




 本文介绍了Stacking和Blending两种集成学习方法的基本原理及其应用。Blending通过简化的方式实现模型融合,而Stacking则进一步优化了模型的集成过程,充分利用了数据的多样性。
本文介绍了Stacking和Blending两种集成学习方法的基本原理及其应用。Blending通过简化的方式实现模型融合,而Stacking则进一步优化了模型的集成过程,充分利用了数据的多样性。
Stacking学习记录
Stacking简介
stacking严格来说并不是一种算法,对模型集成的一种策略。可以理解为一个两层的集成,第一层含有多个基础分类器,把预测的结果(元特征)提供给第二层, 而第二层的分类器通常是逻辑回归,他把一层分类器的结果当做特征做拟合输出预测结果。
在介绍Stacking之前,我们先来对简化版的Stacking进行讨论,也叫做Blending,接着我们对Stacking进行更深入的讨论。
Blending集成学习算法
下面我们来详细讨论下这个Blending集成学习方式:
- (1) 将数据划分为训练集和测试集(test_set),其中训练集需要再次划分为训练集(train_set)和验证集(val_set);
- (2) 创建第一层的多个模型,这些模型可以使同质的也可以是异质的;
- (3) 使用train_set训练步骤2中的多个模型,然后用训练好的模型预测val_set和test_set得到val_predict, test_predict1;
- (4) 创建第二层的模型,使用val_predict作为训练集训练第二层的模型;
- (5) 使用第二层训练好的模型对第二层测试集test_predict1进行预测,该结果为整个测试集的结果。
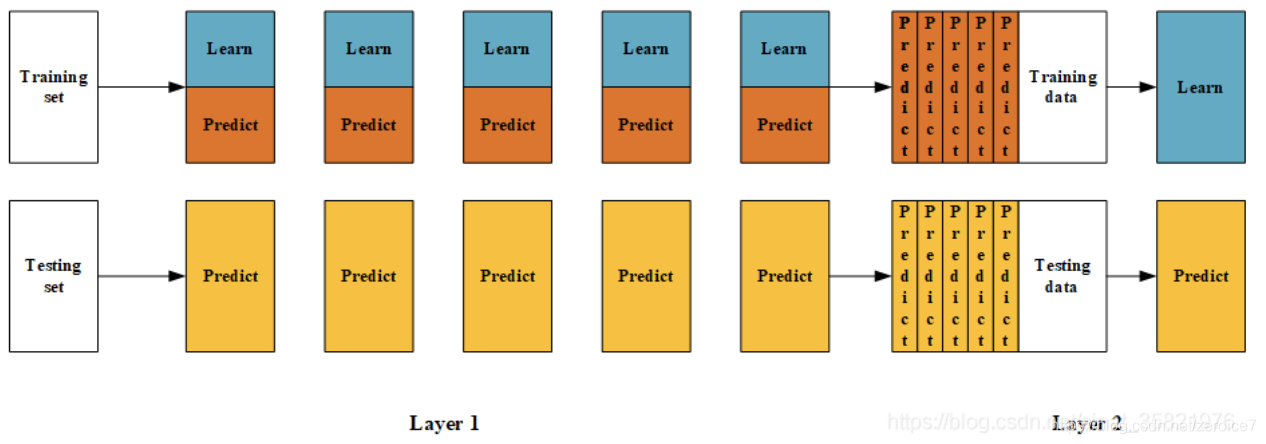
Blending的思想是“Refine”,是机器学习中十分常见的思想,利用模型输出存在差异,融合得到新模型;
在这里,先来梳理下这个过程:
在(1)步中,总的数据集被分成训练集和测试集,如80%训练集和20%测试集,然后在这80%的训练集中再拆分训练集70%和验证集30%,因此拆分后的数据集由三部分组成:训练集80%* 70%、测试集20%、验证集80%* 30% 。训练集是为了训练模型,测试集是为了调整模型(调参),测试集则是为了检验模型的优度。
在(2)-(3)步中,我们使用训练集创建了K个模型,如SVM、random forests、XGBoost等,这个是第一层的模型。 训练好模型后将验证集输入模型进行预测,得到K组不同的输出,我们记作
A
1
,
.
.
.
,
A
K
A_1,...,A_K
A1,...,AK,然后将测试集输入K个模型也得到K组输出,我们记作
B
1
,
.
.
.
