsymbol{x}_{n-1})\leqslant 0 f(xn)−f(xn−1)⩽0.
-
确定如何迭代到什么时候能找到最优解 , , , 即终止准则.
1.3.4 节中我们已经知道了线性规划问题 1 , 2 {1},{2} 1,2 的最优解必定在顶点 (基可行解) 处取得 , , , 故我们的搜索迭代范围仅限于顶点 (基可行解) 之间 , , , 依照下降算法的步骤 , , , 我们需要先找到一个顶点 (基可行解) 作为初始解 x 0 \boldsymbol{x}_0 x0 再从 x 0 \boldsymbol{x}_0 x0 出发寻找函数值 f f f 不大于 f ( x 0 ) f(\boldsymbol{x}_0) f(x0) 的顶点 (基可行解) x 1 , \boldsymbol{x}_1, x1, 接着重复此步骤直到找到无法再下降的顶点 (基可行解) x N \boldsymbol{x}_{N} xN.
第一部分:初始可行解(人工变量)
在最开始的时候 , , , 我们需要找到一个顶点 (基可行解) 作为算法的"启动资金"——初始解. 由 1.3.4 我们知道需要计算约束方程 A x = b A\boldsymbol{x}=\boldsymbol{b} Ax=b 中的一个基可行解 , , , 这要求我们找到 A A A 中一个基 B , B, B, 枚举基是有一定难度的 , , , 特别是当决策变量个数 n n n 以及约束矩阵 A A A 的秩 m m m 都比较大的时候 (大规模计算的情形) , , , 我们更希望有一种简单的方式去找到一个基 B , B, B, 因为线性规划问题 2 {2} 2 是经过引入松弛变量松弛化不等式约束的 , , , 如 1 , {1}, 1, 这相当于在矩阵 A A A 中增广了如 ( 1 , 0 , ⋯ , 0 ) (1,0,\cdots,0) (1,0,⋯,0) 的列向量 , , , 假设 A A A 的前 k k k 行都是不等式约束 , , , 那么加入松弛变量后 A A A 增广为
{ a 11 x 1 + a 12 x 2 + ⋯ + a 1 n x n ⩽ b 1 a 21 x 1 + a 22 x 2 + ⋯ + a 2 n x n ⩽ b 2 ⋮ a k 1 x 1 + a k 2 x 2 + ⋯ + a k n x n ⩽ b k a k + 1 , 1 x 1 + a k + 1 , 2 x 2 + ⋯ + a k + 1 , n x n = b k + 1 ⋮ a m 1 x 1 + a m 2 x 2 + ⋯ + a m n x n = b m ⟶ { a 11 x 1 + a 12 x 2 + ⋯ + a 1 n x n + s 1 = b 1 a 21 x 1 + a 22 x 2 + ⋯ + a 2 n x n + s 2 = b 2 ⋮ a k 1 x 1 + a k 2 x 2 + ⋯ + a k n x n + s k = b k a k + 1 , 1 x 1 + a k + 1 , 2 x 2 + ⋯ + a k + 1 , n x n = b k + 1 ⋮ a m 1 x 1 + a m 2 x 2 + ⋯ + a m n x n = b m ⇕ ⇕ [ a 11 a 12 ⋯ a 1 n a 21 a 22 ⋯ a 2 n ⋮ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n ] ⟶ [ a 11 a 12 ⋯ a 1 n 1 0 ⋯ 0 ⋯ 0 a 21 a 22 ⋯ a 2 n 0 1 ⋯ 0 ⋯ 0 ⋮ ⋮ ⋱ ⋮ ⋮ ⋮ ⋱ ⋮ ⋱ ⋮ a k 1 a k 2 ⋯ a k n 0 0 ⋯ 1 ⋯ 0 a k + 1 , 1 a k + 1 , 2 ⋯ a k + 1 , n 0 0 ⋯ 0 ⋯ 0 ⋮ ⋮ ⋱ ⋮ ⋮ ⋮ ⋱ ⋮ ⋱ ⋮ a m 1 a m 2 ⋯ a m n 0 0 ⋯ 0 ⋯ 0 ] \begin{matrix} \begin{cases} a_{11}x_1+a_{12}x_2+\cdots+a_{1n}x_n\leqslant