






 ELECTRA是一种改进的预训练模型,它通过训练一个生成器和一个识别器来提高效率。与BERT的Masked Language Modeling (MLM)不同,ELECTRA使用Replaced Token Detection任务,生成器尝试替换tokens,而识别器则学习区分真实tokens和生成的tokens。这种方法避免了预训练和微调之间的不匹配,并且在计算效率和性能上优于BERT。在各种模型大小和实验中,ELECTRA都表现出色,尤其是在大型模型上,且能有效利用所有tokens进行训练。
ELECTRA是一种改进的预训练模型,它通过训练一个生成器和一个识别器来提高效率。与BERT的Masked Language Modeling (MLM)不同,ELECTRA使用Replaced Token Detection任务,生成器尝试替换tokens,而识别器则学习区分真实tokens和生成的tokens。这种方法避免了预训练和微调之间的不匹配,并且在计算效率和性能上优于BERT。在各种模型大小和实验中,ELECTRA都表现出色,尤其是在大型模型上,且能有效利用所有tokens进行训练。
1 简介
ELECTRA:Efficiently Learning an Encoder that Classifies Token Replacements Accurately.
本文根据2020年《ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS》翻译总结。根据标题可以知道ELECTRA更关注识别,而不是生成;像BERT这种其实是生成,从mask的输入预测原始输入。
BERT中的MLM预训练方法,需要大量的计算。为此,我们提出一种更加有效的预训练方法,即replaced token detection。不是采用BERT中那种mask输入的方法,而是用一个生成网络中采样的近似token来替换。接着,不是像BERT从破坏掉(mask掉)的输入中恢复原输入,而是训练一个识别器来预测每个token是否被生成网络替换过。通过实验发现,我们这种方法比MLM方法更加有效率,因为我们的任务是定义在所有的token上,而不是仅仅mask掉的那部分token。ELECTRA比BERT训练快很多。
BERT 中存在预训练和下游任务不匹配的现象,即mask在预训练中存在,而在fine-tuned中不存在。而我们是采用MLM训练一个生成器(generator),也是从损害的输入中预测原始输入。然后再识别器识别(discriminative)。
虽然我们的方法让人想起GAN,但是我们的方法不是对抗训练(对抗训练:生成器是产生损害的输入)。
我们没有将识别器的损失反向传播给生成器,事实上,我们也做不到,因为采样的缘故。
在预训练后,我们会丢弃生成器,只是微调识别器到下游任务。
2 具体方法
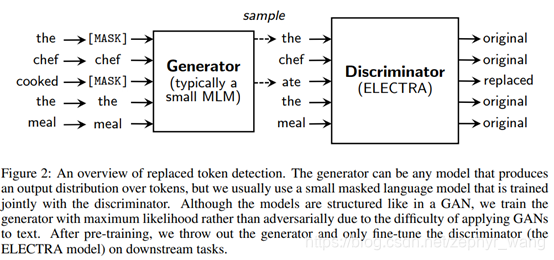
如上图,我们的方法训练两个神经网络,一个是生成器(generator)G,一个是识别器(discriminator)D。生成器使用MLM模型,从mask的输入预测原始的输入。识别器然后训练哪些token是被生成器替换的。

2.1 损失函数

我们的生成器和对抗训练不一样,是因为(1)我们的生成器是尽可能生成正确的token,而不是来像对抗训练那样来愚弄识别器。(2)我们不是将生成器作为一个噪声输入。
最终损失函数如下:
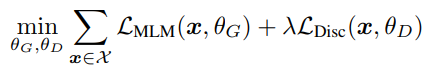
我们没有将识别器的损失反向传播给生成器,事实上,我们也做不到,因为采样的缘故。
在预训练后,我们会丢弃生成器,只是微调识别器到下游任务。
3 实验
3.1模型扩展
1)权重共享:我们将识别器和生成器的embedding进行参数共享。
2)小的生成器:如果生成器和识别器采用相同的大小,那么ELECTRA对比MLM模型将是两倍的计算量。我们发现采用小的生成器可以减少这个影响,发现生成器是识别器的1/4到1/2大小最好。
3)训练算法:我们是一起联合训练生成器和识别器,不是分两步训练
3.2 小模型结果
ELECTRA好于BERT。FLOPS:全称是floating point operations per second.

3.3 大模型结果
ELECTRA在大模型上效果也很好,如果训练时间更长,效果更好,如ELECTRA-1.75M。
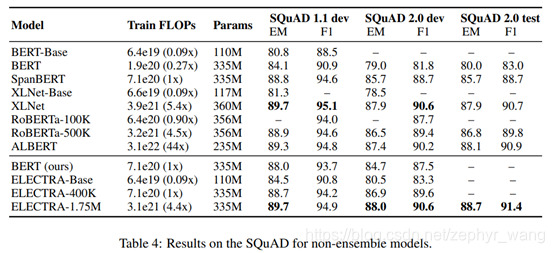
3.4 有效性分析


从上表可以看出来ELECTRA从all token中获益良多,以及避免出现预训练和fine-tune之间因有没有mask出现的不匹配而获得少量的收获(Replace MLM与BERT比较)。BERT在避免及避免预训练和fine-tune之间不匹配,已经采用了10%token采用随机token替换和另一部分token保持不变,但这不足以完全避免不匹配。

















 2399
2399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