,
B
K
B_1,...,B_K
B1,...,BK,其中
A
i
A_i
Ai的样本数与验证集一致,
B
i
B_i
Bi的样本数与测试集一致。如果总的样本数有10000个样本,那么使用5600个样本训练了K个模型,输入验证集2400个样本得到K组2400个样本的结果
A
1
,
.
.
.
,
A
K
A_1,...,A_K
A1,...,AK,输入测试集2000个得到K组2000个样本的结果
B
1
,
.
.
.
,
B
K
B_1,...,B_K
B1,...,BK 。
在(4)步中,我们使用K组2400个样本的验证集结果
A
1
,
.
.
.
,
A
K
A_1,...,A_K
A1,...,AK作为第二层分类器的特征,验证集的2400个标签为因变量,训练第二层分类器,得到2400个样本的输出。
在(5)步中,将输入测试集2000个得到K组2000个样本的结果
B
1
,
.
.
.
,
B
K
B_1,...,B_K
B1,...,BK放入第二层分类器,得到2000个测试集的预测结果。
以上是Blending集成方式的过程,接下来我们来分析这个集成方式的优劣:
其中一个最重要的优点就是实现简单粗暴,没有太多的理论的分析。但是这个方法的缺点也是显然的:blending只使用了一部分数据集作为留出集进行验证,也就是只能用上数据中的一部分,实际上这对数据来说是很奢侈浪费的。
关于这个缺点,我们以后再做改进,我们先来用一些案例来使用这个集成方式。
Stacking集成学习算法
基于前面对Blending集成学习算法的讨论,我们知道:Blending在集成的过程中只会用到验证集的数据,对数据实际上是一个很大的浪费。为了解决这个问题,我们详细分析下Blending到底哪里出现问题并如何改进。在Blending中,我们产生验证集的方式是使用分割的方式,产生一组训练集和一组验证集,这让我们联想到交叉验证的方式。顺着这个思路,我们对Stacking进行建模(如下图):
作业:
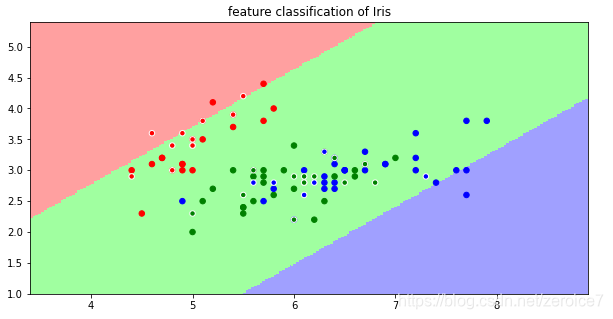
留个小作业,使用Blending方式对iris数据集进行预测,并用第四章的决策边界画出来,找找规律。
数据准备过程:
# Author: Shawn Hoo
# creation date:2021/05/11
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from sklearn import svm
from sklearn import datasets
from sklearn.model_selection import train_test_split
%matplotlib inline
import seaborn as sns
# 处理数据集
iris = datasets.load_iris()
inputdata = datasets.load_iris()
# 切分,测试训练2,8分
x_train, x_test, y_train, y_test = \
train_test_split(inputdata.data, inputdata.target, test_size = 0.2, random_state=0)
X_train,X_val,y_train,y_val = \
train_test_split(x_train, y_train, test_size=0.4, random_state=1)
网络搜索:
- SVM调参
from sklearn.svm import SVC
best_score = 0