b_1\\ a_{21}x_1+a_{22}x_2+\cdots+a_{2n}x_n\leqslant b_2\\ \vdots\\ a_{k1}x_1+a_{k2}x_2+\cdots+a_{kn}x_n\leqslant b_k\\ a_{k+1,1}x_1+a_{k+1,2}x_2+\cdots+a_{k+1,n}x_n= b_{k+1}\\ \vdots\\ a_{m1}x_1+a_{m2}x_2+\cdots+a_{mn}x_n= b_m\\ \end{cases} &\longrightarrow& \begin{cases} a_{11}x_1+a_{12}x_2+\cdots+a_{1n}x_n+s_1=b_1\\ a_{21}x_1+a_{22}x_2+\cdots+a_{2n}x_n+s_2=b_2\\ \vdots\\ a_{k1}x_1+a_{k2}x_2+\cdots+a_{kn}x_n+s_k=b_k\\ a_{k+1,1}x_1+a_{k+1,2}x_2+\cdots+a_{k+1,n}x_n= b_{k+1}\\ \vdots\\ a_{m1}x_1+a_{m2}x_2+\cdots+a_{mn}x_n= b_m\\ \end{cases}\\ \Updownarrow&&\Updownarrow\\ \begin{bmatrix} a_{11}&a_{12}&\cdots&a_{1n}\\ a_{21}&a_{22}&\cdots&a_{2n}\\ \vdots&\vdots&\ddots&\vdots\\ a_{m1}&a_{m2}&\cdots&a_{mn}\\ \end{bmatrix}&\longrightarrow&\begin{bmatrix} a_{11}&a_{12}&\cdots&a_{1n}&1&0&\cdots&0&\cdots&0\\ a_{21}&a_{22}&\cdots&a_{2n}&0&1&\cdots&0&\cdots&0\\ \vdots&\vdots&\ddots&\vdots&\vdots&\vdots&\ddots&\vdots&\ddots&\vdots\\ a_{k1}&a_{k2}&\cdots&a_{kn}&0&0&\cdots&1&\cdots&0\\ a_{k+1,1}&a_{k+1,2}&\cdots&a_{k+1,n}&0&0&\cdots&0&\cdots&0\\ \vdots&\vdots&\ddots&\vdots&\vdots&\vdots&\ddots&\vdots&\ddots&\vdots\\ a_{m1}&a_{m2}&\cdots&a_{mn}&0&0&\cdots&0&\cdots&0\\ \end{bmatrix} \end{matrix} ⎩ ⎨ ⎧a11x1+a12x2+⋯+a1nxn⩽b1a21x1+a22x2+⋯+a2nxn⩽b2⋮ak1x1+ak2x2+⋯+aknxn⩽bkak+1,1x1+ak+1,2x2+⋯+ak+1,nxn=bk+1⋮am1x1+am2x2+⋯+amnxn=bm⇕⎣ ⎡a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn⎦ ⎤⟶⟶⎩ ⎨ ⎧a11x1+a12x2+⋯+a1nxn+s1=b1a21x1+a22x2+⋯+a2nxn+s2=b2⋮ak1x1+ak2x2+⋯+aknxn+sk=bkak+1,1x1+ak+1,2x2+⋯+ak+1,nxn=bk+1⋮am1x1+am2x2+⋯+amnxn=bm⇕⎣ ⎡a11a21⋮ak1ak+1,1⋮am1a12a22⋮ak2ak+1,2⋮am2⋯⋯⋱⋯⋯⋱⋯a1na2n⋮aknak+1,n⋮amn10⋮00⋮001⋮00⋮0⋯⋯⋱⋯⋯⋱⋯00⋮10⋮0⋯⋯⋱⋯⋯⋱⋯00⋮00⋮0⎦ ⎤
当 m m m 行约束全是不等式约束即加入了 m m m 个松弛变量时 , A ,A ,A 的后 m m m 列自然构成了一个 m m m 阶的单位阵 I m , I_m, Im, 必定可逆 , , , 这不就是我们所想要的最简单的基吗 ? ? ?

