




 HetNet是一种针对镜像检测的新型模型,通过低层次的强度对比(MIC模块)和高层次的反射语义逻辑(RSL模块)实现高效检测。现有的方法在效率和性能之间存在权衡,而HetNet通过异构模块设计,兼顾了两者,尤其适合实时应用。实验表明,HetNet在多种复杂场景中表现出色,验证了其有效性和鲁棒性。
HetNet是一种针对镜像检测的新型模型,通过低层次的强度对比(MIC模块)和高层次的反射语义逻辑(RSL模块)实现高效检测。现有的方法在效率和性能之间存在权衡,而HetNet通过异构模块设计,兼顾了两者,尤其适合实时应用。实验表明,HetNet在多种复杂场景中表现出色,验证了其有效性和鲁棒性。
Efficient Mirror Detection via Multi-level Heterogeneous Learning-论文笔记
论文地址:https://arxiv.org/abs/2211.15644v1
源码地址:https://github.com/Catherine-R-He/HetNet
这篇论文提出的网络模型缩写为:HetNet,全称为多层次异构网络(Multi-level Heterogeneous Network)
是一个高效的检测镜子的模型
目前的镜像检测方法更注重性能而不是效率,限制了实时应用(如无人机上的使用)
效率的不足是由于采用同质模块的设计,忽略了不同层次特征之间的差异
相比之下,HetNet通过low level的检测能力(例如,强度对比)来检测潜在的镜像区域,然后在与high level的检测能力(例如,上下文的不连续)相结合来最终确定预测
为了执行准确而高效的镜像检测,HetNet遵循一种有效的架构,在不同的阶段获取特定的信息来检测镜像
HetNet有两个重要的模块设计:
- 基于多方向强度的对比模块(MIC),在低层级预测潜在的镜子区域
- 反射语义逻辑模块(RSL),在高层级来分析场景中的语义逻辑
镜子的反射可能会导致深度预测出错以及对现实和虚拟性的混淆
这在计算机视觉任务中,如在无人机和机器人导航等情况下导致严重的安全问题
此外,由于计算资源有限,应用程序场景可能在很大程度上依赖于模型的效率,而高效的镜子检测对实时计算机视觉应用程序则至关重要
在以前的研究:
- MirrorNet:contextual contrasted features
- 它们通过多尺度的上下文对比特征来定位镜像
- 如果镜像内容和非镜像内容相似,此方法会有限制
- PMD:content similarity
- 重点研究镜像和非镜像区域特征的关系
- SANet:semantic associations
这些方法在每个阶段都对大空间分辨率的低级特征和小空间分辨率的高级特征应用相同的模块,因此存在巨大的计算成本
此外,它们还严重依赖于后处理算法
如CRF: 这严重限制了这些现有方法对现实世界的场景的使用