for gamma in [1e-5,1e-4,1e-3,0.01,0.1,]:
for C in [1,10,100, 200, 300, 400, 500]:
svm = SVC(gamma=gamma,C=C)#对于每种参数可能的组合,进行一次训练;
svm.fit(X_train,y_train)
score = svm.score(X_val,y_val)
if score > best_score:#找到表现最好的参数
best_score = score
best_parameters = {'gamma':gamma,'C':C}
#### grid search end
print("Best score:{:.2f}".format(best_score))
print("Best parameters:{}".format(best_parameters))
Best score:0.98
Best parameters:{‘gamma’: 0.001, ‘C’: 300}
- 随机森林
from sklearn.ensemble import RandomForestClassifier
best_score = 0
for n_est in [1, 3, 5, 7, 9, 11, 13, 15]:
for max_dep in [1,10,100, 200, 300, 400, 500]:
for min_sample_split in [0.1, 0.3, 0.7, 0.9]:
for min_sample_leaf in [1, 5, 10, 20 ]:
randforst = RandomForestClassifier(n_estimators=n_est,
max_depth=max_dep,
min_samples_split=min_sample_split,
min_samples_leaf=min_sample_leaf)
randforst.fit(X_train,y_train)
score = randforst.score(X_val,y_val)
if score > best_score:#找到表现最好的参数
best_score = score
best_parameters = {'n_estimators':n_est,
'max_depth':max_dep,
'min_samples_split':min_sample_split,
'min_samples_leaf':min_sample_leaf}
#### grid search end
print("Best score:{:.2f}".format(best_score))
print("Best parameters:{}".format(best_parameters))
Best score:0.98
Best parameters:{‘n_estimators’: 3, ‘max_depth’: 200, ‘min_samples_split’: 0.1, ‘min_samples_leaf’: 10}
- Blending融合
# 设置第一层分类器
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
# 第一层分类器
clfs = [SVC(gamma = 0.001, C=300, probability = True),
RandomForestClassifier(n_estimators=3, max_depth=200,
min_samples_split=0.1, min_samples_leaf=10,