命题 1.1.5 当线性规划问题 2 {2} 2 中只含有不等式约束时 , , , 标准化后的约束矩阵 A A A 后 m m m 列 I m I_m Im 是 A A A 的基.
当松弛变量个数小于
m
m
m 时
,
,
, 我们可以耍一耍小学生解题的"有借有还"伎俩
,
,
, 先借几个松弛变量凑到
m
m
m 个
,
,
, 最后求解的时候再还回去
,
,
,
min
c
1
x
1
+
c
2
x
2
+
⋯
+
c
n
x
n
min
c
1
x
1
+
c
2
x
2
+
⋯
+
c
n
x
n
+
M
(
s
k
+
1
+
s
k
+
2
+
⋯
+
s
m
)
{
a
11
x
1
+
a
12
x
2
+
⋯
+
a
1
n
x
n
⩽
b
1
a
21
x
1
+
a
22
x
2
+
⋯
+
a
2
n
x
n
⩽
b
2
⋮
a
k
1
x
1
+
a
k
2
x
2
+
⋯
+
a
k
n
x
n
⩽
b
k
a
k
+
1
,
1
x
1
+
a
k
+
1
,
2
x
2
+
⋯
+
a
k
+
1
,
n
x
n
=
b
k
+
1
⋮
a
m
1
x
1
+
a
m
2
x
2
+
⋯
+
a
m
n
x
n
=
b
m
⟶
{
a
11
x
1
+
a
12
x
2
+
⋯
+
a
1
n
x
n
+
s
1
=
b
1
a
21
x
1
+
a
22
x
2
+
⋯
+
a
2
n
x
n
+
s
2
=
b
2
⋮
a
k
1
x
1
+
a
k
2
x
2
+
⋯
+
a
k
n
x
n
+
s
k
=
b
k
a
k
+
1
,
1
x
1
+
a
k
+
1
,
2
x
2
+
⋯
+
a
k
+
1
,
n
x
n
+
s
k
+
1
=
b
k
+
1
⋮
a
m
1
x
1
+
a
m
2
x
2
+
⋯
+
a
m
n
x
n
+
s
m
=
b
m
⇕
⇕
[
a
11
a
12
⋯
a
1
n
a
21
a
22
⋯
a
2
n
⋮
⋮
⋱
⋮
a
m
1
a
m
2
⋯
a
m
n
]
⟶
[
a
11
a
12
⋯
a
1
n
1
0
⋯
0
0
⋯
0
a
21
a
22
⋯
a
2
n
0
1
⋯
0
0
⋯
0
⋮
⋮
⋱
⋮
⋮
⋮
⋱
⋮
⋮
⋱
⋮
a
k
1
a
k
2
⋯
a
k
n
0
0
⋯
1
0
⋯
0
a
k
+
1
,
1
a
k
+
1
,
2
⋯
a
k
+
1
,
n
0
0
⋯
0
1
⋯
0
⋮
⋮
⋱
⋮
⋮
⋮
⋱
⋮
⋮
⋱
⋮
a
m
1
a
m
2
⋯
a
m
n
0
0
⋯
0
0
⋯
1
]
\begin{matrix} \min c_1x_1+c_2x_2+\cdots+c_nx_n&&\min c_1x_1+c_2x_2+\cdots+c_nx_n+M(s_{k+1}+s_{k+2}+\cdots+s_{m})\\ \begin{cases} a_{11}x_1+a_{12}x_2+\cdots+a_{1n}x_n\leqslant b_1\\ a_{21}x_1+a_{22}x_2+\cdots+a_{2n}x_n\leqslant b_2\\ \vdots\\ a_{k1}x_1+a_{k2}x_2+\cdots+a_{kn}x_n\leqslant b_k\\ a_{k+1,1}x_1+a_{k+1,2}x_2+\cdots+a_{k+1,n}x_n= b_{k+1}\\ \vdots\\ a_{m1}x_1+a_{m2}x_2+\cdots+a_{mn}x_n= b_m\\ \end{cases} &\longrightarrow& \begin{cases} a_{11}x_1+a_{12}x_2+\cdots+a_{1n}x_n+s_1=b_1\\ a_{21}x_1+a_{22}x_2+\cdots+a_{2n}x_n+s_2=b_2\\ \vdots\\ a_{k1}x_1+a_{k2}x_2+\cdots+a_{kn}x_n+s_k=b_k\\ a_{k+1,1}x_1+a_{k+1,2}x_2+\cdots+a_{k+1,n}x_n+s_{k+1}= b_{k+1}\\ \vdots\\ a_{m1}x_1+a_{m2}x_2+\cdots+a_{mn}x_n+s_{m}= b_m\\ \end{cases} \\ \Updownarrow&&\Updownarrow\\ \begin{bmatrix} a_{11}&a_{12}&\cdots&a_{1n}\\ a_{21}&a_{22}&\cdots&a_{2n}\\ \vdots&\vdots&\ddots&\vdots\\ a_{m1}&a_{m2}&\cdots&a_{mn}\\ \end{bmatrix}&\longrightarrow&\begin{bmatrix} a_{11}&a_{12}&\cdots&a_{1n}&1&0&\cdots&0&0&\cdots&0\\ a_{21}&a_{22}&\cdots&a_{2n}&0&1&\cdots&0&0&\cdots&0\\ \vdots&\vdots&\ddots&\vdots&\vdots&\vdots&\ddots&\vdots&\vdots&\ddots&\vdots\\ a_{k1}&a_{k2}&\cdots&a_{kn}&0&0&\cdots&1&0&\cdots&0\\ a_{k+1,1}&a_{k+1,2}&\cdots&a_{k+1,n}&0&0&\cdots&0&1&\cdots&0\\ \vdots&\vdots&\ddots&\vdots&\vdots&\vdots&\ddots&\vdots&\vdots&\ddots&\vdots\\ a_{m1}&a_{m2}&\cdots&a_{mn}&0&0&\cdots&0&0&\cdots&1\\ \end{bmatrix} \end{matrix}
minc1x1+c2x2+⋯+cnxn⎩
⎨
⎧a11x1+a12x2+⋯+a1nxn⩽b1a21x1+a22x2+⋯+a2nxn⩽b2⋮ak1x1+ak2x2+⋯+aknxn⩽bkak+1,1x1+ak+1,2x2+⋯+ak+1,nxn=bk+1⋮am1x1+am2x2+⋯+amnxn=bm⇕⎣
⎡a11a21⋮am1a12a22⋮am2⋯⋯⋱⋯a1na2n⋮amn⎦
⎤⟶⟶minc1x1+c2x2+⋯+cnxn+M(sk+1+sk+2+⋯+sm)⎩
⎨
⎧a11x1+a12x2+⋯+a1nxn+s1=b1a21x1+a22x2+⋯+a2nxn+s2=b2⋮ak1x1+ak2x2+⋯+aknxn+sk=bkak+1,1x1+ak+1,2x2+⋯+ak+1,nxn+sk+1=bk+1⋮am1x1+am2x2+⋯+amnxn+sm=bm⇕⎣
⎡a11a21⋮ak1ak+1,1⋮am1a12a22⋮ak2ak+1,2⋮am2⋯⋯⋱⋯⋯⋱⋯a1na2n⋮aknak+1,n⋮amn10⋮00⋮001⋮00⋮0⋯⋯⋱⋯⋯⋱⋯00⋮10⋮000⋮01⋮0⋯⋯⋱⋯⋯⋱⋯00⋮00⋮1⎦
⎤
增加的松弛变量
s
i
,
i
=
k
+
1
,
⋯
,
m
s_i,i=k+1,\cdots,m
si,i=k+1,⋯,m 我们称为人工变量
,
,
, 其中
M
M
M 是充分大的数 (
M
>
>
c
i
,
i
=
1
,
2
,
⋯
,
n
M>>c_i,i=1,2,\cdots,n
M>>ci,i=1,2,⋯,n)
,
,
, 用于保证增加人工变量后与原问题的等效性 (这是因为借的人工变量
s
i
,
i
=
k
+
1
,
⋯
,
m
s_i,i=k+1,\cdots,m
si,i=k+1,⋯,m 必须为
0
0
0 即"还"回去
,
,
, 不会改变原问题的最优解).
