




 本文介绍了一种用于有向概率模型的高效近似后验推断方法——Auto-Encoding VB(AEVB),该方法利用SGVB估计器,能够直接通过随机梯度上升技术进行优化。AEVB算法在独立同分布数据和连续隐变量的情况下表现出优秀的预测和学习能力。
本文介绍了一种用于有向概率模型的高效近似后验推断方法——Auto-Encoding VB(AEVB),该方法利用SGVB估计器,能够直接通过随机梯度上升技术进行优化。AEVB算法在独立同分布数据和连续隐变量的情况下表现出优秀的预测和学习能力。
1 简介
本文根据2014年《Auto-Encoding Variational Bayes》翻译总结的。引入了Stochastic Gradient VB
(SGVB)方法,对variational lower bound进行估计,对连续隐变量的有效近似推断。进而提出了使用SGVB估计器的Auto-Encoding VB(AEVB)。
当有向概率模型的连续隐变量或参数有难以处理的后验分布时,我们如何利用有向概率模型进行有效的近似推理和学习?variational Bayesian (VB)方法包含对难以处理的后验分布的最佳近似。不幸的是,普通平均场方法需要近似后验期望值的解析解,这在一般情况下也是难以解决的。我们显示了可变下界的重新参数化,可变下界是对下界的一个简单的可微分的无偏估计。这种SGVB (Stochastic Gradient Variational Bayes)估计用来可以在几乎任何带着联系隐变量的模型中进行有效的近似后验推断,可以直接使用标准的随机梯度上升技术进行优化。
对于独立同分布数据和每个数据点是连续隐变量的情况,我们提出了Auto-Encoding VB (AEVB) 算法。在AEVB算法中,我们依靠使用SGVB估计可以有效进行预测和学习,进而优化一个生成模型,其容许我们使用简单的原始采样进行非常有效的近似后验推断,交替容许我们有效学习模型参数,不需要在每个数据点有昂贵的重复的预测计划(如MCMC)。这种近似后验推断模型可以用来进行识别、去噪、表示、可视化等目的。当一个模型用来进行生成模型时,我们就称为variational auto-encoder.
2 相关工作
wake-sleep算法是我们算法之前另一种文本在线学习方法,其应用于连续隐变量。wake-sleep算法也适用于离散隐变量,其和AEVB是相同的计算复杂度。
AEVB显示了有向概率模型和auto-encoders的联系。
DARN也使用一个auto-encoding 架构来学习有向概率模型,但是他们的模型应用于二值隐变量。
3 方法
我们使用maximum likelihood (ML)或maximum a posteriori (MAP)在(全局)参数上,variational 推断在隐变量上。我们的方法可以应用于在线、非平稳设置、流数据,但这里我们为了简单假定一个固定的数据集。
3.1 问题场景

在上面场景涉及3个相关问题:
关于参数θ的有效近似ML或者MAP估计。
对于参数θ,在给定x下,可以对隐变量z进行有效的近似后验推断。
对变量x的有效的近似边际推断。

3.2 variational bound变分界
先列两个公式,其中下式右边部分L是variational lower bound。
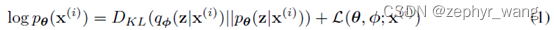
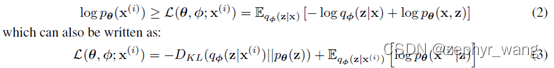
3.3 SGVB estimator and AEVB algorithm
本节我们引入variational lower bound的一个实际估计和他的衍生。

Auto-Encoding VB (AEVB)算法如下:

3.4 重参数技巧
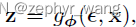
4 Variational Auto-Encoder

5 实验
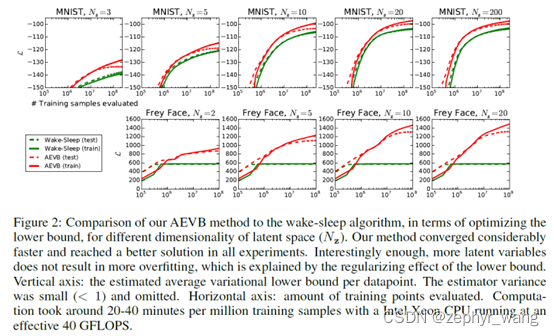
AEVB和wake-sleep算法相比,收敛更快效果更好。

















 1187
1187

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