n_jobs=-1, criterion='gini')]
# 第二层分类器
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
# 输出第一层的验证集结果与测试集结果
val_features = np.zeros((X_val.shape[0],len(clfs))) # 初始化验证集结果
test_features = np.zeros((x_test.shape[0],len(clfs))) # 初始化测试集结果
clfs_list = []
for i,clf in enumerate(clfs):
clf.fit(X_train,y_train)
val_feature = clf.predict_proba(X_val)[:, 1]
test_feature = clf.predict_proba(x_test)[:,1]
val_features[:,i] = val_feature
test_features[:,i] = test_feature
clfs_list.append(clf)
from sklearn.model_selection import cross_val_score
# 将第一层的验证集的结果输入第二层训练第二层分类器
lr.fit(val_features ,y_val)
# 输出预测的结果
cross_val_score(lr,test_features,y_test,cv=5)
# 首先确定坐标轴范围,通过二维坐标最大最小值来确定范围
# 第n维特征的范围
x1_min = X_train[:, 0].min()
x1_max = X_train[:, 0].max()
x2_min = X_train[:, 1].min()
x2_max = X_train[:, 1].max()
# mgrid方法用来生成网格矩阵形式的图框架
x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j] # 生成网络采样点(其实是颜色区域),先沿着x1向右扩展,再沿着x2向下扩展
grid_test = np.stack((x1.flat, x2.flat), axis=1) # 再通过stack()函数,axis=1,生成测试点,其实就是合并横与纵等于计算x1+x2
grid_value = lr.predict(grid_test) # 用训练好的分类器去预测这一片面积内的所有点,为了画出不同类别区域
grid_value = grid_value.reshape(x1.shape) # (大坑)使刚刚构建的区域与输入的形状相同(裁减掉过多的冗余点,必须写不然会导致越界读取报错,这个点的bug非常难debug)
# 设置两组颜色(高亮色为预测区域,样本点为深色)
light_camp = matplotlib.colors.ListedColormap(['#FFA0A0', '#A0FFA0', '#A0A0FF'])
dark_camp = matplotlib.colors.ListedColormap(['r', 'g', 'b'])
fig = plt.figure(figsize=(10, 5)) # 设置窗体大小
fig.canvas.set_window_title('feature classification of Iris') # 设置窗体title