综上 , , , 单纯形法寻找初始解步骤是
第二部分:迭代步骤
由 1.3.4 节的命题 1.1.3 我们可知线性规划问题 KaTeX parse error: Undefined control sequence: \eqref at position 1: \̲e̲q̲r̲e̲f̲{eq 1},\eqref{e… 中可行域中的解作为顶点 (基可行解) 的必要条件是至少有
n
−
m
n-m
n−m 个分量为
0
,
0,
0, 换言之
,
,
, 基可行解都是由
m
m
m 个坐标分量就能决定的
,
,
, 那么从原来的基可行解
x
n
\boldsymbol{x}_n
xn 出发
,
,
, 我们就可以通过替换坐标的方式
,
,
, 不改变非
0
0
0 分量数
m
,
m,
m, 找到新的基可行解
x
n
+
1
j
\boldsymbol{x}_{n+1}^j
xn+1j ! 先斩后奏
,
,
, 我们给出基可行解的迭代方式如下: 不妨设 $\boldsymbol{x}n= (x{1},x_{2},\cdots,x_{m},0,\cdots,0) $ 是第
n
n
n 步迭代得到的基可行解
,
,
, 若用第
j
j
j 个坐标分量 (
j
>
m
j>m
j>m) 替换
1
∼
m
1\sim m
1∼m 中某一个坐标分量
,
,
, 则第
n
+
1
n+1
n+1 步的基可行解为
x
n
+
1
j
=
(
x
1
−
θ
a
1
j
,
x
2
−
θ
a
2
j
,
⋯
,
x
m
−
θ
a
m
j
,
0
,
⋯
,
θ
j
,
⋯
,
0
)
,
\boldsymbol{x}_{n+1}^j= (x_{1}-\theta a_{1j},x_{2}-\theta a_{2j},\cdots,x_{m}-\theta a_{mj},0,\cdots,\mathop{\theta}\limits^{j},\cdots,0) ,
xn+1j=(x1−θa1j,x2−θa2j,⋯,xm−θamj,0,⋯,θj,⋯,0),
其中
,
,
,
θ
=
min
{
x
i
a
i
j
∣
a
i
j
>
0
}
,
\theta=\min\left\{\left.\dfrac{x_{i}}{a_{ij}}\right|a_{ij}>0\right\},
θ=min{aijxi∣
∣aij>0},
而设最小的
x
i
a
i
j
\frac{x_{i}}{a_{ij}}
aijxi 对应的坐标分量是
l
,
l,
l, 那么
x
n
+
1
j
\boldsymbol{x}_{n+1}^j
xn+1j 的第
l
l
l 个分量
x
l
−
θ
a
l
j
=
0
,
x_{l}-\theta a_{lj}=0,
xl−θalj=0, 这便实现了第
j
j
j 个分量到第
l
l
l 个分量的替换. 而
θ
\theta
θ 取最小值的构造保证了
x
i
−
θ
a
i
j
⩾
0
,
x_{i}-\theta a_{ij}\geqslant 0,
xi−θaij⩾0, 此外
,
a
i
j
⩽
0
,a_{ij}\leqslant 0
,aij⩽0 的分量会使得
x
i
−
θ
a
i
j
⩾
x
i
⩾
0
,
x_i-\theta a_{ij}\geqslant x_i\geqslant 0,
xi−θaij⩾xi⩾0, 即替换后所有分量非负
,
,
, 保证了
x
n
+
1
j
\boldsymbol{x}_{n+1}^j
xn+1j 是基可行解.
