




该代码示例仅作参考
开发工具 miniconda、python、pycharm
一、爬取时间
2022.12.25 左右
二、需求
1.爬取内容
(1)图片示例
以下图为例:


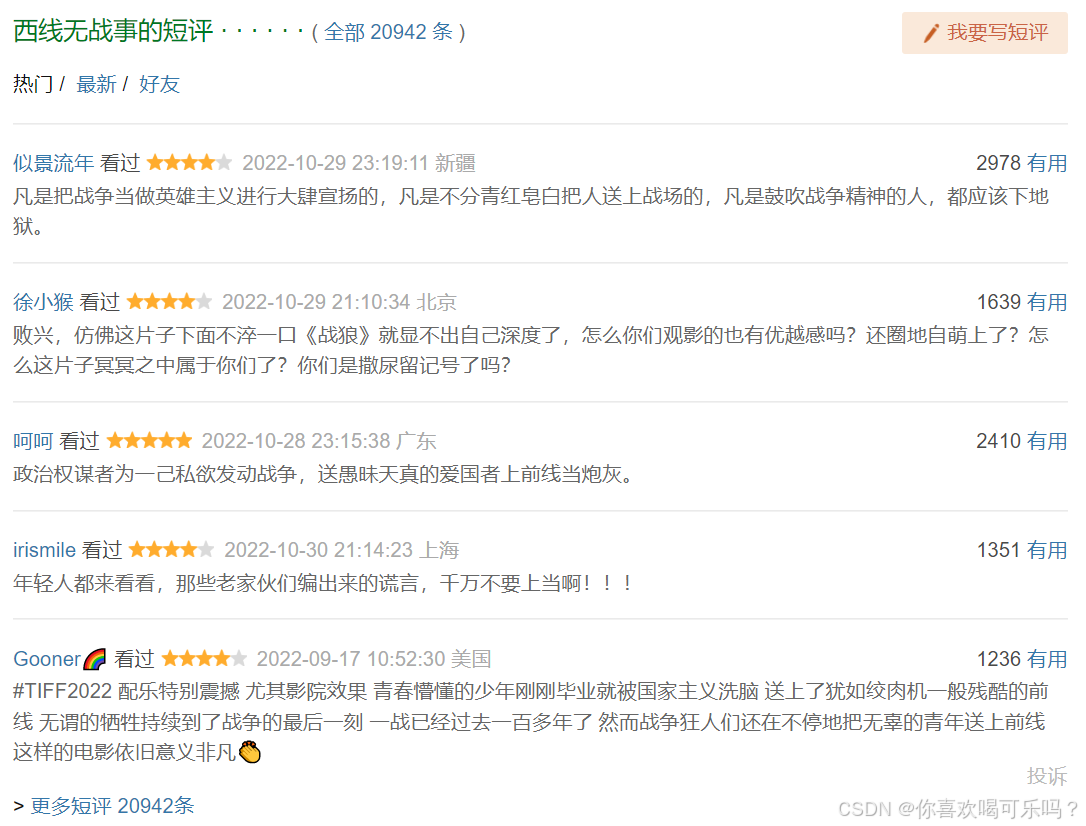
(2)电影基本信息
1、片名
2、导演姓名(如果电影多名导演,都需要)
3、编剧姓名(如果电影多名编剧,都需要)
4、演员(只爬取前6名)
5、类型(爬取电影的所有类型数据)
6、国家和地区(如果有多个,都需要)
7、语言(如果有多个,都需要)
8、上映时间(如果有多个,都需要)
9、片长
(3)豆瓣评分
1、评分
2、星级
3、评价人数
4、每个星级的评价人数百分比(比如五星44.1%......)
(4)喜欢这部电影的人也喜欢
爬取所有相关电影的片名
(5)短评(只爬取短评,不要评论)
1、评价人
2、评价时间(包括年月日时分秒)
3、评价人所在地
4、评价人给出的星级
5、短评内容
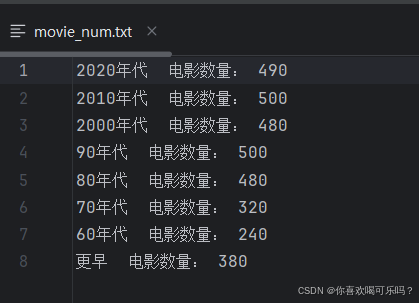
2.爬取数据格式
Json和csv格式的文件
三、问题解决
1.参考学习资料
书:《Python3网络爬虫开发实战》第2版 崔庆才 著
2.解决思路
模拟浏览器浏览过程获取数据
1.爬取电影页面链接;
2.依次爬取每个电影的信息;
3.合并多个文件内容。3.实现代码
4.数据展示
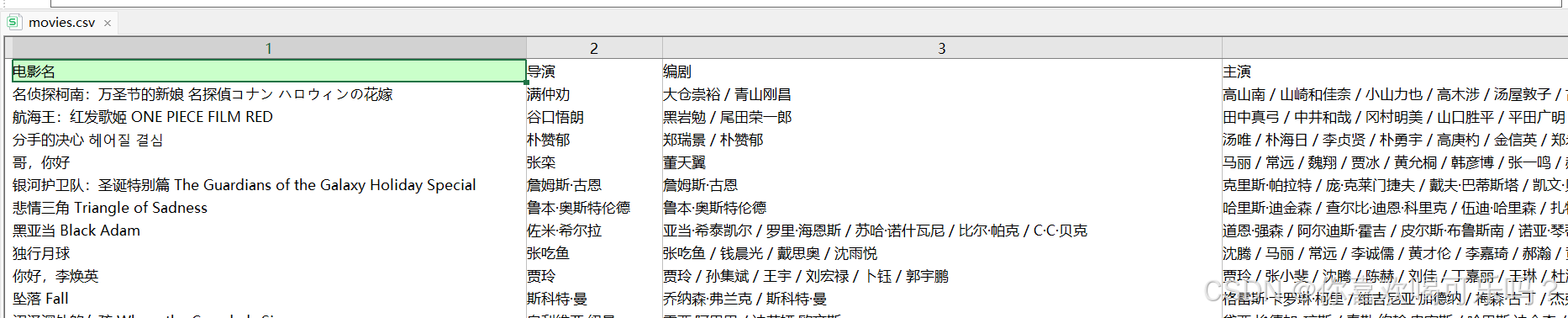
使用 EmEditor 查看 csv 电影数据



















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