# 使用pcolormesh()将预测值(区域)显示出来
plt.pcolormesh(x1, x2, grid_value, cmap=light_camp)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, s=30, cmap=dark_camp) # 加入所有样本点,以深色显示
plt.scatter(x_test[:, 0], x_test[:, 1], c=y_test, s=30, edgecolors='white', zorder=2, cmap=dark_camp)
# 单独再把测试集样本点加一个圈,更加直观的查看命中效果
# 设置图表的标题以及x1,x2坐标轴含义
plt.title('feature classification of Iris')
plt.xlabel('length of calyx')
plt.ylabel('width of calyx')
# 设置坐标轴的边界
plt.xlim(x1_min-1, x1_max+1)
plt.ylim(x2_min-1, x2_max+1)
plt.show()
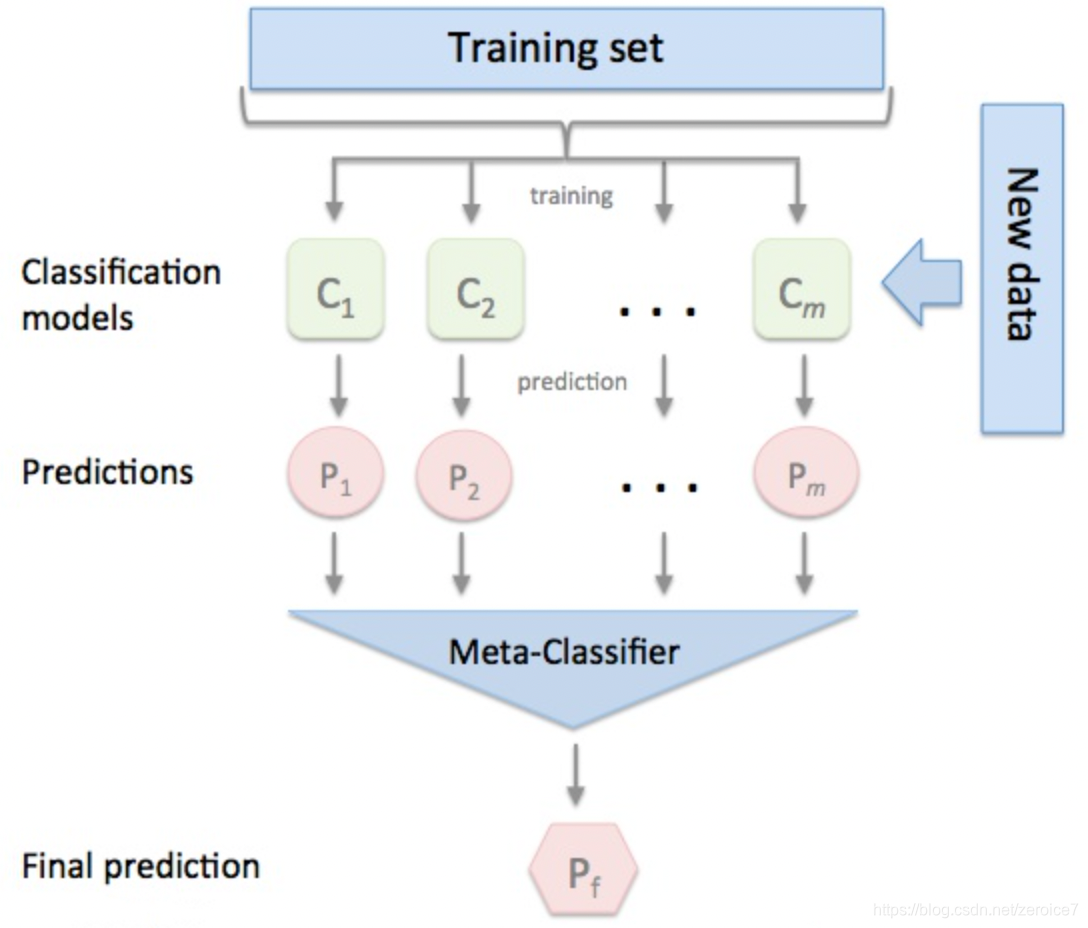
Stacking集成学习算法
Blending与Stacking 共同点与区别
相同:
- 都利用refine(精细化)的思想,在训练集抽出验证集。第一层模型学习训练集,第二层模型学习验证集。
不同: - Blending仅对训练集和验证集进行一次划分,Stacking对训练集和验证集进行多次划分,Stacking充分利用数据的多样性。
Blending的优点在于:
- 比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
Blending的缺点在于: - 使用了很少的数据(是划分hold-out作为测试集,并非cv)
- blender可能会过拟合(其实大概率是第一点导致的)
- stacking使用多次的CV会比较稳
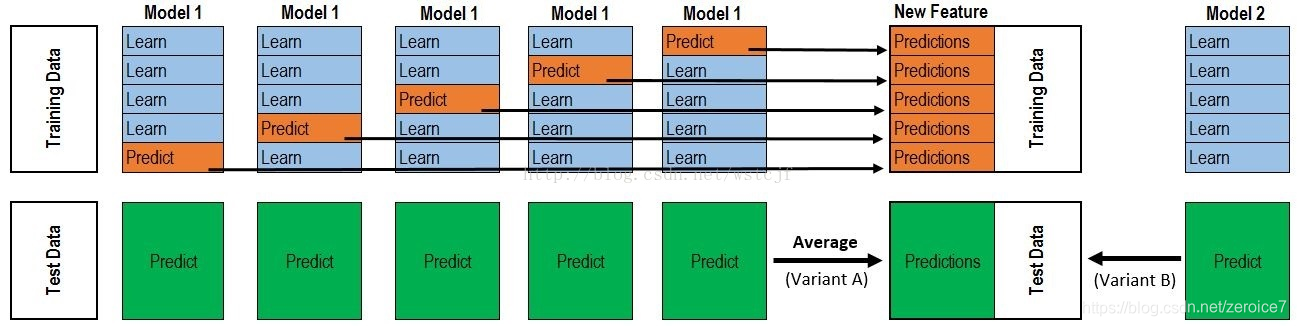
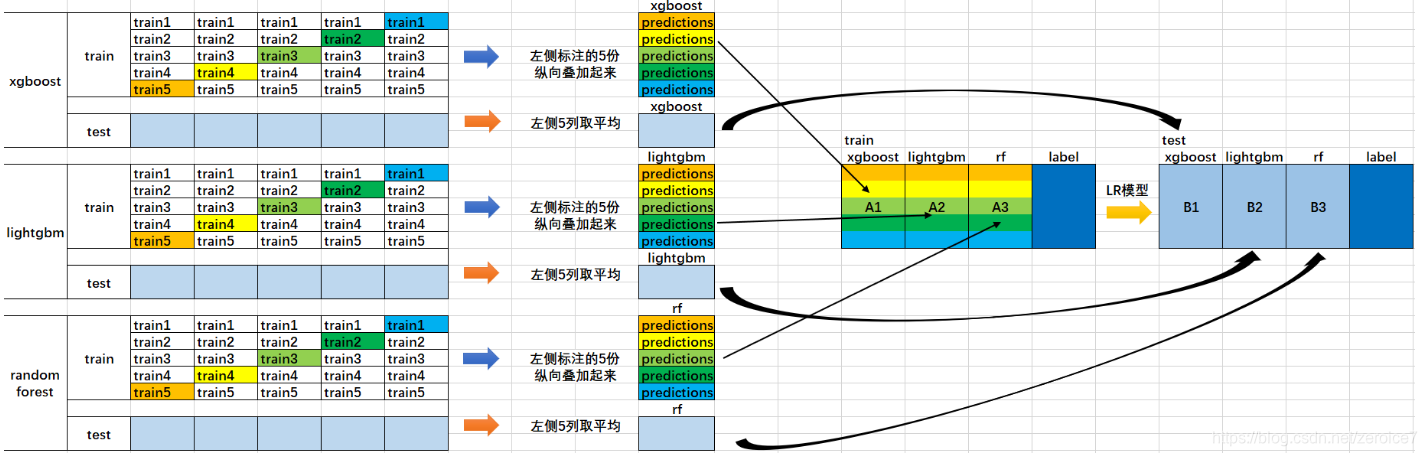
- 首先将所有数据集生成测试集和训练集(假如训练集为10000,测试集为2500行),那么上层会进行5折交叉检验,使用训练集中的8000条作为训练集,剩余2000行作为验证集(橙色)。
- 每次验证相当于使用了蓝色的8000条数据训练出一个模型,使用模型对验证集进行验证得到2000条数据,并对测试集进行预测,得到2500条数据,这样经过5次交叉检验,可以得到中间的橙色的5* 2000条验证集的结果(相当于每条数据的预测结果),5* 2500条测试集的预测结果。
- 接下来会将验证集的5* 2000条预测结果拼接成10000行长的矩阵,标记为 A 1 A_1 A1,而对于5* 2500行的测试集的预测结果进行加权平均,得到一个2500一列的矩阵,标记为 B 1 B_1 B1。
- 上面得到一个基模型在数据集上的预测结果 A 1 A_1 A1、 B 1 B_1 B1,这样当我们对3个基模型进行集成的话,相于得到了 A 1 A_1 A1、 A 2 A_2 A2、 A 3 A_3 A3、 B 1 B_1 B1、 B 2 B_2 B2、 B 3 B_3 B3六个矩阵。
- 之后我们会将 A 1 A_1 A1、 A 2 A_2 A2、 A 3 A_3 A3并列在一起成10000行3列的矩阵作为training data, B 1 B_1 B1、 B 2 B_2 B2、 B 3 B_3 B3合并在一起成2500行3列的矩阵作为testing data,让下层学习器基于这样的数据进行再训练。