而用来替换的坐标分量 j j j 需要满足
c j − ∑ i = 1 m c i a i j < 0 , c_j-\sum\limits_{i=1}^mc_ia_{ij}<0, cj−i=1∑mciaij<0,
因为 x n \boldsymbol{x}_n xn 与 x n + 1 j \boldsymbol{x}_{n+1}^j xn+1j 的目标函数值需满足单调递减性
KaTeX parse error: No such environment: at position 7: \begin{̲}̲ &f (\boldsymbo…
而基于贪心的想法
,
,
, 我们希望函数值能下降的越快越好即
f
(
x
n
+
1
j
)
−
f
(
x
n
)
f (\boldsymbol{x}_{n+1}^j) -f (\boldsymbol{x}_n)
f(xn+1j)−f(xn) 越小越好
,
,
, 从而我们每一步都选取如下的分量
j
,
j,
j,
j
0
=
a
r
g
m
i
n
{
f
(
x
n
+
1
j
)
−
f
(
x
n
)
=
c
j
−
∑
i
=
1
m
c
i
a
i
j
∣
j
=
m
+
1
,
⋯
,
n
}
.
j_0=\mathrm{argmin}\left\{\left.f (\boldsymbol{x}_{n+1}^j) -f (\boldsymbol{x}_n) =c_j-\sum\limits_{i=1}^mc_ia_{ij}\right| j=m+1,\cdots,n\right\}.
j0=argmin{f(xn+1j)−f(xn)=cj−i=1∑mciaij∣
∣j=m+1,⋯,n}.
所以
,
,
, 单纯形法的迭代步骤是
x
n
=
(
x
1
,
x
2
,
⋯
,
x
m
,
0
,
⋯
,
0
)
→
x
n
+
1
=
x
n
+
1
j
0
=
(
x
1
−
θ
a
1
j
0
,
x
2
−
θ
a
2
j
0
,
⋯
,
⋯
,
0
l
,
⋯
,
x
m
−
θ
a
m
j
0
,
0
,
⋯
,
θ
j
0
,
⋯
,
0
)
,
\boldsymbol{x}_n=(x_1,x_2,\cdots,x_m,0,\cdots,0)\to \boldsymbol{x}_{n+1}=\boldsymbol{x}_{n+1}^{j_0}=(x_{1}-\theta a_{1j_0},x_{2}-\theta a_{2j_0},\cdots,\cdots,\mathop{0}\limits^{l},\cdots,x_{m}-\theta a_{mj_0},0,\cdots,\mathop{\theta}\limits^{j_0},\cdots,0),
xn=(x1,x2,⋯,xm,0,⋯,0)→xn+1=xn+1j0=(x1−θa1j0,x2−θa2j0,⋯,⋯,0l,⋯,xm−θamj0,0,⋯,θj0,⋯,0),
θ
=
min
{
x
i
a
i
j
0
∣
a
i
j
0
>
0
}
=
x
l
a
l
j
0
,
j
0
=
a
r
g
m
i
n
{
f
(
x
n
+
1
j
)
−
f
(
x
n
)
=
c
j
−
∑
i
=
1
m
c
i
a
i
j
∣
j
=
m
+
1
,
⋯
,
n
}
.
\theta=\min\left\{\left.\dfrac{x_{i}}{a_{ij_0}}\right|a_{ij_0}>0\right\}=\dfrac{x_l}{a_{lj_0}},j_0=\mathrm{argmin}\left\{\left.f (\boldsymbol{x}_{n+1}^j) -f (\boldsymbol{x}_n) =c_j-\sum\limits_{i=1}^mc_ia_{ij}\right| j=m+1,\cdots,n\right\}.
θ=min{aij0xi∣
∣aij0>0}=alj0xl,j0=argmin{f(xn+1j)−f(xn)=cj−i=1∑mciaij∣
∣j=m+1,⋯,n}.