CRF:Efficient Inference in Fully Connected CRFs with Gaussian Edge Potentials 2011
salient object detection (SOD) 显著目标检测
- LDF
- CPDNet
这些需要很小的FLOPs,但是性能不够好
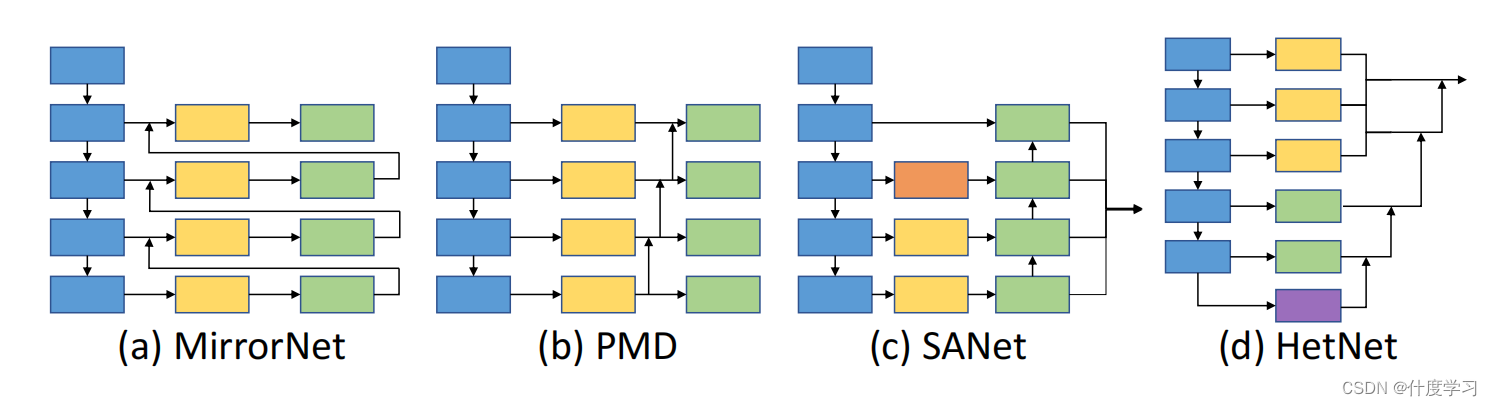
上图是与其他的镜子检测模型的模型结构对比
- 低层级特征包含了颜色、形状和纹理的表示,但学习这些特征需要更高的计算成本,因为它们比高级特征具有更大的空间分辨率
- 高层级特征涉及更多的语义信息,由于高级特征只包含粗糙的空间信息,因此模型更难以直接提取精确的镜像边界
低水平和高水平的理解都有助于镜像检测
由于低级特征和高级特征之间的表示差距,在模型设计中,这两种特征都不宜采用相同的模块
HetNet充分利用主干网络来更好地学习底层特征,而不需要花费巨大的计算成本
利用对低级和高级特征的解纠缠学习,模型有效地、高效地利用了低级和高级特征
Related Works
Salient Object Detection
它能检测到图像中最突出的物体
早期的方法主要是基于低层次的特征,如color, contrast,spectral residual
Shadow Detection
它可以识别或删除图像中的阴影区域
Methodology
HetNet是基于两个观察结果
人类很容易被吸引到具有显著的低级特征(如强度对比)的区域,然后关注高级信息(如内容相似性、上下文对比)来检查物体细节以检测镜像。
这些观察结果促使我们在浅层阶段学习低级特征,并在具有异构模块的深层阶段提取高级特征
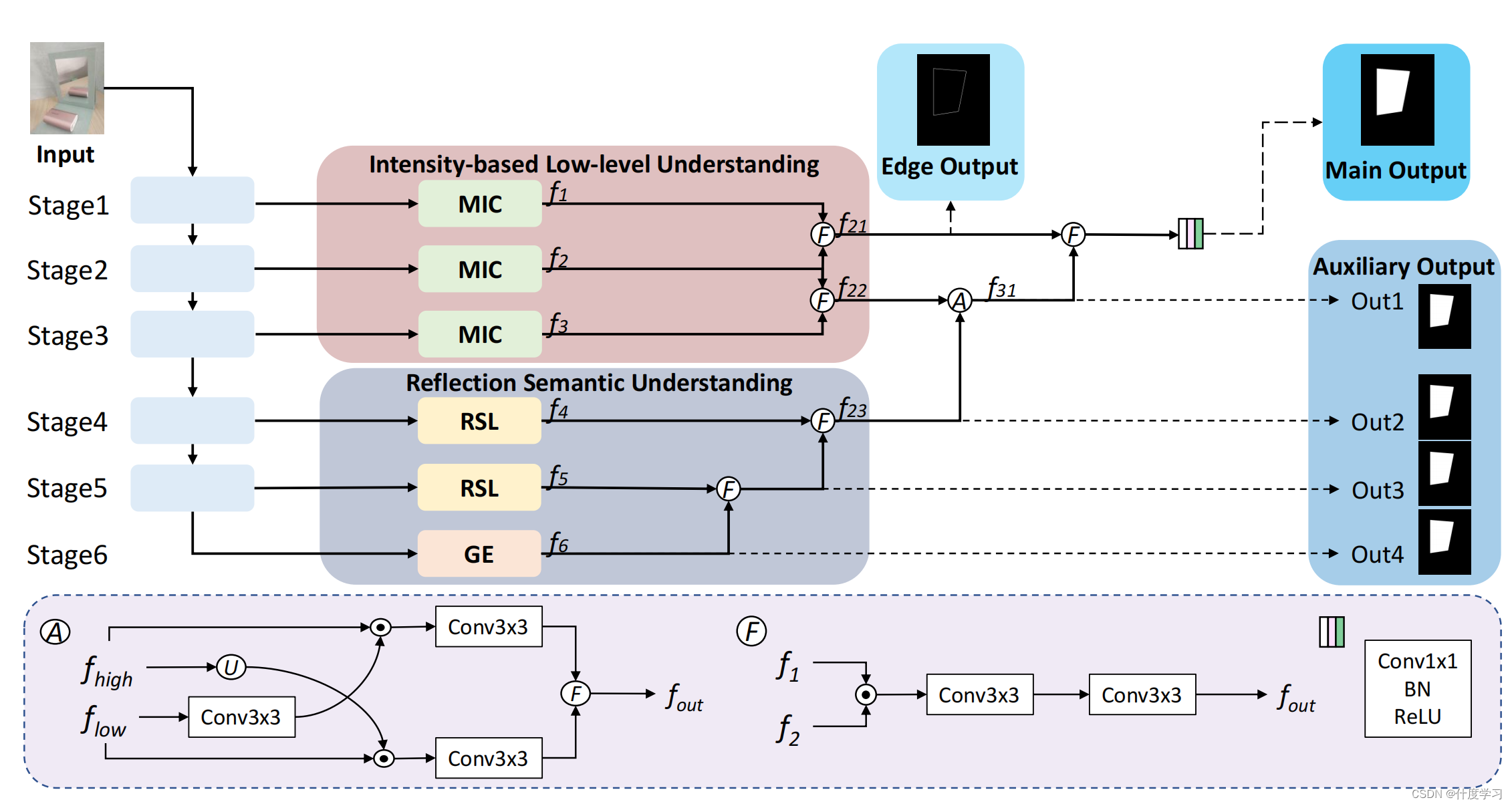
上图是HetNet的结构示意图
从骨干网络中获得多尺度图像特征后
前三个阶段使用了基于多方向强度的对比(MIC)模块,后三个阶段使用了反射语义逻辑(RSL)模块和全局提取器(GE),全局提取器(GE)根据金字塔池化模块提取多尺度图像特征
基于学习强度的低水平理解,然后将f1和f2、f2和f3分别融合到f21、f22中
为了整合反射语义理解,我们首先将f6与f5融合,然后与f4融合,生成f23
最后,将f23与f22聚合到f31后,输出的特征图是f31和f21的融合
融合策略是乘法和两个3×3卷积层,其中低级特征流和高级特征流融合成交叉聚合策略
(图中的融合操作(A)可能是来自于 Coordinate Attention for Efficient Mobile Network Design, CVPR21,由代码注释中)
The MIC Module
multi-orientation intensity-based contrasted 多方向强度对比
只学习语境信息是不够的,特别是在语境信息有限或复杂的情况下