- 再训练是基于每个基础模型的预测结果作为特征(三个特征),次学习器会学习训练如果往这样的基学习的预测结果上赋予权重w,来使得最后的预测最为准确。
sklearn没有对应的Stacking算法,需要pip install mlxtend工具包
# 1. 简单堆叠3折CV分类
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier
RANDOM_SEED = 42
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
# Starting from v0.16.0, StackingCVRegressor supports
# `random_state` to get deterministic result.
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3], # 第一层分类器
meta_classifier=lr, # 第二层分类器
random_state=RANDOM_SEED)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf], ['KNN', 'Random Forest', 'Naive Bayes','StackingClassifier']):
scores = cross_val_score(clf, X, y, cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
# 我们画出决策边界
from mlxtend.plotting import plot_decision_regions
import matplotlib.gridspec as gridspec
import itertools
gs = gridspec.GridSpec(2, 2)
fig = plt.figure(figsize=(10,8))
for clf, lab, grd in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingCVClassifier'],
itertools.product([0, 1], repeat=2)):
clf.fit(X, y)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X, y=y, clf=clf)
plt.title(lab)
plt.show()
# 2.使用概率作为元特征
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
use_probas=True, #
meta_classifier=lr,
random_state=42)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores = cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
# 3. 堆叠5折CV分类与网格搜索(结合网格搜索调参优化)
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from mlxtend.classifier import StackingCVClassifier
# Initializing models
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr,
random_state=42)
params = {'kneighborsclassifier__n_neighbors': [1, 5],
'randomforestclassifier__n_estimators': [10, 50],
'meta_classifier__C': [0.1, 10.0]}
grid = GridSearchCV(estimator=sclf,
param_grid=params,
cv=5,
refit=True)
grid.fit(X, y)
cv_keys = ('mean_test_score', 'std_test_score', 'params')
for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r]))
print('Best parameters: %s' % grid.best_params_)
print('Accuracy: %.2f' % grid.best_score_)
# 如果我们打算多次使用回归算法,我们要做的就是在参数网格中添加一个附加的数字后缀,如下所示:
from sklearn.model_selection import GridSearchCV
# Initializing models
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf1, clf2, clf3],
meta_classifier=lr,
random_state=RANDOM_SEED)
params = {'kneighborsclassifier-1__n_neighbors': [1, 5],
'kneighborsclassifier-2__n_neighbors': [1, 5],
'randomforestclassifier__n_estimators': [10, 50],
'meta_classifier__C': [0.1, 10.0]}
grid = GridSearchCV(estimator=sclf,
param_grid=params,
cv=5,
refit=True)
grid.fit(X, y)
cv_keys = ('mean_test_score', 'std_test_score', 'params')
for r, _ in enumerate(grid.cv_results_['mean_test_score']):
print("%0.3f +/- %0.2f %r"
% (grid.cv_results_[cv_keys[0]][r],
grid.cv_results_[cv_keys[1]][r] / 2.0,
grid.cv_results_[cv_keys[2]][r]))
print('Best parameters: %s' % grid.best_params_)
print('Accuracy: %.2f' % grid.best_score_)
# 4.在不同特征子集上运行的分类器的堆叠
##不同的1级分类器可以适合训练数据集中的不同特征子集。以下示例说明了如何使用scikit-learn管道和ColumnSelector:
from sklearn.datasets import load_iris
from mlxtend.classifier import StackingCVClassifier
from mlxtend.feature_selection import ColumnSelector
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
iris = load_iris()
X = iris.data
y = iris.target
pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)), # 选择第0,2列
LogisticRegression())
pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)), # 选择第1,2,3列
LogisticRegression())
sclf = StackingCVClassifier(classifiers=[pipe1, pipe2],
meta_classifier=LogisticRegression(),
random_state=42)
sclf.fit(X, y)
# 5.ROC曲线 decision_function
### 像其他scikit-learn分类器一样,它StackingCVClassifier具有decision_function可用于绘制ROC曲线的方法。
### 请注意,decision_function期望并要求元分类器实现decision_function。
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingCVClassifier
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
iris = datasets.load_iris()
X, y = iris.data[:, [0, 1]], iris.target
# Binarize the output
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
RANDOM_SEED = 42
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=RANDOM_SEED)
clf1 = LogisticRegression()
clf2 = RandomForestClassifier(random_state=RANDOM_SEED)
clf3 = SVC(random_state=RANDOM_SEED)
lr = LogisticRegression()
sclf = StackingCVClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
# Learn to predict each class against the other
classifier = OneVsRestClassifier(sclf)
y_score = classifier.fit(X_train, y_train).decision_function(X_test)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
plt.figure()
lw = 2
plt.plot(fpr[2], tpr[2], color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[2])
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic example')
plt.legend(loc="lower right")
plt.show()

















 1082
1082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