第三部分:终止准则
顶点序列 { x n } \{\boldsymbol{x}_n\} {xn} 的单调递减是容易满足的 , , , 但是 , , , 怎么判断经有限步找到的最终顶点 x N \boldsymbol{x}_{N} xN 是局部最小值呢 ? ? ?
我们以下分情况把所有的 case 都讨论一遍:
- 有唯一解: 直观的想法是
,
,
, 从
x
N
\boldsymbol{x}_{N}
xN 出发
,
,
, 无论替换那个分量
j
j
j 都已经找不到比它函数值更小的顶点了
,
,
, 那么也就是
f ( x n + 1 j ) − f ( x N ) = c j − ∑ i = 1 m c i a i j > 0 , j = 1 , 2 , ⋯ , n . f (\boldsymbol{x}_{n+1}^j)-f (\boldsymbol{x}_N) =c_j-\sum\limits_{i=1}^mc_ia_{ij}> 0,j=1,2,\cdots,n. f(xn+1j)−f(xN)=cj−i=1∑mciaij>0,j=1,2,⋯,n. - 有无穷多解: 从线性规划 1.3.1 的图解例子来看
,
,
, 至少最小值会在一条线段 (一个平面等…) 取到
,
,
, 那么势必会存在至少两个顶点都取到函数最小值
,
,
, 从而
f ( x n + 1 j ) − f ( x n ) = c j − ∑ i = 1 m c i a i j ⩾ 0 且 ∃ j , f ( x n + 1 j ) − f ( x n ) = 0. f (\boldsymbol{x}_{n+1}^j) -f (\boldsymbol{x}_n) =c_j-\sum\limits_{i=1}^mc_ia_{ij}\geqslant 0 \ \text{且} \ \exists\ j,f (\boldsymbol{x}_{n+1}^j) -f (\boldsymbol{x}_n) =0. f(xn+1j)−f(xn)=cj−i=1∑mciaij⩾0 且 ∃ j,f(xn+1j)−f(xn)=0. - 有无界的解: 从线性规划 1.3.1 的图解例子来看
,
,
, 可行域更像是一个无界的"多边形"
,
,
, 我们可以当作存在无穷远处的顶点
,
,
, 并且在无穷远处的一个顶点是能满足单调递减条件的
,
,
, 从而首先会存在一个坐标分量
j
j
j 使得
f
(
x
n
+
1
j
)
−
f
(
x
n
)
=
c
j
−
∑
i
=
1
m
c
i
a
i
j
<
0
f (\boldsymbol{x}_{n+1}^j) -f (\boldsymbol{x}_n) =c_j-\sum\limits_{i=1}^mc_ia_{ij}<0
f(xn+1j)−f(xn)=cj−i=1∑mciaij<0 且沿该坐标分量
j
j
j 去更新顶点
,
,
, 无法找到基可行解
,
,
, 结合命题 1.1.3
,
,
, 即任意
θ
>
0
\theta>0
θ>0 都无法使得
x
n
+
1
j
=
(
x
1
−
θ
a
1
j
,
x
2
−
θ
a
2
j
,
⋯
,
x
m
−
θ
a
m
j
,
0
,
⋯
,
θ
j
,
⋯
,
0
)
\boldsymbol{x}_{n+1}^j= (x_{1}-\theta a_{1j},x_{2}-\theta a_{2j},\cdots,x_{m}-\theta a_{mj},0,\cdots,\mathop{\theta}\limits^{j},\cdots,0)
xn+1j=(x1−θa1j,x2−θa2j,⋯,xm−θamj,0,⋯,θj,⋯,0) 中前
m
m
m 个分量有下降为
0
0
0 的
,
,
, 亦即
x
i
−
θ
a
i
j
>
0
,
i
=
1
,
2
,
⋯
,
m
x_{i}-\theta a_{ij}>0,i=1,2,\cdots,m
xi−θaij>0,i=1,2,⋯,m 对
θ
>
0
\theta>0
θ>0 恒成立
,
,
, 容易推出
a
i
j
