



Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。
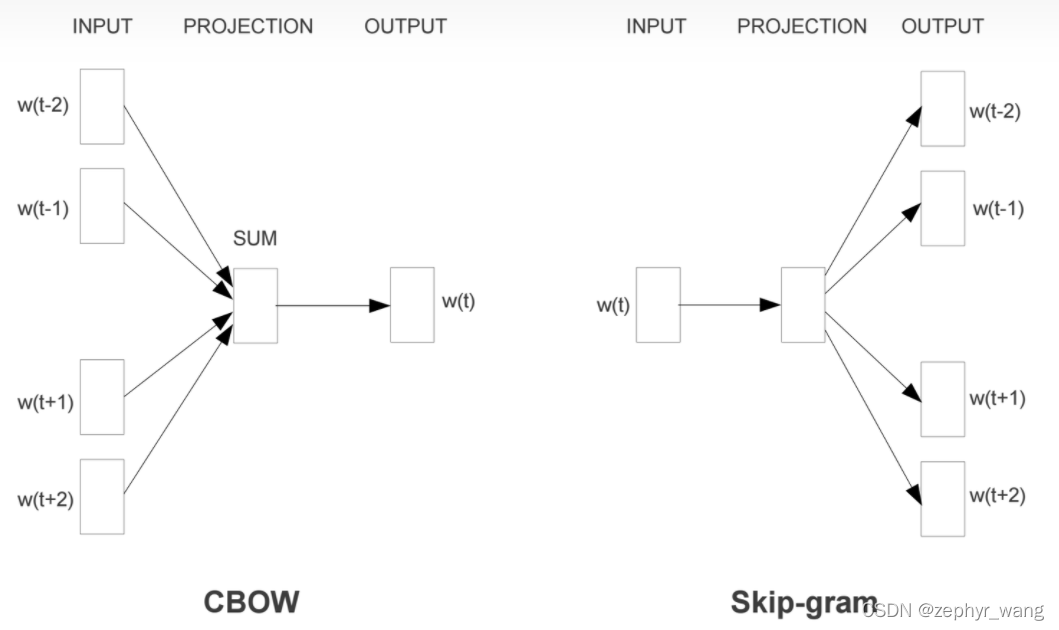
skip-gram的核心
通过查看所有语料的词作为中心词时,其(中心词)与上下文的2m个词语的所有共现情况,这样就得到我们要逼近的中心词与上下文对应关系的条件概率分布(这个概率分布是忽视掉了上下文词语间的顺序的),我们通过模型去训练出词典中心词向量矩阵和词典上下文词向量矩阵(这两个矩阵就是存储了语料中中心词与其上下文的对应关系信息)。
模型
Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量
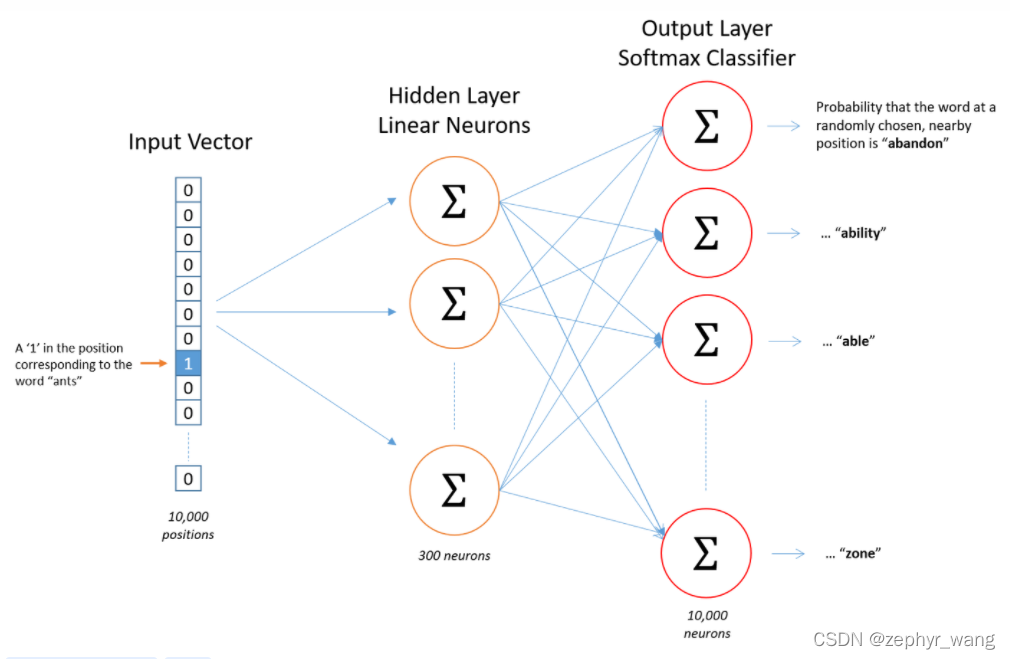
输入向量:代表某个单词的one-hot编码
输出:Softmax归一化后输出的概率向量。就是词典中每个词成为当前指定中心词的上下文的概率。我们要让这个概率向量,逼近真实语料中基于指定中心词基础上这些上下文词语出现的条件概率分布。
Skip-gram每一轮指定一个中心词的2m个上下文词语来训练该中心词词向量和词典上下文词向量,下一轮则指定语料中下一个中心词


















 1809
1809

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











