






 HCP模型,基于BING和CNN,实现从单标签到多标签的图片分类,无需ground-truthboundingbox,对噪声健壮,输出多标签预测结果。模型通过Hypothesis-CNN-Pooling方法,结合cross-hypothesismax-pooling,提高预测准确性。
HCP模型,基于BING和CNN,实现从单标签到多标签的图片分类,无需ground-truthboundingbox,对噪声健壮,输出多标签预测结果。模型通过Hypothesis-CNN-Pooling方法,结合cross-hypothesismax-pooling,提高预测准确性。
1 简介
参考2014年论文《CNN: Single-label to Multi-label》,该论文中提出了HCP(hypothesis-CNN-Pooling)。HCP可以进行一张图片中多物体(多标签)的识别。Hypothesis基本可以理解为物体建议(object proposal)。
先介绍个模型BING(binarized normed gradients 二值化标准梯度)。对于物体的识别,比如RPN模型,其检测效果依赖于大量的ground-truth 标注,这样就导致RPN的检测效果不具有一般性,即训练过的物体可以识别,换一种其他物体就很难识别。而BING就尝试提出一种具有一般性的物体建议(object proposal)检测方法,其采用normed gradients作为特征。
从单标签图片分类到多标签图片分类,标签的空间就会从n扩展到2的n次方,所以需要更多的训练数据。同时多标签图片数据的收集与标注也需要庞大的工作量。所以HCP采用了BING。
2 模型特点
- 不需要ground-truth bound ing box。和BING有关吧
- HCP对噪声是健壮的。
- HCP不需要明确的hypothesis 标签。和BING有关吧
- shared CNN可以预训练。采用imageNet(单独标签的)。
- HCP的输出本质上是多标签预测结果。
3 模型架构
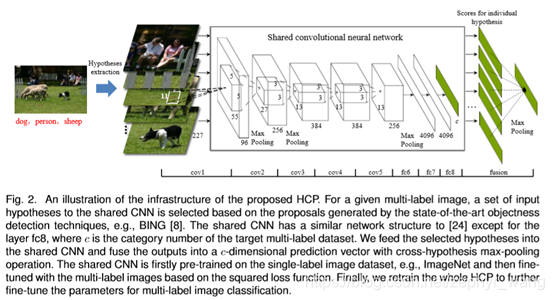
(1) BING提取了一些物体的proposal,然后采用HS(hypothesis selection)方法从这些proposal中选择出一些hypothesis。
(2) 上面的hypothesis输入到shared CNN网络。该网络采用imageNet(单独标签的)数据进行了预训练。对于每个hypothesis,输出一个c维的预测结果。
(3) 微调参数,针对多标签数据进行训练。采用cross-hypothesis max-pooling 产生最终的预测结果。
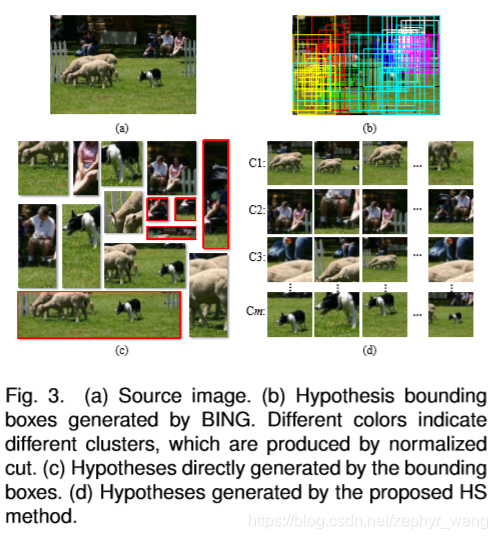
3.1 HS 方法
如下图所示。有m个群组,在每个群组中,会根据BING的预测得分,取前k个hypothesis。所以共有m*k个hypothesis。
3.2 HCP的初始化
Shared CNN预训练后,主要是最后一层进行了调整,因为预训练的分类数量可能和HCP实际使用的分类数量不一致。这个调整过程起名 image-fine-tuning (I-FT)。I-FT采用的平方损失函数。

image-fine-tuning (I-FT)损失函数:

3.3 Hypothesis fine tuning
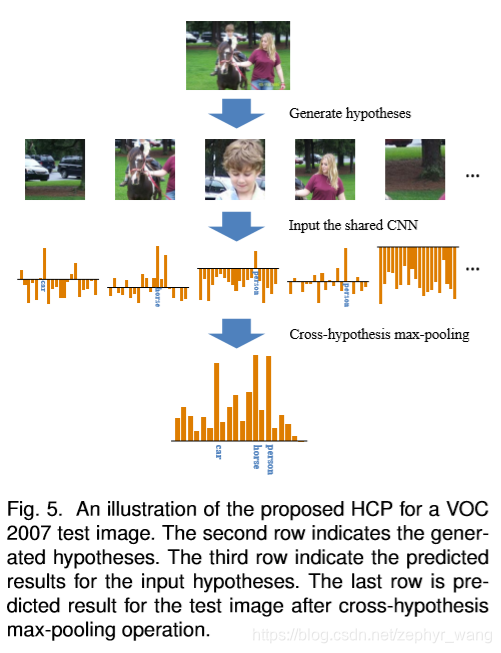
Hypothesis fine tuning简称H-FT。主要是cross-hypothesis max-pooling方法。如下图,将每个hypothesis的预测结果结合在一起,同时消除了噪声的干扰。

4 实验结果
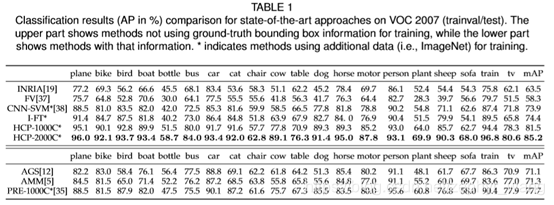
4.1 物体分类结果
HCP效果较好。
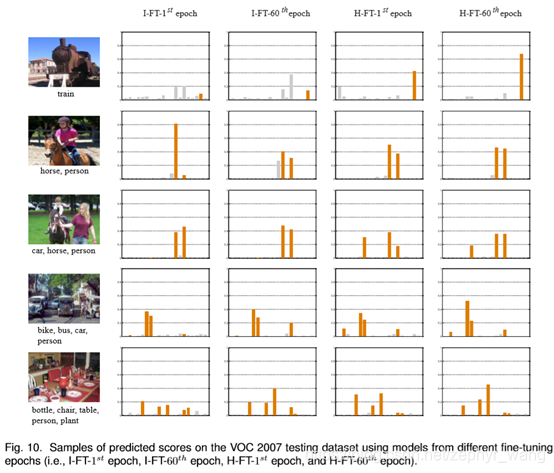
4.2 I-FT与H-FT
如下图橙色柱子(代表预测的分数),可以看到经过I-FT、H-FT效果越来越好。在第3行图中,背景中的汽车开始在I-FT中没有,但是在H-FT恢复出来了。

















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