因此,利用一个额外的强提示来促进镜像检测是必要的
大多数人先看整个场景,然后注意场景中的各个元素
此外,整体并不等于单个元素的总和
相反,它考虑了这些元素的关联程度(例如,形状、位置、大小、颜色)
基于此,我们认为从不同的方向观察同一场景可以获得不同的信息
我们使用ICFEs(基于强度的对比特征提取器)学习特征
ICFE的全程为Intensity-based Contrasted Feature Extractor
增强的对比信息是通过结合来自两个单一方向的信息来获得的
考虑到镜像和非镜像区域之间的低层级对比,我们首先设计了一个MIC模块,聚焦于双方向的低层级对比来定位可能的镜像区域
此外,为了降低计算成本,icfe将输入特征作为两个方向的两个平行一维特征分别处理
一个MIC模块由两个基于强度的对比特征提取器(ICFE)模块组成
我们首先提取了一个方向的对比度特征
逆时针旋转90度后,在另一个方向提取对比度特征
f 1 l o w = I C F E ( f in low ) , f 2 low = I C F E ( Rot ( f in low , 1 ) ) f 3 l o w = f 1 l o w ⊙ Rot ( f 2 l o w , − 1 ) f out l o w = B C o n v 1 × 1 ( B C o n v 3 × 3 ( f 3 l o w ) ) \begin{aligned} & f_1^{l o w}=\mathbf{I C F E}\left(f_{\text {in }}^{\text {low }}\right), \quad f_2^{\text {low }}=\mathbf{I C F E}\left(\operatorname{Rot}\left(f_{\text {in }}^{\text {low }}, 1\right)\right) \\ & f_3^{l o w}=f_1^{l o w} \odot \operatorname{Rot}\left(f_2^{l o w},-1\right) \\ & f_{\text {out }}^{l o w}=\mathbf{B C o n v}_{1 \times 1}\left(\mathbf{B C o n v}_{3 \times 3}\left(f_3^{l o w}\right)\right) \end{aligned} f1low=ICFE(fin low ),f2low =ICFE(Rot(fin low ,1))f3low=f1low⊙Rot(f2low,−1)fout low=BConv1×1(BConv3×3(f3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3220
3220




 到【灌水乐园】发言
到【灌水乐园】发言