<
0
,
i
=
1
,
2
,
⋯
,
m
a_{ij}<0,i=1,2,\cdots,m
aij<0,i=1,2,⋯,m 从而总结为
∃ j , f ( x n + 1 j ) − f ( x n ) = c j − ∑ i = 1 m c i a i j < 0 , a i j < 0 , i = 1 , 2 , ⋯ , m . \exists \ j,f (\boldsymbol{x}_{n+1}^j) -f (\boldsymbol{x}_n) =c_j-\sum\limits_{i=1}^mc_ia_{ij}<0,a_{ij}<0,i=1,2,\cdots,m. ∃ j,f(xn+1j)−f(xn)=cj−i=1∑mciaij<0,aij<0,i=1,2,⋯,m. - 无可行解: 这事实上代表着可行域
D
D
D 是空集
,
,
, 然而在高维的大规模问题面前我们很难在求解前发现
,
,
, 然而我们有另外的一种判别方式: 利用加入的人工变量
s
i
,
s_i,
si, 若已经出现有唯一解的判别准则
f
(
x
n
+
1
j
)
−
f
(
x
n
)
=
c
j
−
∑
i
=
1
m
c
i
a
i
j
>
0
,
j
=
1
,
2
,
⋯
,
n
f (\boldsymbol{x}_{n+1}^j) -f (\boldsymbol{x}_n) =c_j-\sum\limits_{i=1}^mc_ia_{ij}> 0,j=1,2,\cdots,n
f(xn+1j)−f(xn)=cj−i=1∑mciaij>0,j=1,2,⋯,n 但此时有人工变量
s
i
>
0
,
s_i>0,
si>0, 这即借了人工变量还不回去
,
,
, 亦即原问题的找不到可行解
,
,
, 那么无可行解的判别准则即为
f ( x n + 1 j ) − f ( x n ) = c j − ∑ i = 1 m c i a i j > 0 , j = 1 , 2 , ⋯ , n , ∃ s i > 0 , s i 是人工变量 . f (\boldsymbol{x}_{n+1}^j) -f (\boldsymbol{x}_n) =c_j-\sum\limits_{i=1}^mc_ia_{ij}> 0,j=1,2,\cdots,n,\exists \ s_i>0,s_i \ \text{是人工变量}. f(xn+1j)−f(xn)=cj−i=1∑mciaij>0,j=1,2,⋯,n,∃ si>0,si 是人工变量.
注: 值得一提的是 , , , 线性规划问题无可行解是一个特殊但不少见的情况 , , , 因为现实生活中我们也经常会遇到各种要求冲突从而找不到两全其美的解 , , , 对于如何解决这样的现实问题我们会在 Task 3 讨论.
综上 , , , 我们分析清楚了线性规划问题中解的情况并得到了相应的判别准则 , , , 然而还剩下最后一个问题没有解决:
事实上 , , , 优化理论中 , , , 对于大多数的优化问题而言 , , , 局部最小值并非全局最小值 , , , 然而针对一类性质较好的问题: 凸问题——目标函数是凸的 , , , 约束可行域也是凸的 , , , 是满足局部最小值即是全局最小值的 , , , 而线性规划就是最典型的凸问题之一 ! ! !
命题 1.1.6 线性规划问题 2 , 3 {2},{3} 2,3 中 , , , 单纯形法搜索到的局部最小值即是全局最小值.
从上述的讨论中 , , , 我们也发现单纯形法这种下降算法中判断其下降以及终止的标准便是 f ( x n + 1 j ) − f ( x n ) , f(\boldsymbol{x}_{n+1}^j)-f(\boldsymbol{x}_n), f(xn+1j)−f(xn), 我们称其为判别数 , , , 记为 σ j \sigma_j σj.
综上
,
,
, 我们总结出单纯形法的终止准则:


















 2674
2674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}